Kafka 是一个基于发布-订阅模式的消息系统,它可以在多个生产者和消费者之间传递大量的数据。Kafka 的一个显著特点是它的高吞吐率,即每秒可以处理百万级别的消息。那么 Kafka 是如何实现这样高得性能呢?本文将从七个方面来分析 Kafka 的速度优势。
- 零拷贝技术
- 仅可追加日志结构
- 消息批处理
- 消息批量压缩
- 消费者优化
- 未刷新的缓冲写入
- GC 优化
以下是对本文中使用得一些英文单词得解释:
Broker:Kafka 集群中的一台或多台服务器统称 broker
Producer:消息生产者
Consumer:消息消费者
zero copy:零拷贝
1. 零拷贝技术
零拷贝技术是指在读写数据时,避免将数据在内核空间和用户空间之间进行拷贝,而是直接在内核空间进行数据传输。对于 Kafka 来说,它使用了零拷贝技术来加速磁盘文件的网络传输,以提高读取速度和降低 CPU 消耗。下图说明了数据如何在生产者和消费者之间传输,以及零拷贝原理。
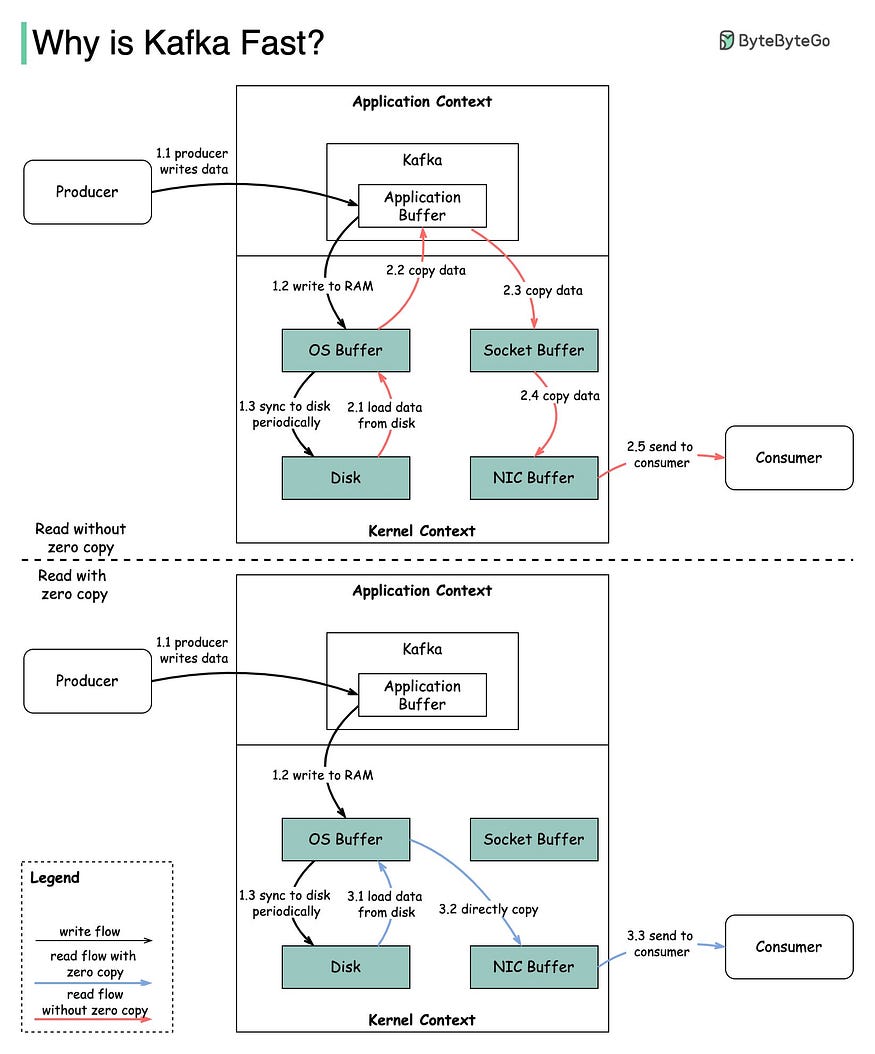
步骤 1.1~1.3:生产者将数据写入磁盘
步骤 2:消费者不使用零拷贝方式读取数据
2.1:数据从磁盘加载到 OS 缓存
2.2:将数据从 OS 缓存复制到 Kafka 应用程序
2.3:Kafka 应用程序将数据复制到 socket 缓冲区
2.4:将数据从 socket 缓冲区复制到网卡
2.5:网卡将数据发送给消费者
步骤 3:消费者以零拷贝方式读取数据
3.1:数据从磁盘加载到 OS 缓存
3.2:OS 缓存通过 sendfile() 命令直接将数据复制到网卡
3.3:网卡将数据发送到消费者
可以看到,零拷贝技术避免了多余得两步操作,数据直接从OS 缓存复制到网卡再到消费者。这样做的好处是极大地提高了I/O效率,降低了CPU和内存的消耗。
推荐博主开源的 H5 商城项目waynboot-mall,这是一套全部开源的微商城项目,包含三个项目:运营后台、H5 商城前台和服务端接口。实现了商城所需的首页展示、商品分类、商品详情、商品 sku、分词搜索、购物车、结算下单、支付宝/微信支付、收单评论以及完善的后台管理等一系列功能。 技术上基于最新得 Springboot3.0、jdk17,整合了 MySql、Redis、RabbitMQ、ElasticSearch 等常用中间件。分模块设计、简洁易维护,欢迎大家点个 star、关注博主。
github 地址:https://github.com/wayn111/waynboot-mall
2. 仅可追加日志结构
Kafka 中存在大量的网络数据持久化到磁盘(生产者到代理)和磁盘文件通过网络发送(代理到消费者)的过程。这一过程的性能会直接影响 Kafka 的整体吞吐量。为了优化 Kafka 的数据存储和传输,Kafka 采用了一种仅可追加日志结构方式来持久化数据。仅可追加日志结构是指将数据以顺序追加(append-only)的方式写入到文件中,而不是进行随机写入或更新。这样做的好处是可以减少磁盘 I/O 的开销,提高写入速度。
人们普遍认为磁盘的读写速度很慢,但实际上存储介质(尤其是旋转介质)的性能很大程度上取决于访问模式。常见的 7,200 RPM SATA 磁盘上的随机 I / O 的性能要比顺序 I / O 慢 3 ~ 4 个数量级。此外,现代操作系统提供了预读和延迟写入技术,可以预先取出大块的数据,并将较小的逻辑写入组合成较大的物理写入。因此,即使在闪存和其他形式的固态非易失性介质中,随机 I/O 和顺序 I/O 的差异仍然很明显,尽管与旋转介质相比,这种差异性已经很小了。
3. 消息批处理
