ÎÄŐÂŐűŔí×Ô ˛©Ń§ąČżńŇ°ĽÜąąĘ¦
ʲôĘÇJMM
˛˘·˘±ŕłĚÁěÓňµÄąŘĽüÎĘĚâ
ĎßłĚÖ®ĽäµÄͨĐĹ
Ď̵߳ÄͨĐĹĘÇÖ¸ĎßłĚÖ®ĽäŇÔşÎÖÖ»úÖĆŔ´˝»»»ĐĹϢˇŁÔÚ±ŕłĚÖĐŁ¬ĎßłĚÖ®ĽäµÄͨĐĹ»úÖĆÓĐÁ˝ÖÖŁ¬ą˛ĎíÄÚ´ćşÍĎűϢ´«µÝˇŁ
? ÔÚą˛ĎíÄÚ´ćµÄ˛˘·˘ÄŁĐÍŔĎßłĚÖ®Ľäą˛ĎíłĚĐňµÄą«ą˛×´Ě¬Ł¬ĎßłĚÖ®ĽäͨąýĐ´-¶ÁÄÚ´ćÖеĹ«ą˛×´Ě¬Ŕ´ŇţĘ˝˝řĐĐͨĐĹŁ¬µäĐ͵ŲĎíÄÚ´ćͨĐĹ·˝Ę˝ľÍĘÇͨąýą˛Ďí¶ÔĎó˝řĐĐͨĐšŁ
ÔÚĎűϢ´«µÝµÄ˛˘·˘ÄŁĐÍŔĎßłĚÖ®ĽäĂ»ÓĐą«ą˛×´Ě¬Ł¬ĎßłĚÖ®Ľä±ŘĐëͨąýĂ÷Č·µÄ·˘ËÍĎűϢŔ´ĎÔĘ˝˝řĐĐͨĐĹŁ¬ÔÚjavaÖеäĐ͵ÄĎűϢ´«µÝ·˝Ę˝ľÍĘÇwait()şÍnotify()ˇŁ
Ď̼߳äµÄͬ˛˝
ͬ˛˝ĘÇÖ¸łĚĐňÓĂÓÚżŘÖƲ»Í¬ĎßłĚÖ®Ľä˛Ů×÷·˘ÉúĎŕ¶ÔËłĐňµÄ»úÖơŁ
ÔÚą˛ĎíÄڴ沢·˘ÄŁĐÍŔͬ˛˝ĘÇĎÔĘ˝˝řĐеġŁłĚĐňÔ±±ŘĐëĎÔʽָ¶¨Äł¸ö·˝·¨»ňÄł¶Î´úÂëĐčŇŞÔÚĎßłĚÖ®Ľä»ĄłâÖ´ĐСŁ
? ÔÚĎűϢ´«µÝµÄ˛˘·˘ÄŁĐÍŔÓÉÓÚĎűϢµÄ·˘ËͱŘĐëÔÚĎűϢµÄ˝ÓĘŐ֮ǰŁ¬Ňň´Ëͬ˛˝ĘÇŇţĘ˝˝řĐеġŁ
ĎÖ´úĽĆËă»úµÄÄÚ´ćÄŁĐÍ
