0.1、索引
https://waterflow.link/articles/1666449874974
1、字符串编码
在go中rune是一个unicode编码点。
我们都知道UTF-8将字符编码为1-4个字节,比如我们常用的汉字,UTF-8编码为3个字节。所以rune也是int32的别名。
type rune = int32
当我们打印一个英文字符hello的时候,我们可以得到s的长度为5,因为英文字母代表1个字节:
package main
import "fmt"
func main() {
s := "hello"
fmt.Println(len(s)) // 5
}
但是当我们打印嗨的时候,会打印3个字节。因为使用UTF-8,这个字符会被编码成3个字节:
package main
import "fmt"
func main() {
s := "嗨"
fmt.Println(len(s)) // 3
}
所以,我们使用len内置函数输出的并不是字符数,而是字节数。
下面看一个有趣的例子,我们都知道汉字符使用3个字节编码,分别是0xE5, 0x97, 0xA8。我们运行下面代码会得到汉字嗨:
package main
import "fmt"
func main() {
s := string([]byte{0xE5, 0x97, 0xA8})
fmt.Println(s) // 嗨
}
所以我们需要知道:
- 字符集是一组字符,而编码描述了如何将字符集转换为二进制
- 在 Go 中,字符串引用任意字节的不可变切片
- Go 源码使用 UTF-8 编码。 因此,所有字符串文字都是 UTF-8 字符串。 但是因为字符串可以包含任意字节,如果它是从其他地方(不是源码)获得的,则不能保证它是基于 UTF-8 编码的
- 使用 UTF-8,一个 Unicode 字符可以编码为 1 到 4 个字节
- 在 Go 中对字符串使用 len 返回字节数,而不是字符数
2、字符串遍历
我们在开发中经常会用到对字符串进行遍历的场景。 也许我们想对字符串中的每个 rune 执行一个操作,或者实现一个自定义函数来搜索特定的子字符串。 在这两种情况下,我们都必须遍历字符串的不同字符。 但往往会得到让我们意想不到的结果。
我们看下下面的例子,打印一个字符串中的不同字符和对应的位置:
package main
import "fmt"
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
我们想要的效果是通过遍历字符串,打印出每个字符的索引。但是我们却得到了一个特殊的字符å,其实我们想要的是嗨。
但是打印的字节数是符合我们的预期的,因为嗨是一个中文占用了3个字节,所以len返回的是7。
3、字符串中的字符数
如果我们想要正确的获取字符串的字符数,可以使用go中的utf8包:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s)) // 获取字符数
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
在这个例子中,可以看到,我们确实遍历了5次,也就是对应字符串的5个字符。但是我们获取到的索引其实是对应每个字符的起始位置。像下面这样

那我们如何打印出正确的结果呢?我们稍微修改下代码:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i, v := range s { // 此处改为获取v,可以获取到字符本身
fmt.Printf("字符位置 %d: %c\n", i, v)
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
另外一种方法就是把字符串转换成rune切片,这样也会正确打印结果:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
b := []rune(s)
for i := range b {
fmt.Printf("字符位置 %d: %c\n", i, b[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 2: l
字符位置 3: l
字符位置 4: o
len=7
rune len=5
下面是rune切片遍历的过程(中间省略了将字节转换为rune的过程,需要遍历字节,复杂度为O(n))
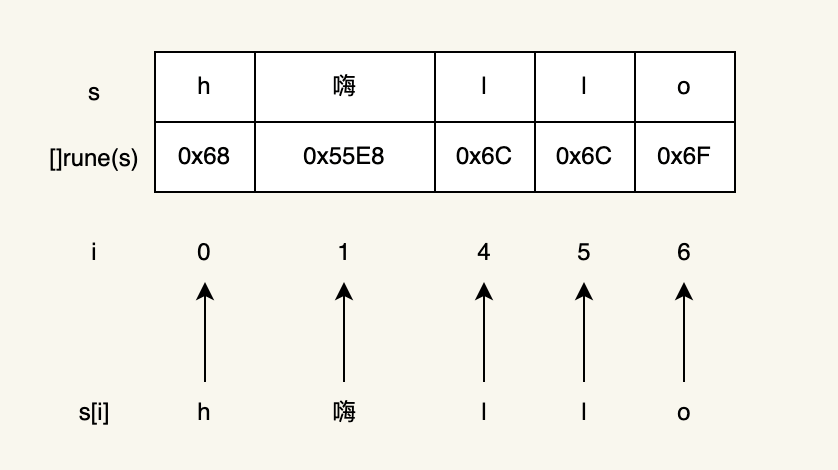
4、字符串trim
开发中我们经常会遇到去除字符串头部或者尾部字符的操作。比如我们现在有个字符串xohelloxo,现在我们想去除尾部的xo,可能我们会像下面这样写:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimRight(s, "xo")
fmt.Println(s)
}
go run 7.go
xohell
可以看到这不是我们期望的结果。我们可以看下TrimRight的工作原理:
- 从右侧取出第一个字符o,判断是否在xo中,在就移除
- 重复步骤1,知道不符合条件
所以就可以解释通了。当然和它相似的TrimLeft