到目前为止,我们只考虑了实时系统上的调度。事实上, Linux可以做得更好些。除了支持多个CPU之外,内核也提供其他几种与调度相关的增强功能,在以后几节里会论述。但请注意,这些增强功能大大增加了调度器的复杂性,因此我主要考虑简化的情形,目的在于说明实质性的原理,而不考虑所有的边界情形和调度中出现的奇异情况。
1. SMP调度
多处理器系统上,内核必须考虑几个额外的问题,以确保良好的调度。
- CPU负荷必须尽可能公平地在所有的处理器上共享。如果一个处理器负责3个并发的应用程序,而另一个只能处理空闲进程,那是没有意义的。
- 进程与系统中某些处理器的亲合性(affinity)必须是可设置的。例如在4个CPU系统中,可以将计算密集型应用程序绑定到前3个CPU,而剩余的(交互式)进程则在第4个CPU上运行。
- 内核必须能够将进程从一个CPU迁移到另一个。但该选项必须谨慎使用,因为它会严重危害性能。在小型SMP系统上CPU高速缓存是最大的问题。对于真正大型系统, CPU与迁移进程此前使用的物理内存距离可能有若干米,因此对该进程内存的访问代价高昂。
进程对特定CPU的亲合性 ,定义在task_struct的 cpus_allowed 成 员 中 。 Linux 提供了sched_setaffinity系统调用,可修改进程与CPU的现有分配关系。
1.1 数据结构的扩展
在SMP系统上,每个调度器类的调度方法必须增加两个额外的函数:
<sched.h>
struct sched_class {
...
#ifdef CONFIG_SMP
unsigned long (*load_balance) (struct rq *this_rq, int this_cpu,
struct rq *busiest, unsigned long max_load_move,
struct sched_domain *sd, enum cpu_idle_type idle,
int *all_pinned, int *this_best_prio);
int (*move_one_task) (struct rq *this_rq, int this_cpu,
struct rq *busiest, struct sched_domain *sd,
enum cpu_idle_type idle);
#endif
...
}虽然其名字称之为load_balance,但这些函数并不直接负责处理负载均衡。每当内核认为有必要重新均衡时,核心调度器代码都会调用这些函数。特定于调度器类的函数接下来建立一个迭代器,使得核心调度器能够遍历所有可能迁移到另一个队列的备选进程,但各个调度器类的内部结构不能因为迭代器而暴露给核心调度器。 load_balance函数指针采用了一般性的函数load_balance,而move_one_task则使用了iter_move_one_task。这些函数用于不同的目的。
- iter_move_one_task从最忙碌的就绪队列移出一个进程,迁移到当前CPU的就绪队列。
- load_balance则允许从最忙的就绪队列分配多个进程到当前CPU,但移动的负荷不能比max_load_move更多
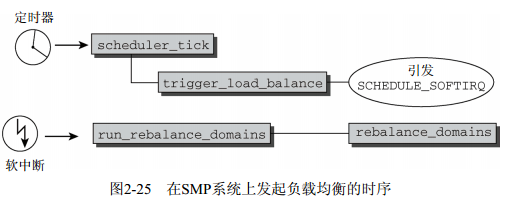
负载均衡处理过程是如何发起的?在SMP系统上,周期性调度器函数scheduler_tick按上文所述完成所有系统都需要的任务之后,会调用trigger_load_balance函数。这会引发SCHEDULE_SOFTIRQ软中断softIRQ(硬件中断的软件模拟,更多细节请参见第14章),该中断确保会在适当的时机执行run_rebalance_domains。该函数最终对当前CPU调用rebalance_domains,实现负载均衡。
时序如图2-25所示。
为执行重新均衡的操作,内核需要更多信息。因此在SMP系统上,就绪队列增加了额外的字段:
kernel/sched.c
struct rq {
...
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* 用于主动均衡 */
int active_balance;
int push_cpu;
/*该就绪队列的CPU: */
int cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
...
}就绪队列是特定于CPU的,因此cpu表示了该就绪队列所属的处理器。内核为每个就绪队列提供了一个迁移线程,可以接收迁移请求,这些请求保存在链表migration_queue中。这样的请求通常发源于调度器自身,但如果进程被限制在某一特定的CPU集合上,而不能在当前执行的CPU上继续运行时,也可能出现这样的请求。内核试图周期性地均衡就绪队列,但如果对某个就绪队列效果不佳,则队必须使用主动均衡(active balancing)。如果需要主动均衡,则将active_balance设置为非零值,而cpu则记录了从哪个处理器发起的主动均衡请求。
此外,所有的就绪队列组织为调度域(scheduling domain)。这可以将物理上邻近或共享高速缓存的CPU群集起来,应优先选择在这些CPU之间迁移进程。但在“普通”的SMP系统上,所有的处理器都包含在一个调度域中。因此我不会详细讨论该结构,要提的一点是该结构包含了大量参数,可以通过/proc/sys/kernel/cpuX/domainY设置。其中包括了在多长时间之后发起负载均衡(包括最大/最小时间间隔),导致队列需要重新均衡的最小不平衡值,等等。此外该结构还管理一些字段,可以在运行时设置,使得内核能够跟踪记录上一次均衡操作在何时执行,下一次将在何时执行。
那么load_balance做什么呢?该函数会检测在上一次重新均衡操作之后是否已经过去了足够的时间,在必要的情况下通过调用load_balance发起一轮新的重新均衡操作。该函数的代码流程图如图2-26所示。请注意,我在该图中描述的是一个简化的版本,因为SMP调度器必须处理大量边边角角的情况。如果都画出来,相关的细节会扰乱图中真正的实质性操作。

首先该函数必须标识出哪个队列工作量最大。该任务委托给find_busiest_queue,后者对一个特定的就绪队列调用。函数迭代所有处理器的队列(或确切地说,当前调度组中的所有处理器),比较其负荷权重。最忙的队列就是最后找到的负荷值最大的队列。
在find_busiest_queue标识出一个非常繁忙的队列之后,如果至少有一个进程在该队列上执行(否则负载均衡就没多大意义),则使用move_tasks将该队列中适当数目的进程迁移到当前队列。move_tasks函数接下来会调用特定于调度器类的load_balance方法。
在选择被迁移的进程时,内核必须确保所述的进程:
- 目前没有运行或刚结束运行,因为对运行进程而言, CPU高速缓存充满了进程的数据,迁移该进程则完全抵消了高速缓存带来的好处;
- 根据其CPU亲合性,可以在与当前队列关联的处理器上执行。
如果均衡操作失败(例如,远程队列上所有进程都有较高的内核内部优先级值,即较低的nice值),那么将唤醒负责最忙的就绪队列的迁移线程。为确保主动负载均衡执行得比