ÎďŔíĽĆËă»úÖеIJ˘·˘ÎĘĚ⣬ÎďŔí»úÓöµ˝µÄ˛˘·˘ÎĘĚâÓëĐéÄâ»úÖеÄÇéżöÓв»ÉŮĎŕËĆÖ®´¦Ł¬ÎďŔí»ú¶Ô˛˘·˘µÄ´¦Ŕí·˝°¸¶ÔÓÚĐéÄâ»úµÄʵĎÖҲÓĐĎŕµ±´óµÄ˛ÎżĽŇâŇ塣
ĆäÖĐŇ»¸öÖŘŇŞµÄ¸´ÔÓĐÔŔ´Ô´ĘÇľř´ó¶ŕĘýµÄÔËËăČÎÎń¶Ľ˛»żÉÄÜÖ»żż´¦ŔíĆ÷ˇ°ĽĆË㡱ľÍÄÜÍęłÉŁ¬´¦ŔíĆ÷ÖÁÉŮŇŞÓëÄÚ´ć˝»»ĄŁ¬Čç¶ÁȡÔËËăĘýľÝˇ˘´ć´˘ÔËËă˝áąűµČŁ¬Őâ¸öI/O˛Ů×÷ĘÇşÜÄŃĎűłýµÄŁ¨ÎŢ·¨˝öżżĽÄ´ćĆ÷Ŕ´ÍęłÉËůÓĐÔËËăČÎÎńŁ©ˇŁ
ÔçĆÚĽĆËă»úÖĐcpuşÍÄÚ´ćµÄËٶČĘDz¶ŕµÄŁ¬µ«ÔÚĎÖ´úĽĆËă»úÖĐŁ¬cpuµÄÖ¸ÁîËٶČÔ¶ł¬ÄÚ´ćµÄ´ćȡËٶČ,ÓÉÓÚĽĆËă»úµÄ´ć´˘É豸Óë´¦ŔíĆ÷µÄÔËËăËٶČÓĐĽ¸¸öĘýÁżĽ¶µÄ˛îľŕŁ¬ËůŇÔĎÖ´úĽĆËă»úϵͳ¶Ľ˛»µĂ˛»ĽÓČëŇ»˛ă¶ÁĐ´ËٶȾˇżÉÄܽӽü´¦ŔíĆ÷ÔËËăËٶȵĸßËŮ»ş´ćŁ¨CacheŁ©Ŕ´×÷ÎŞÄÚ´ćÓë´¦ŔíĆ÷Ö®ĽäµÄ»şłĺŁş˝«ÔËËăĐčŇŞĘąÓõ˝µÄĘýľÝ¸´ÖƵ˝»ş´ćÖĐŁ¬ČĂÔËËăÄÜżěËŮ˝řĐĐŁ¬µ±ÔËËă˝áĘřşóÔŮ´Ó»ş´ćͬ˛˝»ŘÄÚ´ćÖ®ÖĐŁ¬ŐâŃů´¦ŔíĆ÷ľÍÎŢĐëµČ´ý»şÂýµÄÄÚ´ć¶ÁĐ´ÁˡŁ
