上一篇关于字符编码的随笔介绍了编码,输入码,机内码,字形码,字形库等概念。除此之外,还有一些其他的概念我们不得不了解,它们已经不属于现在,但是却时常影响着现在。代码页,正是这些有历史感的概念之一。这篇博文带你了解代码页和当前Windows对Unicode和ANSI编码的支持情况,末尾分析了一个乱码的案例,出于某知名软件,你一定不想错过。
Windows的默认编码?
偶尔在知乎看到这样的问题:为什么中文Windows选择GBK作为默认编码?其实会有这样的误解也难怪,为什么这么说呢?大家都从控制台的Helloworld开始,后来想要输出中文时自然先想到printf("你好,世界");运行发现真的出现了中文,仿佛英文和中文没什么区别,世界很美好的感觉。但学习更多之后发现Windows下的strlen("你好,世界")的值竟然是10(严格说是MinGW下使用GBK作源编码时或者使用VS时才是10),第一次感觉到了英文字母与汉字的区别,于是我们去寻找原因,终于得知GBK编码之类的各种编码,也知道了代码页这个令人疑惑的名词。你好世界,世界却是灰色的。
实际上微软早就声明:“UTF-16Little-endian是Microsoft以及Windows操作系统中的编码标准”。在Windows2000以前的操作系统上,内码的编码是和语言相关的(ANSI编码)。那时候简体中文版的Windows使用GBK,所有的中文的软件中的字符串也都是GBK,所以在window上运行也不会乱码。但是可想而至,这二者一旦不匹配就会出现乱码。不同语言国家的Windows编码都不一样,因此微软使用了代码页来解释字符编码,比如简体中文版的Windows默认代码页就是GBK,这意味着默认使用GBK来解释字符串,所以能显示中文是必然的,显示其他的语言(比如日语)是乱码也是必然的。
Windows2000之后(严格说是Windows NT 3.1之后)默认使用UTF-16作为编码标准。这是什么意思呢,意思就是全世界的字符你都可以处理,如果安装了相应的字体,你还可以显示全部字符,如果安装了相关输入法你还可以输入任意一种语言。但是哪些不是UTF-16编码的程序还能在新平台下运行吗?可以的,在这一方面微软还是负责任的,毕竟当初是自己提出的代码页方案,不能把软件开发商们都得罪了。所以直到今天(Windows 10)微软都是兼容二者,但是提倡使用UTF-16。那么Windows的默认编码是什么呢?事实是最好不要使用”默认编码“这个词,因为根本没有什么默认的编码(你可以决定使用任何一种编码,只不过别人不认识而已),推荐使用官方的说法“编码标准”,而且微软的编码标准是UTF-16L。
之所以很多初学者有误解,是因为一开始的程序基本都是控制台程序,而控制台的默认代码页确实是GBK。使用chcp命令可以查看当前代码页,可以看到回显Active code page: 936,这正是代表GBK。可以使用命令“chcp 65001”切换到UTF-8。控制台为了兼容性默认代码页是936,不代表Windows的编码标准是GBK,下面的试验都在对话框上显示,因为这是最简单的检验GUI编码方式的方法。
Windows对两种机制的兼容
那么具体Windows是怎样同时兼容二者:既支持UTF-16,又可以使用ANSI编码的呢?使用一个MessageBox做一下试验。
1 #include<windows.h>
2 int main() {
3 MessageBox(NULL, L"你好,世界", L"你好,世界", 0);
4 return 0;
5 }
效果是下面图1这样
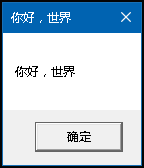
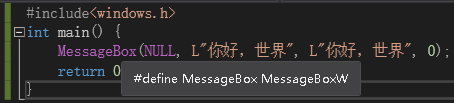
图1 图2
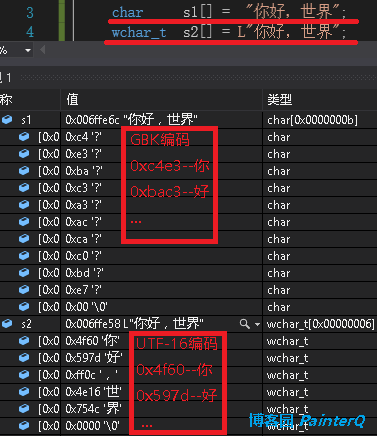
图3
但大家都知道,这里是使用了宏(如图2),调用MessageBox()实际上是调用了MessageBoxW(),MessageBoxW()的参数是wchar_t类型的,wchar_t*的字符串字面量一般被实现成UTF-16编码。与之对应的是MessageBoxA(),MessageBoxA()接受的参数是char*类型的,char*的字符串字面量被实现成ANSI编码。我说的字符串字面量被实现成某某编码是什么意思呢?用图片解释一下(图3),两个字符串虽然都是“你好,世界”但是运行时的样子完全不同。要强调机器只认识二进制,所以对机器来说这俩个字符串没有任何相同点。我们如果就是调用MassageBoxA(),传入char*会显示什么呢。
#include<windows.h>
int main() {
MessageBoxA(NULL, "你好,世界", "你好,世界", 0);
return 0;
}
很意外,结果竟然和图1完全一样。两个完全不同的二进制串竟然显示了相同的正确结果。其实这就是所谓的Windows兼容两种编码(UTF-16与ANSI编码),虽然推荐使用UTF-16但是,使用GBK也能正常在Windows的GUI中显示,但是你的应用程序已经被Windows归类为“非Unicode程序”。这里大家可以打开控制面板--时钟语言和区域--区域--管理,可以找到一个设置项:非Unicode程序的语言。可以选择中文或者其他语言,那它有什么影响呢?你不妨尝试一下改成日语或者韩语什么的,再运行第二段代码,你就能看到乱码了。但是除此之外几乎感受不到影响,程序们还是正常的运行着,没有出现乱码,这说明现在的绝大多数程序都是使用的UTF-16编码,所以这一个设置对他们根本没有影响。
但也并不绝对,在笔者把这一项设置修改为“日语(日本)”一周后(我已经忘了自己没有改回来,因为确实没有什么影响)看到一个奇怪的文件夹,他的名字是:????????。是哪一个程序搞出了这样的乱码呢?文件夹名字原来是什么呢(不要指望这是日语,这只是日语字符组成的乱码,不能看出含义)?下一节我们来分析这个例子,揭开这个还在使用ANSI编码的程序的羞耻的面纱。
一个乱码的例子分析
日本的ANSI编码是Shift_JIS,它是在有Unicode之前日本国内计算机的编码方式。可想而知,之所以出现????????这一段