前言
Pod因内存不足消失,可能由2种不同的故障导致,其中对故障2的复现、监控比较繁琐、耗时、棘手;
先对Pod oom相关故障进行了梳理;
故障1:Pod自身内存不足
Pod中的运行进程占用空间超出了Pod设置的Limit限制,导致该Pod中进程被Pod内的OS内核Kill掉;
此时Pod的Status为OOMKilled,Pod的OOMKilled状态可以借助Prometheus进行监控;


apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
现象如下
[root@master /]# kubectl delete -f test-oom.yaml pod "memory-demo" deleted [root@master /]# kubectl apply -f test-oom.yaml pod/memory-demo created [root@master /]# kubectl get pod -n mem-example -o wide -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES memory-demo 0/1 ContainerCreating 0 4s <none> node1 <none> <none> memory-demo 1/1 Running 0 18s 10.244.166.150 node1 <none> <none> memory-demo 0/1 OOMKilled 0 19s 10.244.166.150 node1 <none> <none>
故障2:Node宿主机内存不足
如果1个或N个pod分配内存的速度太快,以至于Kubelet没有机会在默认的检查窗口(默认10s)中发现它,并且总的Pod内存使用试图超过可分配内存,加上硬驱逐阈值的总和,那么内核的OOM killer将介入并终止Pod容器中的1个或N个进程。
Kubernetes的可分配资源(allocatable)无法控制运行在k8s集群Node节点上,但在集群之外进程的使用资源。
由于Node宿主机内存不足,而跑在Node宿主机上的Pod(Pod中运行的进程)占用的内存空间太多,被Node宿主机的OS内核OOM killed;
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "3Gi"
requests:
memory: "3Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "500M", "--vm-hang", "1"]
在K8s的Node节点上经常有其他进程和Pod争抢内存资源,导致该Node出现OOM现象,最终导致运行在该Node节点上Pod被OS给Kill掉;
采用监控系统和日志系统对该现象进行监控报警,并通过日志系统收集的日志进行佐证;
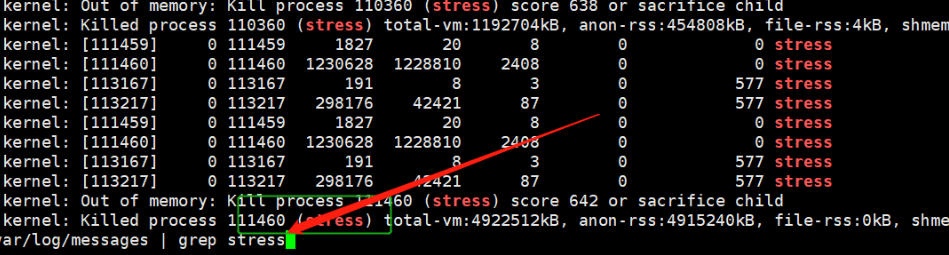
stress --vm 4 --vm-bytes 730M --vm-keep
查看K8s node的/var/log/messages日志,发现Pod中运行的stress进程,由于node宿主机内存不足,已经被该node宿主机的OS内核Kill掉了;
一、使用Top命令
我们平时会部署一些应用到Linux服务器,所以经常需要了解服务器的运行状态;
Top命令是帮助我们了解服务器当前的CPU、内存、进程状态的实用工具;
在node宿主机使用top命令查看被Pod管理的容器进程的内存占用情况;
1.top快速入门
(base) [root@docker /]# top top - 09:57:23 up 137 days, 25 min, 2 users, load average: 0.05, 0.03, 0.05 Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 32779568 total, 31119584 free, 636676 used, 1023308 buff/cache KiB Swap: 0 total, 0 free, 0 used. 31707740 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 8753 root 20 0 822868 47888 8040 S 0.7 0.1 11:52.10 python3.8 1 root 20 0 191028 4040 2604 S 0.0 0.0 0:46.16 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.26 kthreadd 4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 5 root 20 0 0 0 0 S 0.0 0.0 0:01.76 kworker/u16:0 6 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/0 7 root rt 0 0 0 0 S 0.0 0.0 0:00.06 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 S 0.0 0.0 3:13.03 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain 11 root rt 0 0 0 0 S 0.0 0.0 0:46.57 watchdog/0 12 root rt 0 0 0 0 S 0.0 0.0 0:41.06 watchdog/1 13 root rt 0 0 0 0 S 0.0 0.0 0:00.05 migration/1 14 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/1 16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kw