h.extra.nextOverflow = nextOverflow
}
}
在哈希表扩容的过程中,我们会通过 makeBucketArray 创建新的桶数组和一些预创建的溢出桶,随后对将原有的桶数组设置到 oldbuckets 上并将新的空桶设置到 buckets 上,原有的溢出桶也使用了相同的逻辑进行更新。
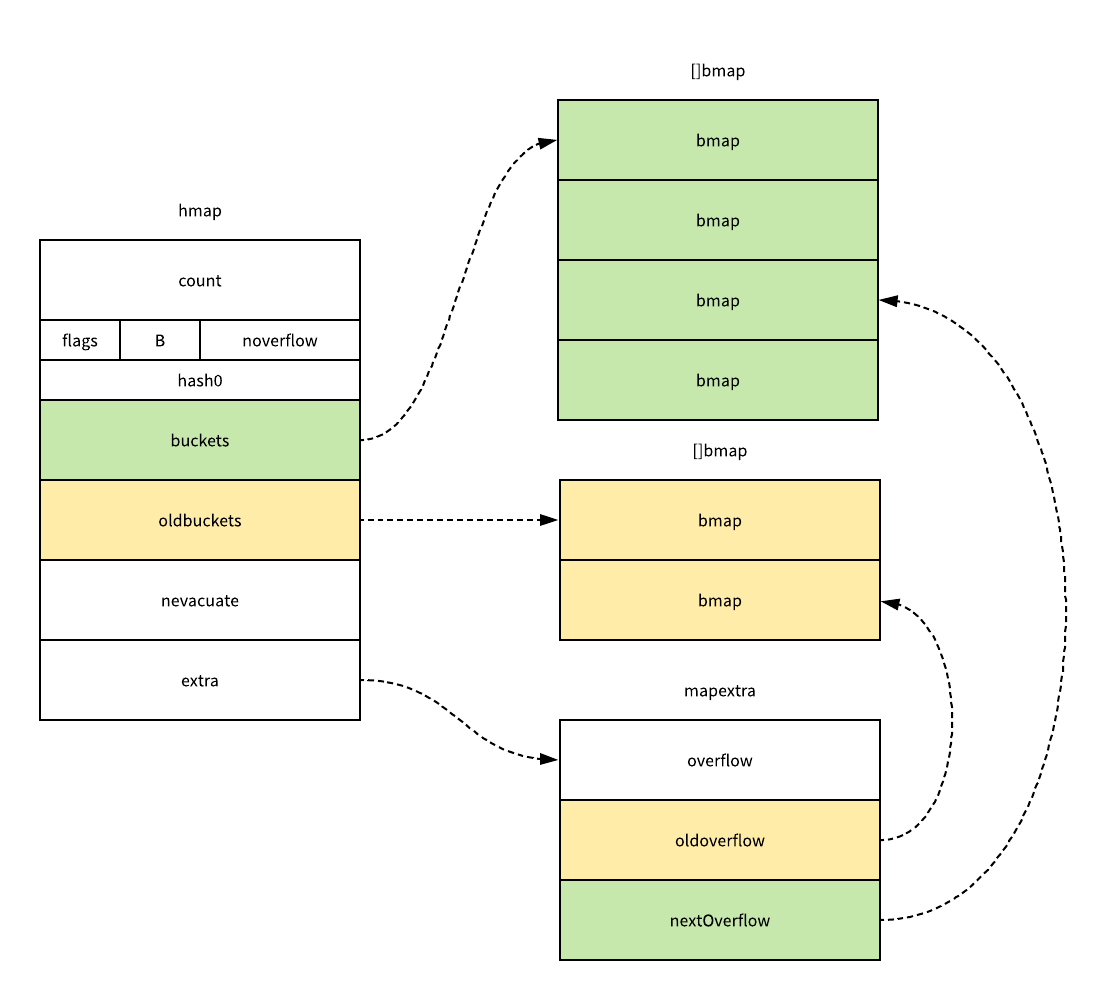
我们在上面的函数中还看不出来 sameSizeGrow 导致的区别,因为这里其实只是创建了新的桶并没有对数据记性任何的拷贝和转移,哈希表真正的『数据迁移』的执行过程其实是在 evacuate 函数中进行的,evacuate 函数会对传入桶中的元素进行『再分配』。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}
evacuate 函数在最开始时会创建一个用于保存分配目的 evacDst 结构体数组,其中保存了目标桶的指针、目标桶存储的元素数量以及当前键和值存储的位置。

如果这是一次不改变大小的扩容,这两个 evacDst 结构体只会初始化一个,当哈希表的容量翻倍时,一个桶中的元素会被分流到新创建的两个桶中,这两个桶同时会被 evacDst 数组引用,下面就是元素分流的逻辑:
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
k2 := k
var useY uint8
if !h.sameSizeGrow() {
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if hash&newbit != 0 {
useY = 1
}
}
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.key, dst.k, k)
typedmemmove(t.elem, dst.v, v)
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
