台部署数据库,一台部署NFS文件系统。
这是前几年比较传统的做法,之前见到一个网站10万多会员,垂直服装设计门户,N多图片。使用了一台服务器部署了应用,数据库以及图片存储。出现了很多性能问题。
如下图:
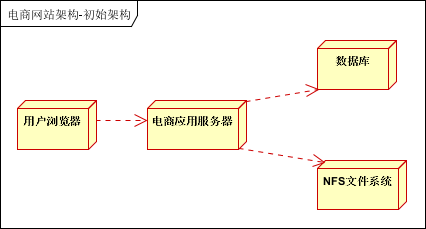
但是,目前主流的网站架构已经发生了翻天覆地的变化。一般都会采用集群的方式,进行高可用设计。至少是下面这个样子:
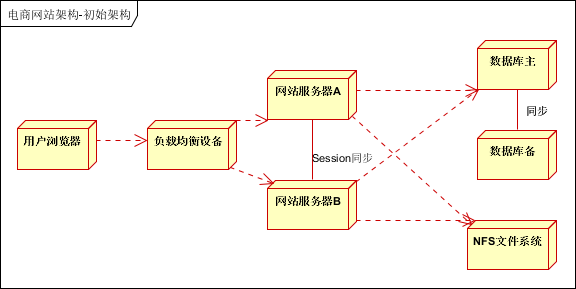
- 使用集群对应用服务器进行冗余,实现高可用;(负载均衡设备可与应用一块部署)
- 使用数据库主备模式,实现数据备份和高可用;
4、系统容量预估
预估步骤:
- 注册用户数-日均UV量-每日的PV量-每天的并发量;
- 峰值预估:平常量的2~3倍;
- 根据并发量(并发,事务数),存储容量计算系统容量。
根据客户需求:3~5年用户数达到1000万注册用户,可以做每秒并发数预估:
- 每天的UV为200万(二八原则);
- 每日每天点击浏览30次;
- PV量:200*30=6000万;
- 集中访问量:24*0.2=4.8小时会有6000万*0.8=4800万(二八原则);
- 每分并发量:4.8*60=288分钟,每分钟访问4800/288=16.7万(约等于);
- 每秒并发量:16.7万/60=2780(约等于);
- 假设:高峰期为平常值的三倍,则每秒的并发数可以达到8340次。
- 1毫秒=1.3次访问;
没好好学数学后悔了吧?!(不知道以上算是否有错误,呵呵~~)
服务器预估:(以tomcat服务器举例)
按一台web服务器,支持每秒300个并发计算。平常需要10台服务器(约等于);[tomcat默认配置是150],高峰期需要30台服务器;
容量预估:70/90原则
系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的。内存,IO类似。
以上预估仅供参考,因为服务器配置,业务逻辑复杂度等都有影响。在此CPU,硬盘,网络等不再进行评估。
5、网站架构分析
根据以上预估,有几个问题:
- 需要部署大量的服务器,高峰期计算,可能要部署30台Web服务器。并且这三十台服务器,只有秒杀,活动时才会用到,存在大量的浪费。
- 所有的应用部署在同一台服务器,应用之间耦合严重。需要进行垂直切分和水平切分。
- 大量应用存在冗余代码
- 服务器Session同步耗费大量内存和网络带宽
- 数据需要频繁访问数据库,数据库访问压力巨大。
大型网站一般需要做以下架构优化(优化是架构设计时,就要考虑的,一般从架构/代码级别解决,调优主要是简单参数的调整,比如JVM调优;如果调优涉及大量代码改造,就不是调优了,属于重构):
