说明
看《C++ Primer Plus》时整理的学习笔记,部分内容完全摘抄自《C++ Primer Plus》(第6版)中文版,Stephen Prata 著,张海龙 袁国忠译,人民邮电出版社。只做学习记录用途。
本章介绍 C++ 的内存模型和名称空间,包括数据的存储持续性、作用域和链接性,以及定位 new 运算符。
9.1 单独编译
C++ 鼓励程序员将组件函数放在独立的文件中,可以单独编译这些文件,然后将它们链接成可执行的程序。(通常,C++ 编译器既编译程序,也管理链接器。)如果只修改了一个文件,则可以只重新编译该文件,然后将它与其他文件的编译版本链接,大多数集成开发环境(如 Microsoft Visual C++ 和 Apple Xcode)都提供了这一功能,减少了人为管理的工作量。
9.1.1 程序组织策略
以下是一种非常有效且常用的程序组织策略,它将整个程序分为三个部分:
- 头文件:包含结构声明和使用这些结构的函数的原型。
- 源代码文件:包含定义与结构有关的函数的代码。
- 源代码文件:包含调用与结构有关的函数的代码。
在编译时,C++ 预处理器会将源代码文件中的 #include 指令替换成头文件的内容。源代码文件和它所包含的所有头文件被编译器看成一个包含以上所有信息的单独文件,该文件被称为翻译单元(translation unit)。描述一个具有文件作用域的变量时,它的实际可见范围是整个翻译单元。如果程序由多个源代码文件组成,那么该程序也将由多个翻译单元组成。每个翻译单元均对应一个源代码文件和它所包含的头文件。下图简要地说明了在 UNIX 系统中,将含 1 个头文件 coordin.h 与 2 个源代码文件 file1.cpp、file2.cpp 的程序编译成一个 out 可执行程序的过程。
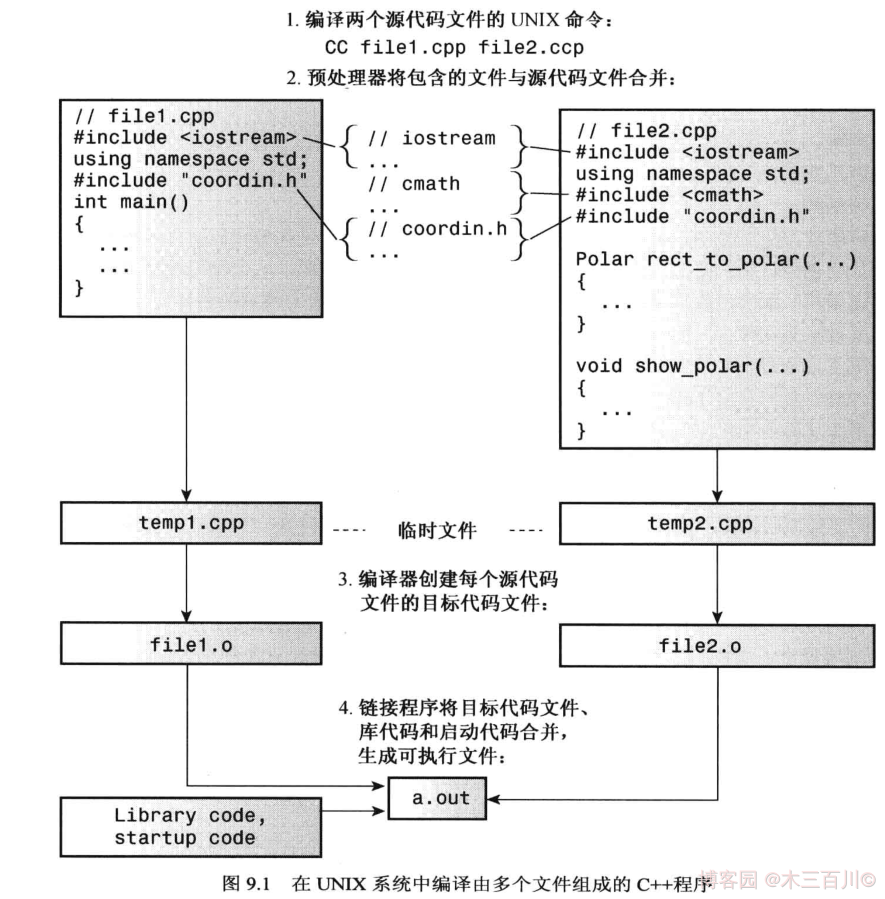
由于不同 C++ 编译器对函数的名称修饰方式不同,因此由不同编译器创建的二进制模块(对象代码文件,如上图中的 file1.o、file2.o)很可能无法正确地链接,因为两个编译器将为同一个函数生成不同的名称修饰。这时,可使用同一个编译器重新编译所有源代码文件,来消除链接错误。
9.1.2 头文件
在同一个文件中只能将同一个头文件包含一次,否则可能会出现重复定义的问题。一般在头文件中使用预处理器编译指令 #ifndef(即 if not defined)来避免多次包含同一个头文件。编译器首次遇到该文件时,名称 COORDIN_H_ 没有定义(加上下划线以获得一个在其他地方不太可能被定义的名称),这时编译器将查看 #ifndef 和 #endif 之间的内容,并通过 #define 定义名称 COORDIN_H_。如果在同一个文件中遇到其他包含 coordin.h 的代码,编译器将知道 COORDIN_H_ 已经被定义了,从而跳到 #endif 后面的一行。但这种方法并不能防止编译器将文件包含两次,而只是让它忽略除第一次包含之外的所有内容。
#ifndef COORDIN_H_
#define COORDIN_H_
//头文件内容
...