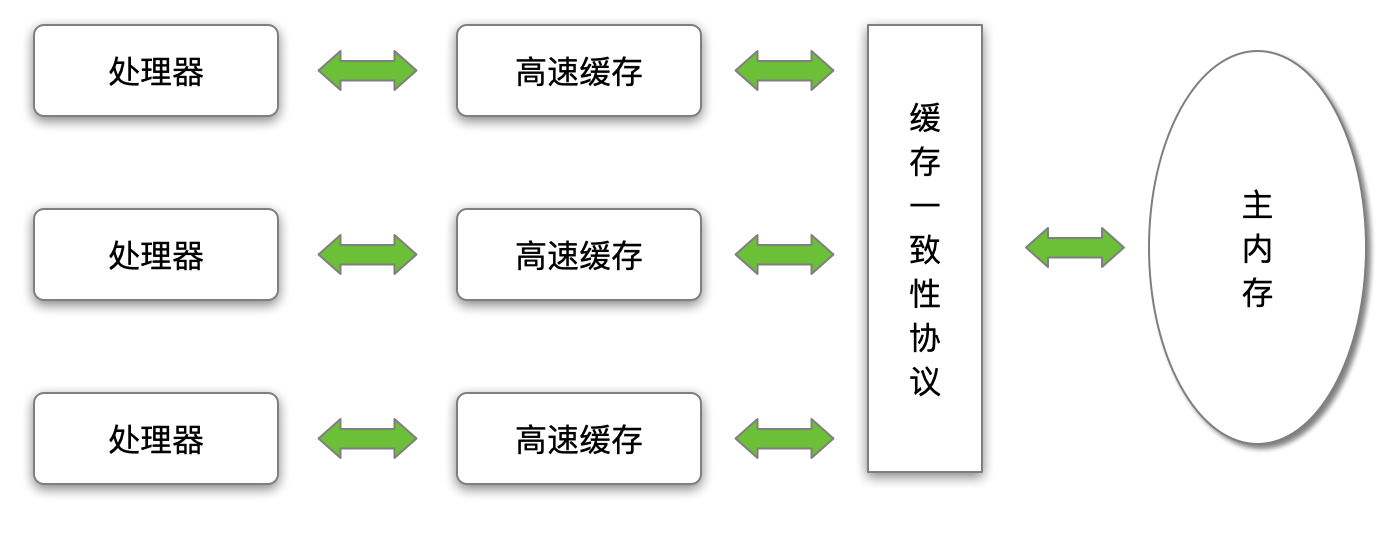
»ůÓÚ¸ßËŮ»ş´ćµÄ´ć´˘˝»»ĄşÜşĂµŘ˝âľöÁË´¦ŔíĆ÷ÓëÄÚ´ćµÄËٶČì¶ÜŁ¬µ«ĘÇҲΪĽĆËă»úϵͳ´řŔ´¸ü¸ßµÄ¸´ÔӶȣ¬ŇňÎŞËüŇýČëÁËŇ»¸öеÄÎĘĚ⣺»ş´ćŇ»ÖÂĐÔŁ¨Cache CoherenceŁ©ˇŁ
ÔڶദŔíĆ÷ϵͳÖĐŁ¬Ăż¸ö´¦ŔíĆ÷¶ĽÓĐ×ÔĽşµÄ¸ßËŮ»ş´ćŁ¬¶řËüĂÇÓÖą˛ĎíͬһÖ÷Äڴ棨MainMemoryŁ©ˇŁµ±¶ŕ¸ö´¦ŔíĆ÷µÄÔËËăČÎÎń¶ĽÉ漰ͬһżéÖ÷ÄÚ´ćÇřÓňʱŁ¬˝«żÉÄܵĽÖ¸÷×ԵĻş´ćĘýľÝ˛»Ň»ÖÂŁ¬ľŮŔý˵Ă÷±äÁżÔÚ¶ŕ¸öCPUÖ®ĽäµÄą˛ĎíˇŁ
ČçąűŐćµÄ·˘ÉúŐâÖÖÇéżöŁ¬ÄÇͬ˛˝»Řµ˝Ö÷ÄÚ´ćʱŇÔ˵Ļş´ćĘýľÝΪ׼ÄŘŁżÎŞÁË˝âľöŇ»ÖÂĐÔµÄÎĘĚ⣬ĐčŇŞ¸÷¸ö´¦ŔíĆ÷·ĂÎĘ»ş´ćʱ¶Ľ×ńŃһЩĐŇ飬ÔÚ¶ÁдʱҪ¸ůľÝĐŇéŔ´˝řĐвŮ×÷Ł¬ŐâŔŕĐŇéÓĐMSIˇ˘MESIŁ¨Illinois ProtocolŁ©ˇ˘MOSIˇ˘Synapseˇ˘FireflyĽ°Dragon ProtocolµČˇŁ
¸ĂÄÚ´ćÄŁĐÍ´řŔ´µÄÎĘĚâ
