|
深度解密Go语言之Slice(三)
|
0 |
准备 Println 函数参数。共3个参数,第一个是类型地址,还有两个 1,这块暂时还不知道为什么要传,有了解的同学可以在文章后面留言 |
所以调用 fmt.Println(slice) 时,实际是传入了一个 slice类型的eface地址。这样,Println就可以访问类型中的数据,最终给“打印”出来。

最后,我们看下 main 函数栈帧的开始和收尾部分。
0x0013 00019 (main.go:5)SUBQ $96, SP
0x0017 00023 (main.go:5)MOVQ BP, 88(SP)
0x001c 00028 (main.go:5)LEAQ 88(SP), BP
…………………………
0x00d3 00211 (main.go:9)MOVQ 88(SP), BP
0x00d8 00216 (main.go:9)ADDQ $96, SP
RET
BP可以理解为保存了当前函数栈帧栈底的地址,SP则保存栈顶的地址。
初始,BP 和 SP 分别有一个初始状态。
main 函数执行的时候,先根据 main 函数栈帧大小确定 SP 的新指向,使得 main 函数栈帧大小达到 96B。之后把老的 BP 保存到 main 函数栈帧的底部,并使 BP 寄存器重新指向新的栈底,也就是 main 函数栈帧的栈底。
最后,当 main 函数执行完毕,把它栈底的 BP 给回弹回到 BP 寄存器,恢复调用前的初始状态。一切都像是没有发生一样,完美的现场。

这部分,又详细地分析了一遍函数调用的过程。一方面,让大家复习一下上一篇文章讲的内容;另一方面,向大家展示如何找到 Go 中的一个函数背后真实调用了哪些函数。像例子中,我们就看到了 make 函数背后,实际上是调用了 makeslice 函数;还有一点,让大家对汇编不那么“惧怕”,可以轻松地分析一些东西。
截取
截取也是比较常见的一种创建 slice 的方法,可以从数组或者 slice 直接截取,当然需要指定起止索引位置。
基于已有 slice 创建新 slice 对象,被称为 reslice。新 slice 和老 slice 共用底层数组,新老 slice 对底层数组的更改都会影响到彼此。基于数组创建的新 slice 对象也是同样的效果:对数组或 slice 元素作的更改都会影响到彼此。
值得注意的是,新老 slice 或者新 slice 老数组互相影响的前提是两者共用底层数组,如果因为执行 append 操作使得新 slice 底层数组扩容,移动到了新的位置,两者就不会相互影响了。所以,问题的关键在于两者是否会共用底层数组。
截取操作采用如下方式:
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[2:4:6] // data[low, high, max]
对 data 使用3个索引值,截取出新的 slice。这里 data 可以是数组或者 slice。low 是最低索引值,这里是闭区间,也就是说第一个元素是 data 位于 low 索引处的元素;而 high 和 max 则是开区间,表示最后一个元素只能是索引 high-1 处的元素,而最大容量则只能是索引 max-1 处的元素。
max >= high >= low
当 high == low 时,新 slice 为空。
还有一点,high 和 max 必须在老数组或者老 slice 的容量(cap)范围内。
来看一个例子,来自雨痕大佬《Go学习笔记》第四版,P43页,参考资料里有开源书籍地址。这里我会进行扩展,并会作详细说明:
package main
import "fmt"
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s2 = append(s2, 100)
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}
先看下代码运行的结果:
[2 3 20]
[4 5 6 7 100 200]
[0 1 2 3 20 5 6 7 100 9]
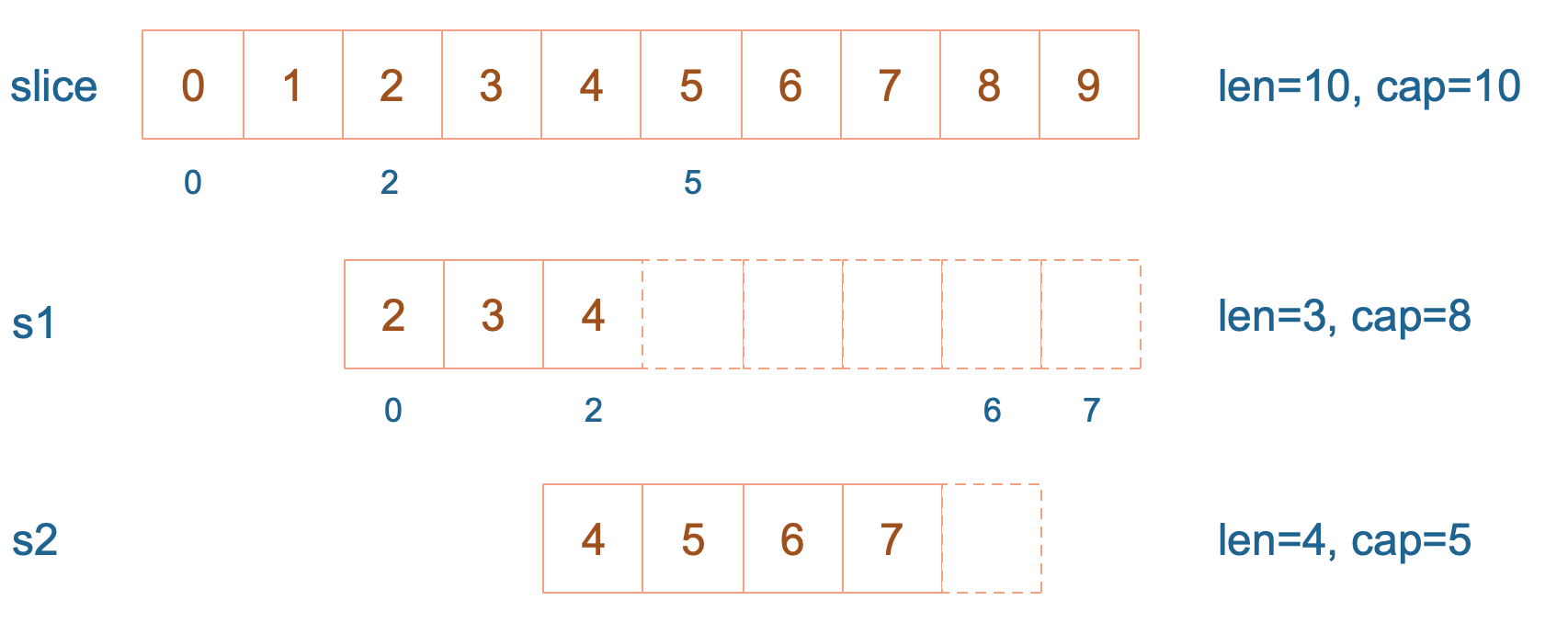
我们来走一遍代码,初始状态如下:
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。
s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
接着,向 s2 尾部追加一个元素 100:
s2 = append(s2, 100)
s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。