#endif
在头文件中,可以包含以下内容:
- 使用
#define或const定义的符号常量。 - 结构声明,它们并不创建变量,只是告诉编译器当需要创建它们时应该如何创建。
- 类声明,同结构声明一样,它们并不创建类,只是告诉编译器当需要创建它们时应该如何创建。
- 模板定义,它们不是将被编译的代码,只是被用来指示编译器如何生成与源代码中的函数调用相匹配的函数定义。
- 常规函数原型。
- 内联函数定义。
不要将常规函数定义(非函数模板、非内联函数)或常规变量声明(非 const 变量、非 static 变量)放到头文件中,否则当同一个程序的两个源文件都包含该头文件时,可能会出现重复定义的问题。
9.1.3 源代码文件
在源代码文件开头处,通常会使用 #include 预编译指令包含所需的头文件,有以下两种包含方式:
- 使用尖括号
<>包含,例如#include <iostream>,如果文件名包含在尖括号中,则 C++ 编译器将在存储标准头文件的主机系统的文件系统中查找,一般用来包含系统自带的头文件或标准头文件。 - 使用双引号
""包含,例如#include "coordin.h",如果文件名包含在双引号中,则编译器将首先查找当前的工作目录或源代码目录(或其它目录,这取决于编译器以及用户设置),如果没有在那里找到头文件,则将在标准位置查找,一般用来包含用户自定义的头文件。
不要在源代码文件中包含其它源代码文件,这可能出现重复定义的问题。在源代码文件中,一般包含头文件中常规函数原型所对应的函数定义(声明与定义相分离的策略,声明位于头文件中,定义位于源代码文件中)、类声明中成员函数的定义、全局变量声明等。
9.2 存储持续性、作用域和链接性
不同的 C++ 存储方式是通过存储持续性、作用域和链接性来描述的,下表总结了引入名称空间之前使用的存储特性。
| 存储描述 | 持续性 | 作用域 | 链接性 | 声明方式 |
|---|---|---|---|---|
| 常规自动变量 | 自动存储持续性 | 代码块 | 无 | 在代码块中 |
| 寄存器自动变量 | 自动存储持续性 | 代码块 | 无 | 在代码块中,使用关键字 register |
| 外部链接性的静态变量 | 静态存储持续性 | 翻译单元 | 外部 | 不在任何函数内,分为定义声明和引用声明 |
| 内部链接性的静态变量 | 静态存储持续性 | 翻译单元 | 内部 | 不在任何函数内,使用关键字 static |
| 无链接性的静态变量 | 静态存储持续性 | 代码块 | 无 | 在代码块中,使用关键字 static |
下面对这些存储特性进行逐一介绍。
9.2.1 存储持续性种类
C++ 使用三种(C++11 中是四种)不同的方案来存储数据,这些方案的区别就在于数据保留在内存中的时间,即存储持续性。
- 自动存储持续性:在函数定义中声明的变量(包括函数参数)的存储持续性为自动的。它们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,它们使用的内存被释放。
- 静态存储持续性:在函数定义外部定义的变量和使用关键字
static定义的变量的存储持续性都为静态。它们在程序整个运行过程中都存在。 - 动态存储持续性:用
new运算符分配的内存将一直存在,直到使用delete运算符将其释放或程序结束为止。这种内存的存储持续性为动态,有时被称为自由存储(free store)或