
上图的意思: 百战百胜,屡试不爽。
故事

程序员小张: 刚毕业,参加工作1年左右,日常工作是CRUD

架构师老李: 多个大型项目经验,精通各种开发架构屠龙宝术;
小张注意到,在实际的项目开发场景中,很多开发人员只关注编写SQL脚本来满足功能需求,而忽略了脚本的可重复执行性。
这就意味着,如果脚本中的某个部分执行失败,运维人员就必须从头提供一个新的脚本,这对运维团队和开发人员来说是一个挑战。
因此,小张决定研究如何编写基于MySQL的可以重复执行的SQL脚本,以提高开发效率和简化运维流程。
他向公司的架构师老李咨询了这个问题。老李是一位经验丰富的架构师,
他在多个大型项目中积累了许多宝贵的经验,精通各种开发架构屠龙宝术。
老李听了小张的问题后,笑了笑并开始给予指导。他向小张解释了如何编写一个具有可重复执行性的SQL脚本,并分享了以下几个关键点:
a.使用事务:事务是一组SQL语句的逻辑单元,可以保证这组语句要么全部执行成功,要么全部回滚。
通过使用事务,可以确保脚本的所有修改操作要么完整地执行,要么不执行。
b.使用条件检查:在每个需要修改数据的语句之前,添加条件检查以确保只有当数据不存在或满足特定条件时才进行修改。
这样可以避免重复插入相同的数据,或者执行不必要的更新操作。
c.错误处理:在编写脚本时,考虑到可能出现的错误情况,并提供适当的错误处理机制。例如,使用IF...ELSE语句来处理特定条件下的执行逻辑。
d.使用存储过程:如果脚本非常复杂,包含多个步骤和业务逻辑,可以考虑将它们封装为存储过程。这样可以更好地组织和管理代码,并提高脚本的可读性和维护性。
小张听得津津有味,他开始将老李的建议付诸实践。他仔细研究每个SQL语句,根据老李的指导进行修改和优化。
他使用了事务来包裹整个脚本,添加了条件检查来避免重复插入数据,并实现了错误处理机制以应对异常情况。
背景
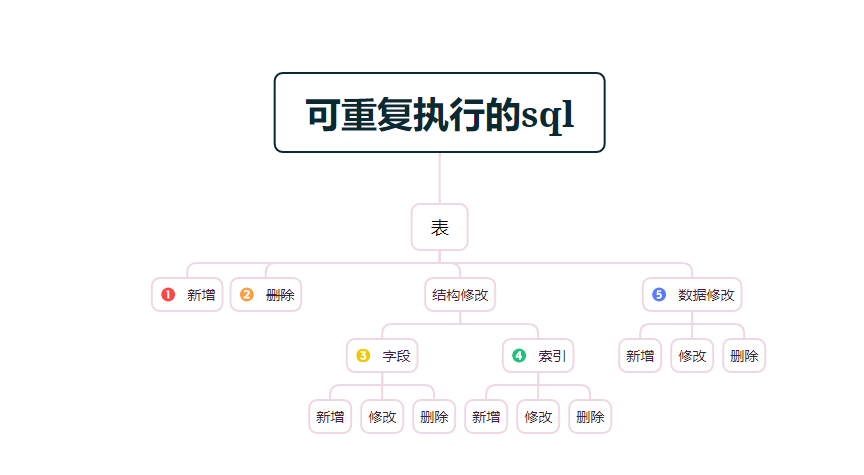
所以开发提供给到运维的SQL脚本有一定基本要求:
1.能重复执行;
2.不出错,(不报错,逻辑正确);
如果脚本不可重复执行,则运维无法自动化,会反过来要求后端开发人员给出适配当前环境的新的SQL脚本,增加了运维和沟通成本。
那么怎么写可重复执行的SQL脚本呢?
分成4个场景,来介绍举例。
1 创建表
create table if not exists nginx_config (
id varchar(36) not null default '' comment 'UUID',
namespace varchar(255) not null default '' comment '环境命名空间',
config_content text comment "nginx http块配置",
content_md5 varchar(64) not null default '' comment '配置内容的MD5值',
manipulator varchar(64) not null default '' comment '操作者',
description varchar(512) not null default '' comment '描述',
gmt_created bigint unsigned not null default 0 comment '创建时间',
primary key(id)
)ENGINE=InnoDB comment 'nginx配置表' ;
删除表在生产环境是禁止的。
备份方式修改表名
修改表名: 先创建新表,再copy历史数据进去,不允许删除表;
DELIMITER //
drop procedure if exists modify_table_name;
CREATE PROCEDURE modify_table_name(
IN table_name VARCHAR(255),
IN new_name VARCHAR(255)
)
BEGIN
DECLARE database_name VARCHAR(255);
DECLARE table_exists INT DEFAULT 0;
DECLARE new_table_exists INT DEFAULT 0;
SELECT DATABASE() INTO database_name;
set @db_table_name=concat(database_name,'/',table_name);
select count(t1.TABLE_ID) INTO table_exists from information_schema.INNODB_TABLES t1 where t1.NAME=@db_table_name ;
set @db_table_name_new=concat(database_name,'/',new_name);
select count(t1.TABLE_ID) INTO new_table_exists from information_schema.INNODB_TABLES t1 where t1.NAME=@db_table_name_new ;
IF table_exists = 1 AND new_table_exists = 0 THEN
SET @query = CONCAT('create table ',new_name,' like ',table_name);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @query = CONCAT('insert into ', new_name, ' select * from ',table_name);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT 'table name modify successfully.' AS result ,@db_table_name,@db_table_name_new,table_exists,new_table_exists;
ELSE
SELECT 'table name not exists or new_name already exists.' AS result,@db_table_name,@db_table_name_new,table_exists,new_table_exists;
END IF;
END //
DELIMITER ;
测试脚本:
create table user(id bigint auto_increment primary key ,name varchar(30),age tinyint)comment 'user表';
insert into user(id, name, age) VALUES (1,'a',1),(2,'b',2),(3,'c',3);
call modify_table_name('user','user1');
select * from user1;
call modify_table_name('user','user2');
select * from user2;
测试结果符合预期。
新增修改删除字段
drop procedure if exists modify_table_field;
CREATE PROCEDURE modify_tabl