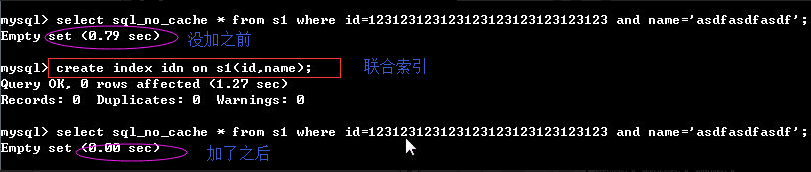
6. 最左前缀匹配
index(id,age,email,name)
#条件中一定要出现id(只要出现id就会提升速度)
id
id age
id email
id name
email #不行 如果单独这个开头就不能提升速度了
mysql> select count(*) from s1 where id=3000;
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.11 sec)
mysql> create index xxx on s1(id,name,age,email);
Query OK, 0 rows affected (6.44 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select count(*) from s1 where id=3000;
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from s1 where name='egon';
+----------+
| count(*) |
+----------+
| 299999 |
+----------+
1 row in set (0.16 sec)
mysql> select count(*) from s1 where email='egon3333@oldboy.com';
+------