1 hadoop概述
1.1 为什么会有大数据处理
传统模式已经满足不了大数据的增长
1)存储问题
- 传统数据库:存储亿级别的数据,需要高性能的服务器;并且解决不了本质问题;只能存结构化数据
- 大数据存储:通过分布式存储,将数据存到一台机器的同时,还可以备份到其他机器上,这样当某台机器挂掉了或磁盘坏掉了,在其他机器上可以拿到该数据,数据不会丢失(可备份)
- 磁盘不够挂磁盘,机器不够加机器(可横行扩展)
2)分析数据问题
- 传统数据库: 当数据库存储亿级别的数据后,查询效率也下降的很快,查询不能秒级返回
- 大数据分析:分布式计算。也可以横行扩展
MapReduce:(批处理)多次与磁盘进行交互,运行比较慢
运算的数据是有范围的,运算完一次,就代表该批次处理完成
实时计算: (流处理)对时间的要求很高,基本可以快速处理完成
实时计算的数据,没有范围的,会根据某个时间的范围进行计算。spark streaming ,storm, flink

1.2 什么是hadoop?
Hadoop项目是以可靠、可扩展和分布式计算为目的而发展的开源软件
Hadoop 是Apache的顶级项目
Apache:APACHE软件基金会,支持Apache的开源软件社区项目,为公众提供好的软件产品
项目主页:
http://hadoop.apache.org
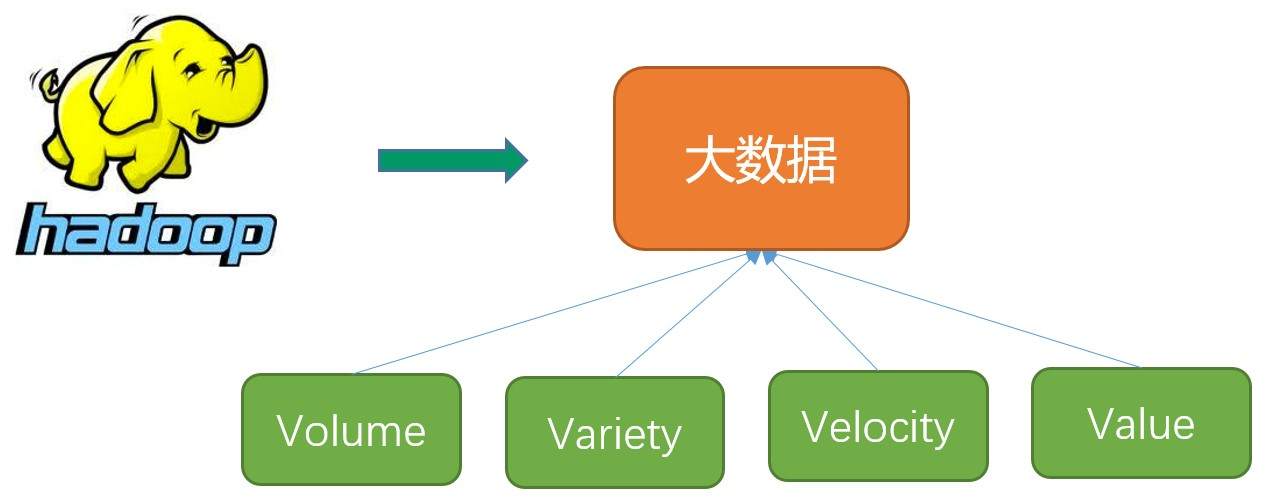
大数据的主要特点(4V)
- 数据容量大(Volume)。从TB级别,跃升到PB级别
- 数据类型繁多(Variety)。包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求
- 商业价值高(Value)。客户群体细分,提供定制化服务;发掘新的需求同时提高投资的回报率;降低服务成本
- 处理速度快(Velocity)。这是大数据区分于传统数据挖掘的最显著特征。预计到2020年,全球数据使用量将达到35.2ZB。在如此海量的数据面前,处理数据的效率就是企业的生命
hadoop的历史起源
创始人: Doug Cutting 和 Mike Cafarella
2002开始,两位创始人开发开源搜索引擎解决方案: Nutch
2004年受Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发,NDFS( Nutch Distributed File System )引入Nutch
2006年 在Yahoo!工作的Doug Cutting将这套大数据处理软件命名为Hadoop