ĎÖ´úµÄ´¦ŔíĆ÷ĘąÓĂĐ´»şłĺÇřÁŮʱ±Ł´ćĎňÄÚ´ćĐ´ČëµÄĘýľÝˇŁĐ´»şłĺÇřżÉŇÔ±ŁÖ¤Ö¸ÁîÁ÷Ë®ĎßłÖĐřÔËĐĐŁ¬ËüżÉŇÔ±ÜĂâÓÉÓÚ´¦ŔíĆ÷ÍŁ¶ŮĎÂŔ´µČ´ýĎňÄÚ´ćĐ´ČëĘýľÝ¶ř˛úÉúµÄŃӳ١Ł
ͬʱŁ¬Í¨ąýŇÔĹú´¦ŔíµÄ·˝Ę˝Ë˘ĐÂĐ´»şłĺÇřŁ¬ŇÔĽ°şĎ˛˘Đ´»şłĺÇřÖжÔͬһÄÚ´ćµŘÖ·µÄ¶ŕ´ÎĐ´Ł¬ĽőÉٶÔÄÚ´ć×ÜĎßµÄŐĽÓáŁ
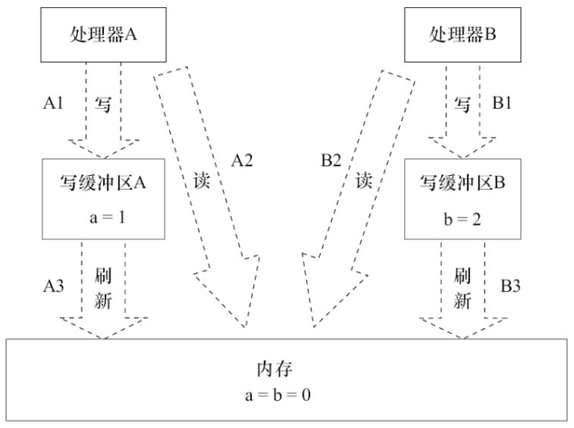
ËäȻд»şłĺÇřÓĐŐâĂ´¶ŕşĂ´¦Ł¬µ«Ăż¸ö´¦ŔíĆ÷ÉϵÄĐ´»şłĺÇřŁ¬˝ö˝ö¶ÔËüËůÔڵĴ¦ŔíĆ÷żÉĽűˇŁŐâ¸öĚŘĐÔ»á¶ÔÄÚ´ć˛Ů×÷µÄÖ´ĐĐËłĐň˛úÉúÖŘŇŞµÄÓ°Ď죺´¦ŔíĆ÷¶ÔÄÚ´ćµÄ¶Á/Đ´˛Ů×÷µÄÖ´ĐĐËłĐňŁ¬˛»Ň»¶¨ÓëÄÚ´ćʵĽĘ·˘ÉúµÄ¶Á/Đ´˛Ů×÷ËłĐňŇ»ÖÂŁˇ
? ´¦ŔíĆ÷AşÍ´¦ŔíĆ÷B°´łĚĐňµÄËłĐň˛˘ĐĐÖ´ĐĐÄÚ´ć·ĂÎĘŁ¬×îÖŐżÉÄܵõ˝x=y=0µÄ˝áąűˇŁ
´¦ŔíĆ÷AşÍ´¦ŔíĆ÷BżÉŇÔͬʱ°Ńą˛Ďí±äÁżĐ´Čë×ÔĽşµÄĐ´»şłĺÇřŁ¨A1Ł¬B1Ł©Ł¬Č»şó´ÓÄÚ´ćÖжÁȡÁíŇ»¸öą˛Ďí±äÁżŁ¨A2Ł¬B2Ł©Ł¬×îşó˛Ĺ°Ń×ÔĽşĐ´»ş´ćÇřÖбŁ´ćµÄÔŕĘýľÝˢе˝ÄÚ´ćÖĐŁ¨A3Ł¬B3Ł©ˇŁ
µ±ŇÔŐâÖÖʱĐňÖ´ĐĐʱŁ¬łĚĐňľÍżÉŇԵõ˝x=y=0µÄ˝áąűˇŁ