再次向 s2 追加元素200:
s2 = append(s2, 100)
这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
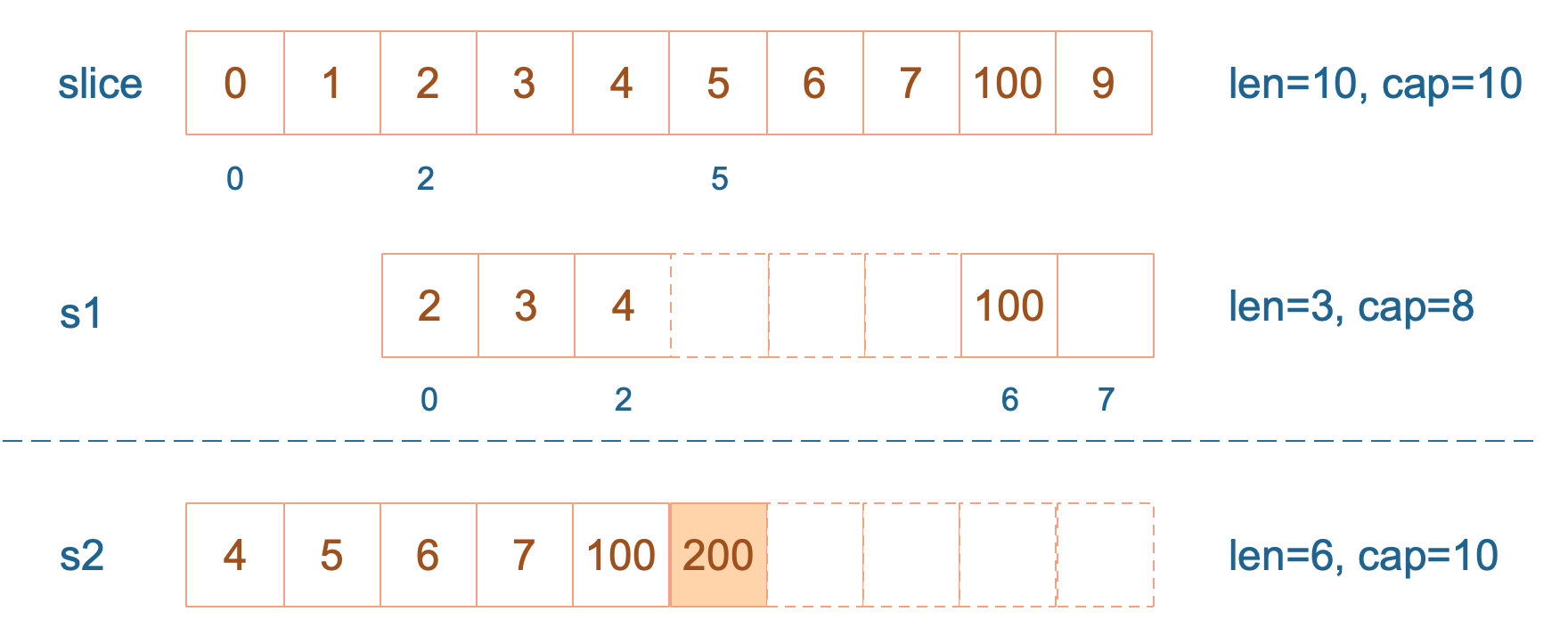
最后,修改 s1 索引为2位置的元素:
s1[2] = 20
这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
![s1[2]=20](https://user-images.githubusercontent.com/7698088/54961330-29200400-4f9b-11e9-88d0-a29308a818ae.png)
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
至于,我们想在汇编层面看看到底它们是如何共享底层数组的,限于篇幅,这里不再展开。感兴趣的同学可以在公众号后台回复:切片截取。
我会给你详细分析函数调用关系,对共享底层数组的行为也会一目了然。二维码见文章底部。
slice 和数组的区别在哪
slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
append 到底做了什么
先来看看 append 函数的原型:
func append(slice []Type, elems ...Type) []Type
append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 ... 传入 slice,直接追加一个切片。
slice = append(slice, elem1, elem2)
slice = append(slice, anotherSlice...)
append函数返回值是一个新的slice,Go编译器不允许调用了 append 函数后不使用返回值。
append(slice, elem1, elem2)
append(slice, anotherSlice...)
所以上面的用法是错的,不能编译通过。
使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素。但是底层数组的长度是固定的,如果索引 len-1 所指向的元素已经是底层数组的最后一个元素,就没法再添加了。
这时,slice 会迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度, |