hadoop核心组件
用于解决两个核心问题:存储和计算
核心组件
1)Hadoop Common:
一组分布式文件系统和通用I/O的组件与接口(序列化、Java RPC和持久化数据结构)
2)Hadoop Distributed FileSystem(Hadoop分布式文件系统HDFS)
分布式存储, 有备份, 可扩展
3)Hadoop MapReduce(分布式计算框架)
分布式计算,多台机器同时计算一部分,得到部分结果,再将部分结果汇总,得到总体的结果(可扩展)
4)Hadoop YARN(分布式资源管理器)
MapReduce任务计算的时候,运行在yarn上,yarn提供资源
hadoop的框架演变
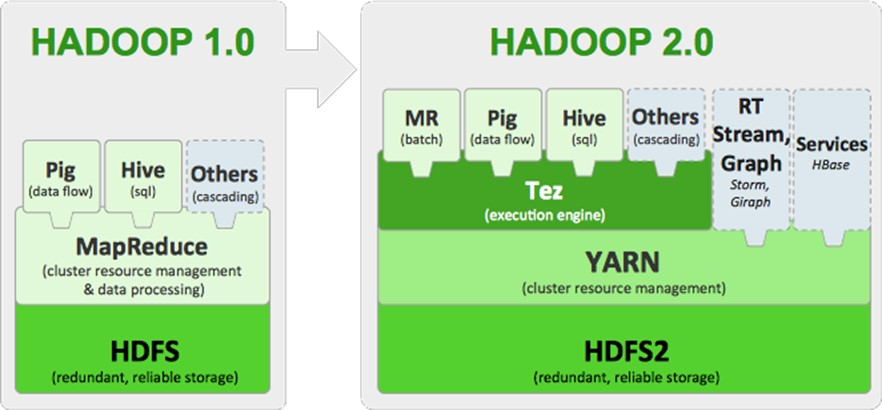
Hadoop1.0 的 MapReduce(MR1):集资源管理和任务调用、计算功能绑在一起,扩展性较差,不支持多计算框架
Hadoop2.0 的Yarn(MRv2):将资源管理和任务调用两个功能分开,提高扩展性,并支持多计算框架
hadoop生态圈
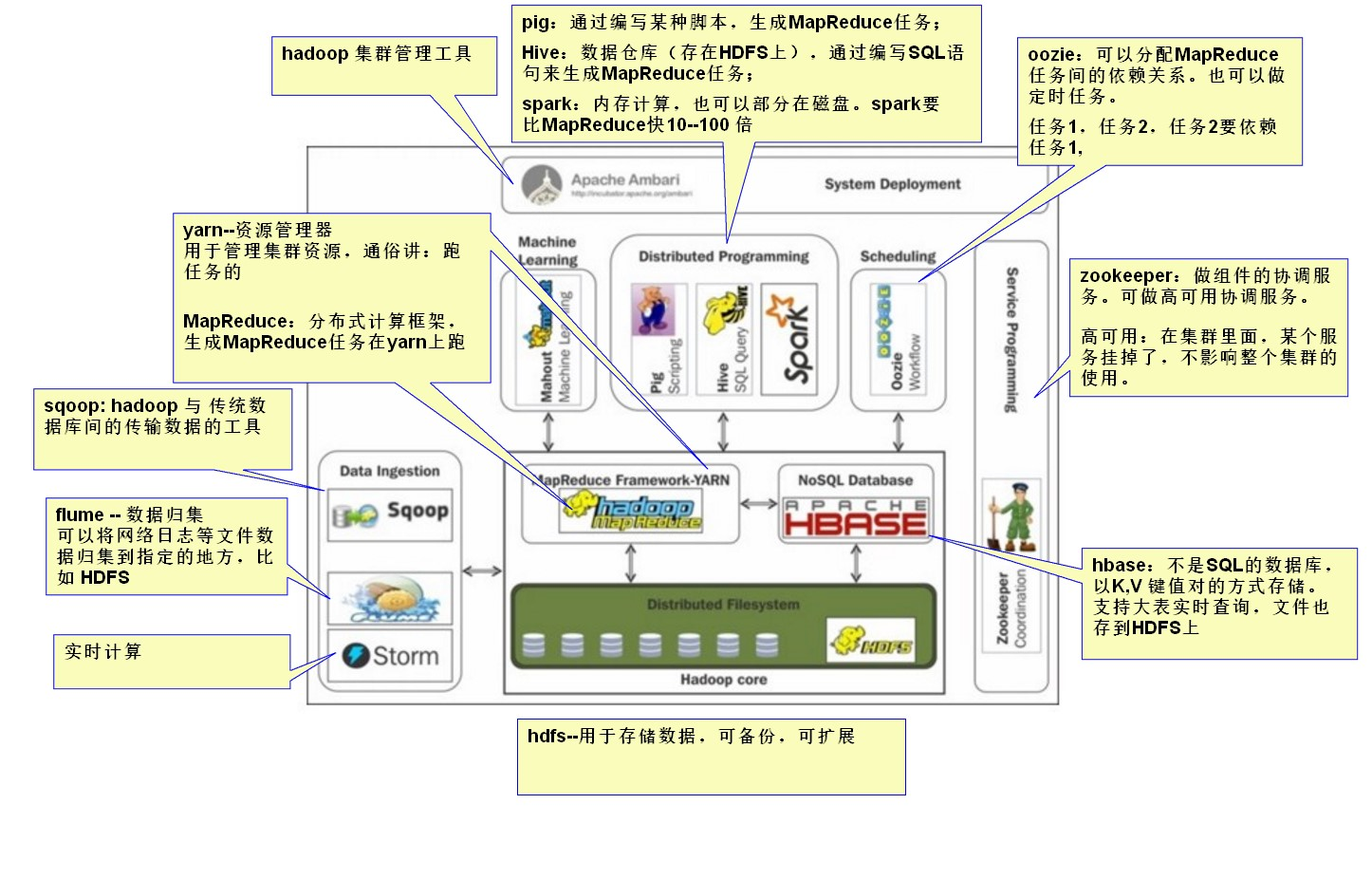

1)HDFS(Hadoop分布式文件系统)
HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS 为hive、HBase等工具提供了基础
2)MapReduce(分布式计算框架)
MapReduce是一种分布式计算模型,用以进行大数据量的计算,是一种离线计算框架
这个 MapReduce 的计算过程简而言之,就是将大数据集分解为成若干个小数据集,每个(或若干个)数据集分别由集群中的一个结点(一般就是一台主机)进行处理并生成中间结果,然后将每个结点的中间结果进行合并, 形成最终结果
3)HBASE(分布式列存数据库)
HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行
4)Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据
5)flume(分布式日志收集系统)
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中
6)Storm(流示计算、实时计算)
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的