? ´ÓÄÚ´ć˛Ů×÷ʵĽĘ·˘ÉúµÄËłĐňŔ´ż´Ł¬Ö±µ˝´¦ŔíĆ÷AÖ´ĐĐA3Ŕ´Ë˘ĐÂ×ÔĽşµÄĐ´»ş´ćÇřŁ¬Đ´˛Ů×÷A1˛ĹËăŐćŐýÖ´ĐĐÁˡŁËäČ»´¦ŔíĆ÷AÖ´ĐĐÄÚ´ć˛Ů×÷µÄËłĐňÎŞŁşA1ˇúA2Ł¬µ«ÄÚ´ć˛Ů×÷ʵĽĘ·˘ÉúµÄËłĐňČ´ĘÇA2ˇúA1ˇŁ
| Processor A | Processor B | |
|---|---|---|
| ´úÂë | a=1; //A1 x=1; //A2 | b=2; //B1 y=a; //B2 |
| ÔËĐĐ˝áąű | łőʼ״̬ a=b=0 ´¦ŔíĆ÷ÔĘĐíµĂµ˝˝áąű x=y=0 |
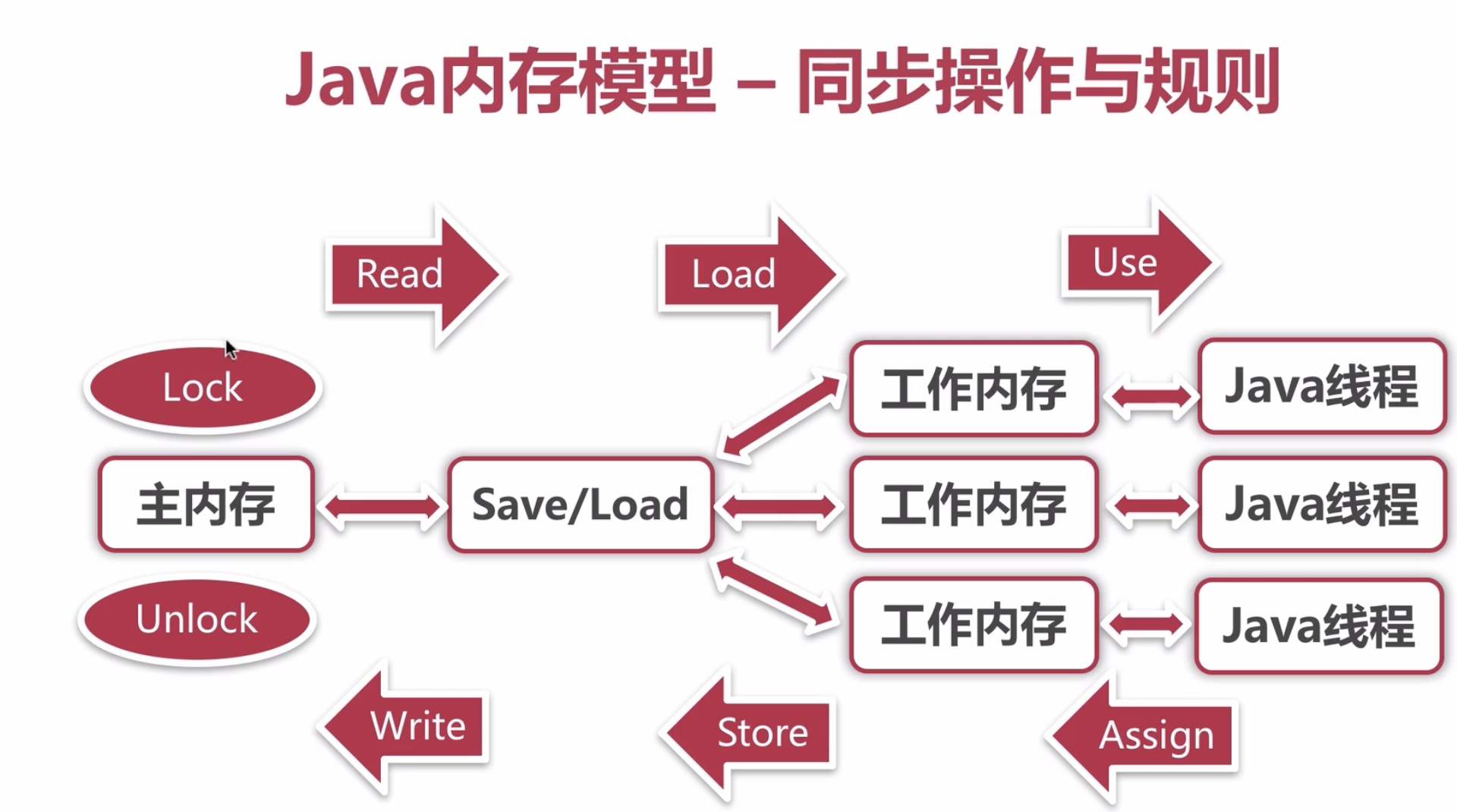
JavaÄÚ´ćÄŁĐͶ¨Ňĺ
JMM¶¨ŇĺÁËJava ĐéÄâ»ú(JVM)ÔÚĽĆËă»úÄÚ´ć(RAM)ÖеŤ×÷·˝Ę˝ˇŁJVMĘÇŐű¸öĽĆËă»úĐéÄâÄŁĐÍŁ¬ËůŇÔJMMĘÇÁĄĘôÓÚJVMµÄˇŁ
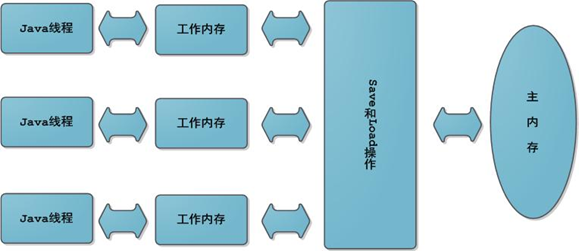
´ÓłéĎóµÄ˝Ç¶ČŔ´ż´Ł¬JMM¶¨ŇĺÁËĎ̺߳ÍÖ÷ÄÚ´ćÖ®ĽäµÄłéĎóąŘϵŁşĎßłĚÖ®ĽäµÄą˛Ďí±äÁż´ć´˘ÔÚÖ÷Äڴ棨Main MemoryŁ©ÖĐŁ¬Ăż¸öĎ̶߳ĽÓĐŇ»¸öË˝ÓеıľµŘÄڴ棨Local MemoryŁ©Ł¬±ľµŘÄÚ´ćÖĐ´ć´˘Á˸ĂĎßłĚŇÔ¶Á/Đ´ą˛Ďí±äÁżµÄ¸±±ľˇŁ
