ownload the web driver binaries
# then we can use `Service` to manage the web driver's state.
from webdriver_manager.chrome import ChromeDriverManager
def extract_data(row):
name = row.find_element(By.TAG_NAME, "h3").text.strip("\n").strip()
capital = row.find_element(By.CSS_SELECTOR, "span.country-capital").text
population = row.find_element(By.CSS_SELECTOR, "span.country-population").text
area = row.find_element(By.CSS_SELECTOR, "span.country-area").text
return {"name": name, "capital": capital, "population": population, "area (km sq)": area}
# start the timer
start = time.time()
options = webdriver.ChromeOptions()
options.headless = True
# this returns the path web driver downloaded
chrome_path = ChromeDriverManager().install()
# define the chrome service and pass it to the driver instance
chrome_service = Service(chrome_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
url = "https://www.scrapethissite.com/pages/"
driver.get(url)
# get the first page and click to the link
first_page = driver.find_element(By.CSS_SELECTOR, "h3.page-title a")
first_page.click()
# get the data div and extract the data using beautifulsoup
countries_container = driver.find_element(By.CSS_SELECTOR, "section#countries div.container")
countries = driver.find_elements(By.CSS_SELECTOR, "div.country")
# scrape the data using extract_data function
data = list(map(extract_data, countries))
end = time.time()
print(f"The whole script took: {end-start:.4f}")
driver.quit()
测试结果:
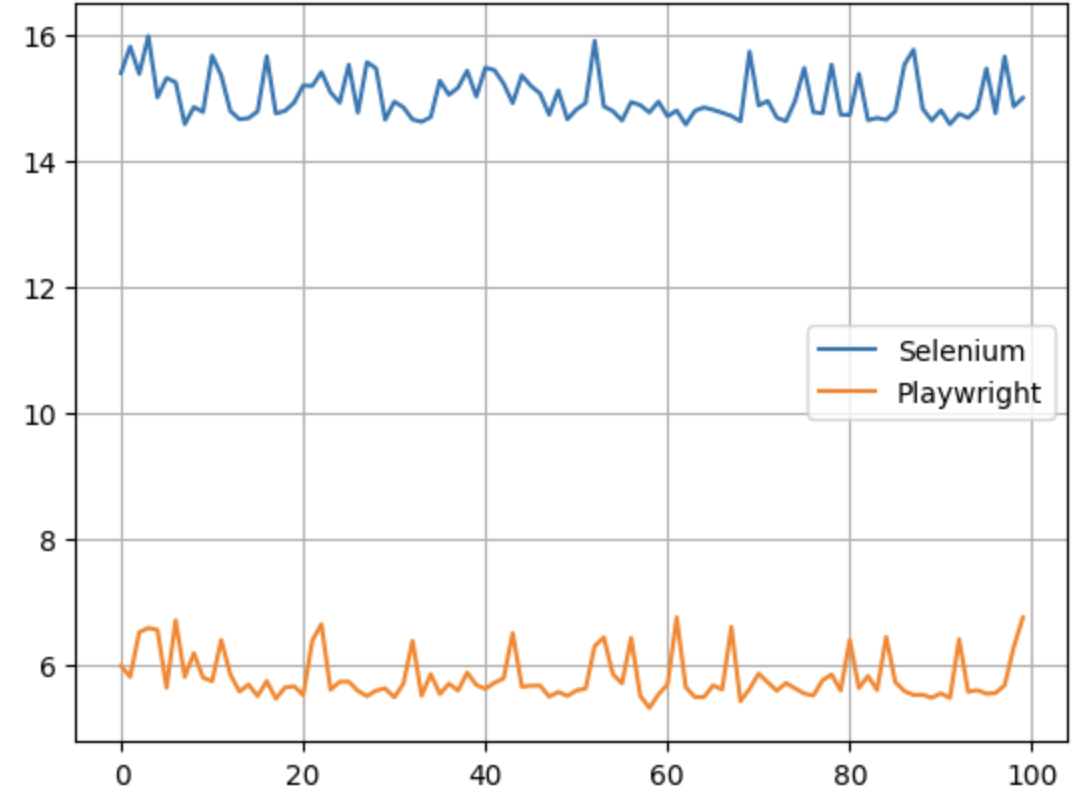
Y轴是执行时间,一望而知,Selenium比PlayWright差了大概五倍左右。
红玫瑰还是白玫瑰?
不得不承认,Playwright 和 Selenium 都是出色的自动化无头浏览器工具,都可以完成爬虫任务。我们还不能断定那个更好一点,所以选择那个取决于你的网络抓取需求、你想要抓取的数据类型、浏览器支持和其他考虑因素:
Playwright 不支持真实设备,而 Selenium 可用于真实设备和远程服务器。
Playwright 具有内置的异步并发支持,而 Selenium 需要第三方工具。
Playwright 的性能比 Selenium 高。
Selenium 不支持详细报告和视频录制等功能,而 Playwright 具有内置支持。
Selenium 比 Playwright 支持更多的浏览器。
Selenium 支持更多的编程语言。
结语
如果您看完了本篇文章,那么到底谁是最好的无头浏览器工具,答案早已在心间,所谓强中强而立强,只有弱者才害怕竞争,相信PlayWright的出现会让Selenium变为更好的自己,再接再厉,再创辉煌。