如果新的哈希表中有八个桶,在大多数情况下,原来经过桶掩码结果为一的数据会因为桶掩码增加了一位而被分留到了新的一号桶和五号桶,所有的数据也都会被 typedmemmove 拷贝到目标桶的键和值所在的内存空间:
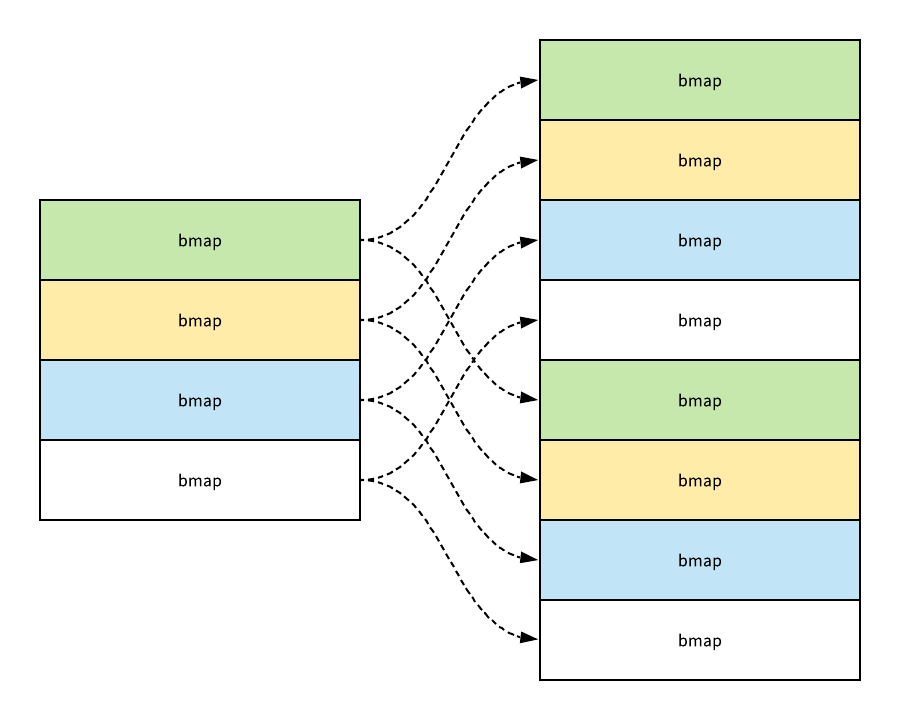
该函数的最后会调用 advanceEvacuationMark 函数,它会增加哈希的 nevacuate 计数器,然后在所有的旧桶都被分流后删除这些无用的数据,然而因为 Go 语言数据的迁移过程不是一次性执行完毕的,它只会在写入或者删除时触发 evacuate 函数增量完成的,所以不会瞬间对性能造成影响。
在之前的哈希表访问接口中其实省略一段从 oldbuckets 中获取桶的代码,这段代码就是扩容期间获取桶的逻辑,当哈希表的 oldbuckets 存在时,就会根据地址定位到以前的桶并且在当前桶未被 evacuate 时使用该桶。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
bucketloop:
// ...
}
上述代码的作用就是在过去的桶没有被 evacuate 时暂时取代新桶接受读请求,因为历史的桶中还没有被处理,还保存着我们需要使用的数据,所以在这里会直接取代新创建的空桶。
另一段代码就在写请求执行的过程中,当哈希表正在处于扩容的状态时,每次设置哈希表的值时都会触发 growWork 对哈希表的内容进行增量拷贝:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
// ...
}
当然除了除了写入操作之外,所有的删除操作也都会在哈希表扩容期间触发 growWork,触发的方式和代码与这里的逻辑几乎完全相同,都是计算当前值所在的桶,然后对该桶中的元素进行拷贝。
删除
想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键的唯一作用就是将某一个键