±ľµŘÄÚ´ćĘÇJMMµÄŇ»¸öłéĎó¸ĹÄ˛˘˛»Őćʵ´ćÔÚˇŁËüş¸ÇÁË»ş´ćˇ˘Đ´»şłĺÇřˇ˘ĽÄ´ćĆ÷ŇÔĽ°ĆäËűµÄÓ˛ĽţşÍ±ŕŇëĆ÷ÓĹ»ŻˇŁ
JavaÄÚ´ćÇřÓň
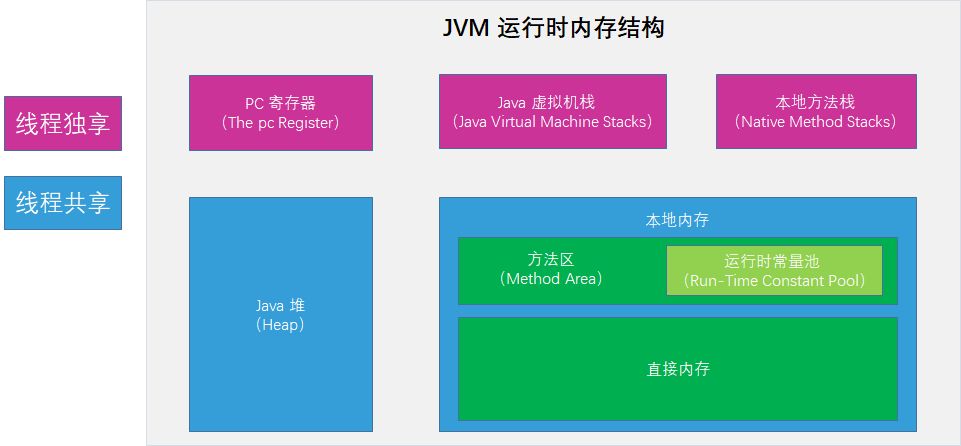
JavaĐéÄâ»úÔÚÔËĐĐłĚĐňʱ»á°ŃĆä×Ô¶ŻąÜŔíµÄÄÚ´ć»®·ÖÎŞŇÔÉĎĽ¸¸öÇřÓňŁ¬Ăż¸öÇřÓň¶ĽÓеÄÓĂÍľŇÔĽ°´´˝¨Ďú»ŮµÄʱ»úŁ¬ĆäÖĐŔ¶É«˛ż·Ö´ú±íµÄĘÇËůÓĐĎ̹߳˛ĎíµÄĘýľÝÇřÓňŁ¬¶ř×ĎÉ«˛ż·Ö´ú±íµÄĘÇĂż¸öĎ̵߳ÄË˝ÓĐĘýľÝÇřÓňˇŁ
·˝·¨Çř
·˝·¨ÇřĘôÓÚĎ̹߳˛ĎíµÄÄÚ´ćÇřÓňŁ¬ÓÖłĆNon-HeapŁ¨·Ç¶ŃŁ©Ł¬Ö÷ŇŞÓĂÓÚ´ć´˘Ňѱ»ĐéÄâ»úĽÓÔصÄŔŕĐĹϢˇ˘łŁÁżˇ˘ľ˛Ě¬±äÁżˇ˘Ľ´Ę±±ŕŇëĆ÷±ŕŇëşóµÄ´úÂëµČĘýľÝŁ¬¸ůľÝJava ĐéÄâ»úąć·¶µÄąć¶¨Ł¬µ±·˝·¨ÇřÎŢ·¨Âú×ăÄÚ´ć·ÖĹäĐčÇóʱŁ¬˝«Ĺ׳öOutOfMemoryError Ň쳣ˇŁ
ÖµµĂעŇâµÄĘÇÔÚ·˝·¨ÇřÖĐ´ćÔÚŇ»¸ö˝ĐÔËĐĐʱłŁÁżłŘ(Runtime Constant PoolŁ©µÄÇřÓňŁ¬ËüÖ÷ŇŞÓĂÓÚ´ć·Ĺ±ŕŇëĆ÷ÉúłÉµÄ¸÷ÖÖ×ÖĂćÁżşÍ·űşĹŇýÓĂŁ¬ŐâĐ©ÄÚČÝ˝«ÔÚŔŕĽÓÔŘşó´ć·Ĺµ˝ÔËĐĐʱłŁÁżłŘÖĐŁ¬ŇÔ±ăşóĐřĘąÓáŁ