Kafka 的高吞吐率设计的核心要点之一是批处理,即 Kafka 在消息发送端和接收端都引入了一个缓冲区,将多条消息打包成一个批次(Batch),然后一次性发送或接收。这样做的好处是可以减少网络请求的次数,减少了网络压力,提高了传输效率。
Kafka 的消息批处理优化主要涉及以下几个方面:
发送端(Producer)
Kafka 的 Producer 只提供了单条发送的 send()方法,并没有提供任何批量发送的接口。当调用 send()方法发送一条消息之后,无论是同步还是异步发送,这条消息不会立即发送出去,而是先放入到一个双端队列中,然后 Kafka 使用一个异步线程从队列中成批发送消息。
Kafka 提供了以下几个参数来控制发送端的批处理策略:
- batch.size:指定每个批次可以收集的消息数量的最大值。默认是 16KB。
- buffer.memory:指定每个 Producer 可以使用的缓冲区内存的总量。默认是 32MB。
- linger.ms:指定每个批次可以等待的时间的最大值。默认是 0ms。
- compression.type:指定是否对每个批次进行压缩,以及使用哪种压缩算法。默认是 none。
接收端(Broker)
Kafka 的 Broker 在接收到 Producer 发送过来的批次后,不会把批次再还原成多条消息,而是直接将整个批次写入到磁盘中。这样做的好处是可以减少磁盘 I/O 的开销,提高写入速度。
Kafka 利用了操作系统提供的内存映射文件(memory mapped file)功能,将文件映射到内存中,使得对文件的读写操作就相当于对内存的读写操作。这样就避免了用户空间和内核空间之间的数据拷贝,也避免了系统调用的开销。
消费端(Consumer)
Kafka 的 Consumer 在从 Broker 拉取数据时,也是以批次为单位进行传递的。Consumer 从 Broker 拉到一批消息后,客户端把批次解开,再一条一条交给用户代码处理。
Kafka 提供了以下几个参数来控制消费端的批处理策略:
- fetch.min.bytes:指定每次拉取请求至少要获取多少字节的数据。默认是 1B。
- fetch.max.bytes:指定每次拉取请求最多能获取多少字节的数据。默认是 50MB。
- fetch.max.wait.ms:指定每次拉取请求最多能等待多长时间。默认是 500ms。
- max.partition.fetch.bytes:指定每个分区每次拉取请求最多能获取多少字节的数据。默认是 1MB。
4. 消息批量压缩
消息批量压缩通常与消息批处理一起使用。Kafka 会将多个消息打包成一个批次(Batch),并对批次进行压缩(例如使用 gzip 或 snappy 算法),然后再发送给消费者。这样做的好处是可以节省网络带宽,提高传输效率。
当然,压缩也有一定的代价,即需要消耗 CPU 资源来进行压缩和解压缩。但是对于 Kafka 这样的高吞吐量的系统来说,网络带宽往往是更大的瓶颈,所以压缩是值得的。
Kafka 还提供了一种灵活的压缩策略,即可以让生产者、代理和消费者之间协商压缩格式和级别。生产者可以选择是否对消息进行压缩,以及使用哪种压缩算法;代理可以选择是否保留生产者压缩的消息,或者对其进行重新压缩;消费者可以选择是否对收到的消息进行解压缩。这样可以根据不同的场景和需求来平衡性能和资源的消耗。
5. 消费者优化
Kafka 的消费者是基于拉模式(pull)的,即消费者主动向服务器请求数据,而不是服务器主动推送数据给消费者。这样做的好处是可以让消费者自己控制消费的速度和时机,也可以减轻服务器的负担,提高整体的吞吐量。
Kafka 的消费者所实现的功能是比较简洁的,即它们不需要维护太多的状态和资源,也不需要和服务器进行复杂的交互。K