- 业务拆分
- 应用集群部署(分布式部署,集群部署和负载均衡)
- 多级缓存
- 单点登录(分布式Session)
- 数据库集群(读写分离,分库分表)
- 服务化
- 消息队列
- 其他技术
6、网站架构优化
6.1业务拆分
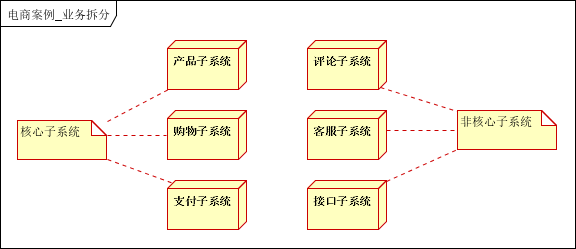
根据业务属性进行垂直切分,划分为产品子系统,购物子系统,支付子系统,评论子系统,客服子系统,接口子系统(对接如进销存,短信等外部系统)。
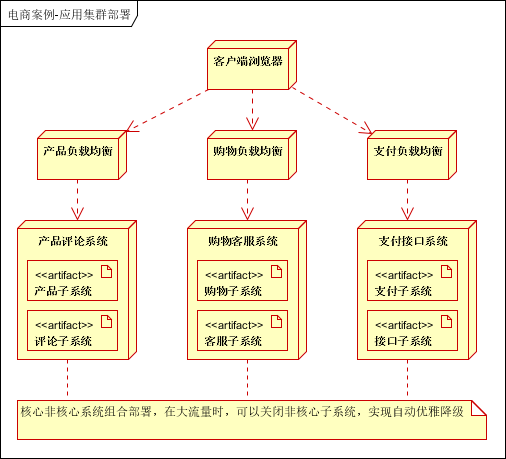
根据业务子系统进行等级定义,可分为核心系统和非核心系统。核心系统:产品子系统,购物子系统,支付子系统;非核心:评论子系统,客服子系统,接口子系统。
- 业务拆分作用:提升为子系统可由专门的团队和部门负责,专业的人做专业的事,解决模块之间耦合以及扩展性问题;每个子系统单独部署,避免集中部署导致一个应用挂了,全部应用不可用的问题。
- 等级定义作用:用于流量突发时,对关键应用进行保护,实现优雅降级;保护关键应用不受到影响。
拆分后的架构图:
参考部署方案2
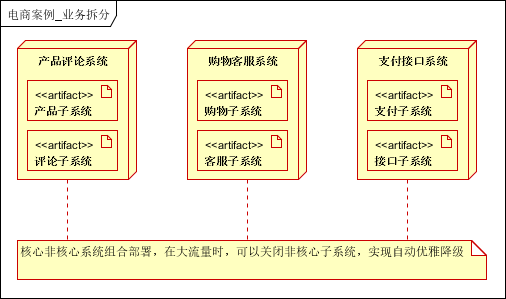
如上图每个应用单独部署,核心系统和非核心系统组合部署
6.2应用集群部署(分布式,集群,负载均衡)
- 分布式部署:将业务拆分后的应用单独部署,应用直接通过RPC进行远程通信;
- 集群部署:电商网站的高可用要求,每个应用至少部署两台服务器进行集群部署;
- 负载均衡:是高可用系统必须的,一般应用通过负载均衡实现高可用,分布式服务通过内置的负载均衡实现高可用,关系型数据库通过主备方式实现高可用。
集群部署后架构图:
6.3 多级缓存
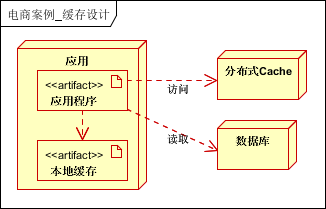
缓存按照存放的位置一般可分为两类本地缓存和分布式缓存。本案例采用二级缓存的方式,进行缓存的设计。一级缓存为本地缓存,二级缓存为分布式缓存。(还有页面缓存,片段缓存等,那是更细粒度的划分)
一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存。当一级缓存过期或不可用时,访问二级缓存的数据。如果二级缓存也没有,则访问数据库。
缓存的比例,一般1:4,即可考虑使用缓存。(理论上是1:2即可)。
根据业务特性可使用以下缓存过期策略:
6.4单点登录(分布式Session)
系统分割为多个子系统,独立部署后,不可避免的会遇到会话管理的问题。一般可采用Session同步,Cookies,分布式Session方式。电商网站一般采用分布式Session实现。