JVM¶Ń
Java ¶ŃҲĘÇĘôÓÚĎ̹߳˛ĎíµÄÄÚ´ćÇřÓňŁ¬ËüÔÚĐéÄâ»úĆô¶ŻĘ±´´˝¨Ł¬ĘÇJava ĐéÄâ»úËůąÜŔíµÄÄÚ´ćÖĐ×î´óµÄŇ»żéŁ¬Ö÷ŇŞÓĂÓÚ´ć·Ĺ¶ÔĎóʵŔýŁ¬Ľ¸şőËůÓеĶÔĎóʵŔý¶ĽÔÚŐâŔď·ÖĹäÄڴ棬עŇâJava ¶ŃĘÇŔ¬»řĘŐĽŻĆ÷ąÜŔíµÄÖ÷ŇŞÇřÓňŁ¬Ňň´ËşÜ¶ŕʱşňҲ±»łĆ×öGC ¶ŃŁ¬ČçąűÔÚ¶ŃÖĐĂ»ÓĐÄÚ´ćÍęłÉʵŔý·ÖĹ䣬˛˘ÇҶŃҲÎŢ·¨ÔŮŔ©ŐąĘ±Ł¬˝«»áĹ׳öOutOfMemoryError Ň쳣ˇŁ
łĚĐňĽĆĘýĆ÷
ĘôÓÚĎßłĚË˝ÓеÄĘýľÝÇřÓňŁ¬ĘÇһСżéÄÚ´ćżŐĽäŁ¬Ö÷ŇŞ´ú±íµ±Ç°ĎßłĚËůÖ´ĐеÄ×Ö˝ÚÂëĐĐşĹָʾĆ÷ˇŁ×Ö˝ÚÂë˝âĘÍĆ÷ą¤×÷ʱŁ¬Í¨ąý¸Ä±äŐâ¸öĽĆĘýĆ÷µÄÖµŔ´ŃˇČˇĎÂŇ»ĚőĐčŇŞÖ´ĐеÄ×Ö˝ÚÂëÖ¸Á·ÖÖ§ˇ˘Ń»·ˇ˘Ěřתˇ˘Ň쳣´¦Ŕíˇ˘Ďָ̻߳´µČ»ů´ˇą¦ÄܶĽĐčŇŞŇŔŔµŐâ¸öĽĆĘýĆ÷Ŕ´ÍęłÉˇŁ
ĐéÄâ»úŐ»
