概述
本lab将用go完成一个MapReduce框架,完成后将大大加深对MapReduce的理解。
Part I: Map/Reduce input and output
这部分需要我们实现common_map.go中的doMap()和common_reduce.go中的doReduce()两个函数。
可以先从测试用例下手:
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}从Sequential()开始调用链如下:
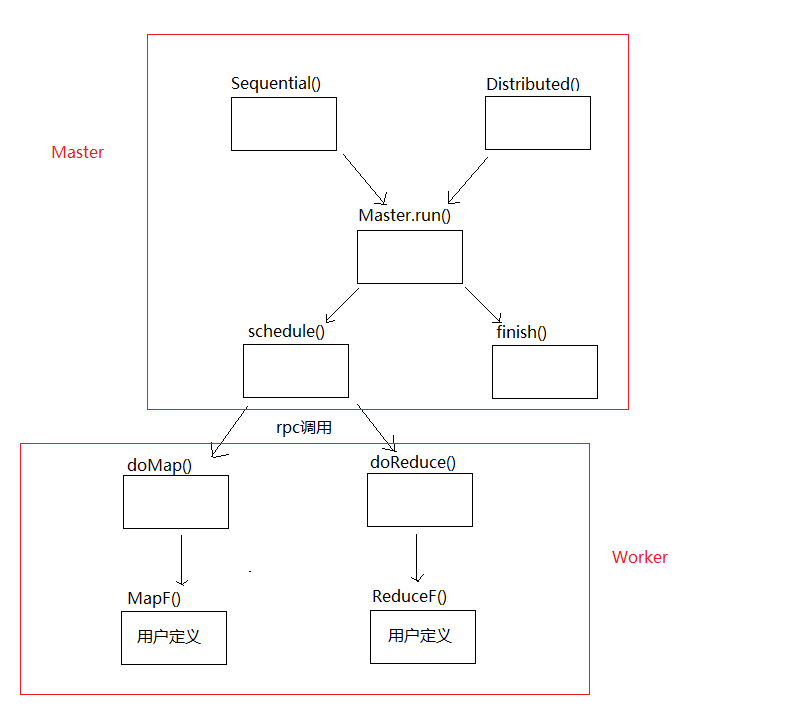
现在要做的是完成doMap()和doReduce()。
doMap():
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
//打开inFile文件,读取全部内容
//调用mapF,将内容转换为键值对
//根据reduceName()返回的文件名,打开nReduce个中间文件,然后将键值对以json的格式保存到中间文件
inputContent, err := ioutil.ReadFile(inFile)
if err != nil {
panic(err)
}
keyValues := mapF(inFile, string(inputContent))
var intermediateFileEncoders []*json.Encoder
for reduceTaskNumber := 0; reduceTaskNumber < nReduce; reduceTaskNumber++ {
intermediateFile, err := os.Create(reduceName(jobName, mapTask, reduceTaskNumber))
if err != nil {
panic(err)
}
defer intermediateFile.Close()
enc := json.NewEncoder(intermediateFile)
intermediateFileEncoders = append(intermediateFileEncoders, enc)
}
for _, kv := range keyValues {
err := intermediateFileEncoders[ihash(kv.Key) % nReduce].Encode(kv)
if err != nil {
panic(err)
}
}
}总结来说就是:
- 读取输入文件内容
- 将内容交个用户定义的Map函数执行,生成键值对
- 保存键值对
doReduce:
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
//读取当前reduceTaskNumber对应的中间文件中的键值对,将相同的key的value进行并合
//调用reduceF
//将reduceF的结果以json形式保存到mergeName()返回的文件中
kvs := make(map[string][]string)
for mapTaskNumber := 0; mapTaskNumber < nMap; mapTaskNumber++ {
midDatafileName := reduceName(jobName, mapTaskNumber, reduceTask)
file, err := os.Open(midDatafileName)
if err != nil {
panic(err)
}
defer file.Close()
dec := json.NewDecoder(file)
for {
var kv KeyValue
err = dec.Decode(&kv)
if err != nil {
break
}
values, ok := kvs[kv.Key]
if ok {
kvs[kv.Key] = append(values, kv.Value)
} else {
kvs[kv.Key] = []string{kv.Value}
}
}
}
outputFile, err := os.Create(outFile)
if err != nil {
panic(err)
}
defer outputFile.Close()
enc := json.NewEncoder(outputFile)
for key, values := range kvs {
enc.Encode(KeyValue{key, reduceF(key, values)})
}
}总结:
- 读取中间数据
- 执行reduceF
- 保存结果
文件转换的过程大致如下:
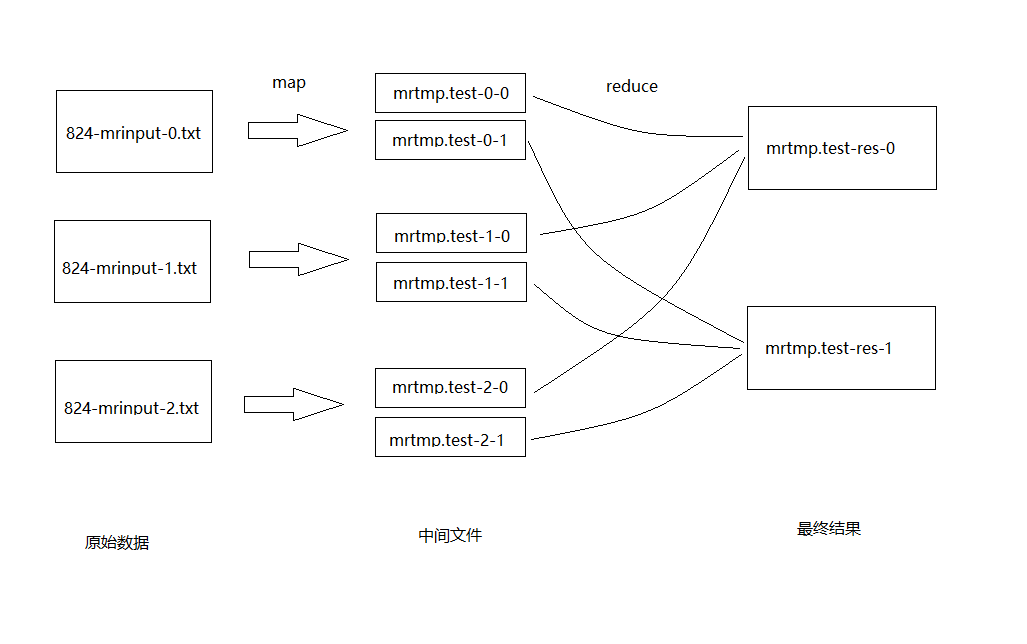
Part II: Single-worker word count
这部分将用一个简单的实例展示如何使用MR框架。需要我们实现main/wc.go中的mapF()和reduceF()来统计单词的词频。
mapF:
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
words := strings.FieldsFunc(contents, func(r rune) bool {
return !unicode.IsLetter(r)
})
var kvs []mapreduce.KeyValue
for _, word := range words {
kvs = append(kvs, mapreduce.KeyValue{word, "1"})
}
return kvs
}将文本内容分割成单词,每个单词对应一个<word, "1">键值对。
reduceF:
func reduceF(key string, values []string) string {
// Your code here (Part II).
return strconv.Itoa(len(values))
}value中有多少个"1",就说明这个word出现了几次。