再进一步可以根据分布式Session,建立完善的单点登录或账户管理系统。
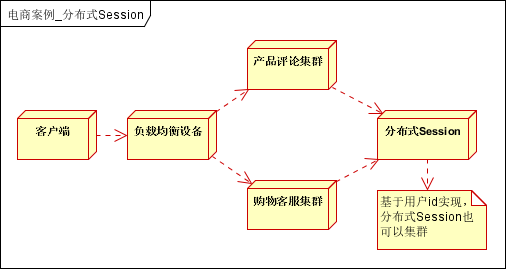
流程说明
- 用户第一次登录时,将会话信息(用户Id和用户信息),比如以用户Id为Key,写入分布式Session;
- 用户再次登录时,获取分布式Session,是否有会话信息,如果没有则调到登录页;
- 一般采用Cache中间件实现,建议使用Redis,因此它有持久化功能,方便分布式Session宕机后,可以从持久化存储中加载会话信息;
- 存入会话时,可以设置会话保持的时间,比如15分钟,超过后自动超时;
结合Cache中间件,实现的分布式Session,可以很好的模拟Session会话。
6.5数据库集群(读写分离,分库分表)
大型网站需要存储海量的数据,为达到海量数据存储,高可用,高性能一般采用冗余的方式进行系统设计。一般有两种方式读写分离和分库分表。
读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
本案例在业务拆分的基础上,结合分库分表和读写分离。如下图:
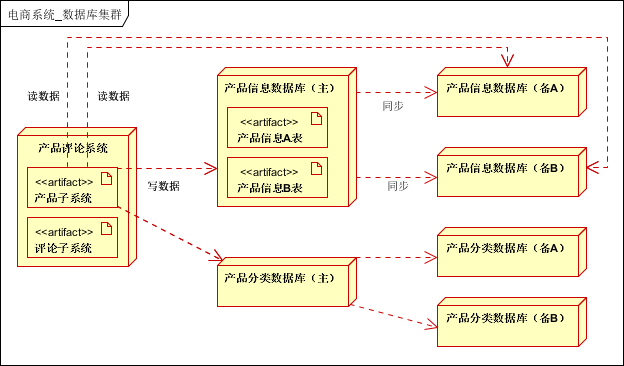
- 业务拆分后:每个子系统需要单独的库;
- 如果单独的库太大,可以根据业务特性,进行再次分库,比如商品分类库,产品库;
- 分库后,如果表中有数据量很大的,则进行分表,一般可以按照Id,时间等进行分表;(高级的用法是一致性Hash)
- 在分库、分表的基础上,进行读写分离;
相关中间件可参考Cobar(阿里,目前已不在维护),TDDL(阿里),Atlas(奇虎360),MyCat。
分库分表后序列的问题,JOIN,事务的问题,会在分库分表主题分享中,介绍。
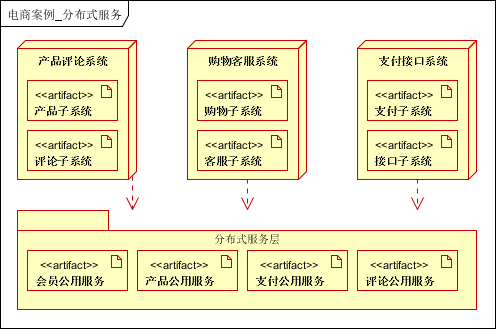
6.6服务化
将多个子系统公用的功能/模块,进行抽取,作为公用服务使用。比如本案例的会员子系统就可以抽取为公用的服务。
6.7消息队列
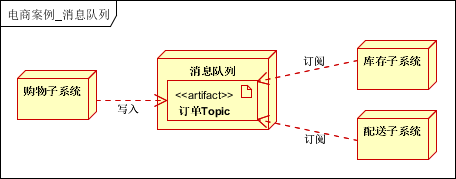
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统。是分布式系统的标准配置。本案例中,消息队列主要应用在购物,配送环节。
- 用户下单后,写入消息队列,后直接返回客户端;
- 库存子系统:读取消息队列信息,完成减库存;
- 配送子系统:读取消息队列信息,进行配送;
目前使用较多的MQ有Active MQ、Rabbit MQ、Zero MQ、MS MQ等,需要根据具体的业务场景进行选