ĘôÓÚĎßłĚË˝ÓеÄĘýľÝÇřÓňŁ¬ÓëĎßłĚͬʱ´´˝¨Ł¬×ÜĘýÓëĎ̹߳ŘÁŞŁ¬´ú±íJava·˝·¨Ö´ĐеÄÄÚ´ćÄŁĐ͡ŁĂż¸ö·˝·¨Ö´ĐĐʱ¶Ľ»á´´˝¨Ň»¸öŐ»čĺŔ´´ć´˘·˝·¨µÄµÄ±äÁż±íˇ˘˛Ů×÷ĘýŐ»ˇ˘¶ŻĚ¬Á´˝Ó·˝·¨ˇ˘·µ»ŘÖµˇ˘·µ»ŘµŘÖ·µČĐĹϢˇŁĂż¸ö·˝·¨´Óµ÷ÓĂÖ±˝áĘřľÍ¶ÔÓÚŇ»¸öŐ»čĺÔÚĐéÄâ»úŐ»ÖеÄČëŐ»şÍłöŐ»ąýłĚŁ¬ČçĎÂŁ¨ÍĽÓĐÎóŁ¬Ó¦¸ĂÎŞŐ»č壩Łş
±ľµŘ·˝·¨Ő»
±ľµŘ·˝·¨Ő»ĘôÓÚĎßłĚË˝ÓеÄĘýľÝÇřÓňŁ¬Őⲿ·ÖÖ÷ŇŞÓëĐéÄâ»úÓõ˝µÄ Native ·˝·¨ĎŕąŘŁ¬Ň»°ăÇéżöĎÂŁ¬ÎŇĂÇÎŢĐčąŘĐÄ´ËÇřÓňˇŁ
С˝á
ŐâŔďÖ®ËůŇÔĽňҪ˵Ă÷Őⲿ·ÖÄÚČÝŁ¬×˘ŇâĘÇÎŞÁËÇř±đJavaÄÚ´ćÄŁĐÍÓëJavaÄÚ´ćÇřÓňµÄ»®·ÖŁ¬±ĎľąŐâÁ˝ÖÖ»®·ÖĘÇĘôÓÚ˛»Í¬˛ă´ÎµÄ¸ĹÄ
JavaÄÚ´ćÄŁĐ͸ĹĘö
JavaÄÚ´ćÄŁĐÍ(Ľ´Java Memory ModelŁ¬ĽňłĆJMM)±ľÉíĘÇŇ»ÖÖłéĎóµÄ¸ĹÄ˛˘˛»Őćʵ´ćÔÚŁ¬ËüĂčĘöµÄĘÇŇ»×éąćÔň»ňąć·¶Ł¬Í¨ąýŐâ×éąć·¶¶¨ŇĺÁËłĚĐňÖи÷¸ö±äÁżŁ¨°üŔ¨ĘµŔý×ֶΣ¬ľ˛Ě¬×ֶκ͹ąłÉĘý×é¶ÔĎóµÄÔŞËŘŁ©µÄ·ĂÎĘ·˝Ę˝ˇŁ
ÓÉÓÚJVMÔËĐĐłĚĐňµÄʵĚĺĘÇḌ̌߳¬¶řĂż¸öĎ̴߳´˝¨Ę±JVM¶Ľ»áÎŞĆä´´˝¨Ň»¸öą¤×÷ÄÚ´ć