lavaan简明教程 [中文翻译版]
译者注:此文档原作者为比利时Ghent大学的Yves Rosseel博士,lavaan亦为其开发,完全开源、免费。我在学习的时候顺手翻译了一下,向Yves的开源精神致敬。此翻译因偷懒部分删减,但也有增加,有错误请留言
「转载请注明出处」
目录
lavaan简明教程 [中文翻译版]
目录
摘要
- 在开始之前
- 安装lavaan包
- 模型语法
- 例1:验证性因子分析(CFA)
- 例2:结构方程(SEM)
- 更多关于语法的内容
6.1 固定参数
6.2 初值
6.3 参数标签
6.4 修改器
6.5 简单相等约束
6.6 非线性相等和不相等约束 - 引入平均值
- 结构方程的多组分析
8.1 在部分组中固定参数
8.2 约束一个参数使其在各组中相等
8.3 约束一组参数使其在各组中相等
8.4 测量不变性 - 增长曲线模型
- 使用分类变量
- 将协方差矩阵作为输入
- 估计方法,标准误差和缺失值
12.1 估计方法
12.2 最大似然估计
12.3 缺失值 - 间接效应和中介分析
- 修正指标
- 从拟合方程中提取信息
摘要
此教程首先介绍lavaan的基本组成部分:模型语法,拟合方程(CFA, SEM和growth),用来呈现结果的主要函数(summary, coef, fitted, inspect);
然后提供两个实例;
最后再讨论一些重要话题:均值结构模型(meanstructures),多组模型(multiple groups),增长曲线模型(growth curve models),中介分析(mediation analysis),分类数据(categorial data)等。
1. 在开始之前
在开始之前,有以下几点需要注意:
- lavaan包需要安装 3.0.0或更新版本的R。
- lavaan包仍处于未完成阶段,目前尚未实现的功能有:对多层数据的支持,对离散潜变量的支持,贝叶斯估计。
- 虽然目前是测试版,但是结果精确,语法成熟,可以放心使用。
- lavaan包对R语言预备知识要求很低。
- 此教程不等于参考手册,相关文档正在准备。
- lavaan包是完全免费开源的软件,不做任何承诺。
- 发现bug,到 https://groups.google.com/d/forum/lavaan/ 加组沟通。
2. 安装lavaan包
启动R,并输入:
install.packages("lavaan", dependencies = TRUE) # 安装lavaan包
library(lavaan) # 载入lavaan包出现以下提示,表示载入成功。

3. 模型语法
lavaan包的核心是描述整个模型的“模型语法”。这部分简单介绍语法,更多细节在接下来的示例中可见。
R环境下的回归方程有如下形式:
y ~ x1 + x2 + x3 + x4 # ~左边为因变量y在lavaan中,一个典型模型是一个回归方程组,其中可以包含潜变量,例如:
y ~ f1 + f2 + x1 + x2
f1 ~ f2 + f3
f2 ~ f3 + x1 + x2我们必须通过指示符=~(measured by)来“定义”潜变量。例如,通过以下方式来定义潜变量f1, f2和f3:
f1 =~ y1 + y2 + y3
f2 =~ y4 + y5 + y6
f3 =~ y7 + y8 + y9 + y10方差和协方差表示如下:
y1 ~~ y1 # 方差
y1 ~~ y2 # 协方差
f1 ~~ f2 # 协方差只有截距项的回归方程表达如下:
y1 ~ 1
f1 ~ 1以上4种公式种类(~, ~~, =~, ~ 1)组合成完整的模型语法,用单引号表示如下:
myModel <- ' # 主要回归方程
y1 + y2 ~ f1 + f2 + x1 + x2
f1 ~ f2 + f3
f2 ~ f3 + x1 + x2
# 定义潜变量
f1 =~ y1 + y2 + y3
f2 =~ y4 + y5 + y6
f3 =~ y7 + y8 + y9 + y10
# 方差和协方差
y1 ~~ y1
y1 ~~ y2
f1 ~~ f2
# 截距项
y1 ~ 1
f1 ~ 1如果模型很长,可以将模型(单引号之间的内容)储存入myModel.lav的txt文档中,用以下命令读取:
myModel <- readLines("/mydirectory/myModel.lav") # 这里需要绝对路径4. 例1:验证性因子分析(CFA)
lavaan包提供了一个内置数据集叫做HolzingerSwineford,输入以下命令查看数据集描述:
?HolzingerSwineford数据形式是这样的:

此数据集包含了来自两个学校的七、八年级孩子的智力能力测验分数。在我们的版本里,只包含原有26个测试中的9个,这9个测试分数作为9个测量变量分别对应3个潜变量:
- 视觉因子(visual)对应x1,x2,x3
- 文本因子(textual)对应x4,x5,x6
- 速度因子(speed)对应x7,x8,x9
模型如下图所示:
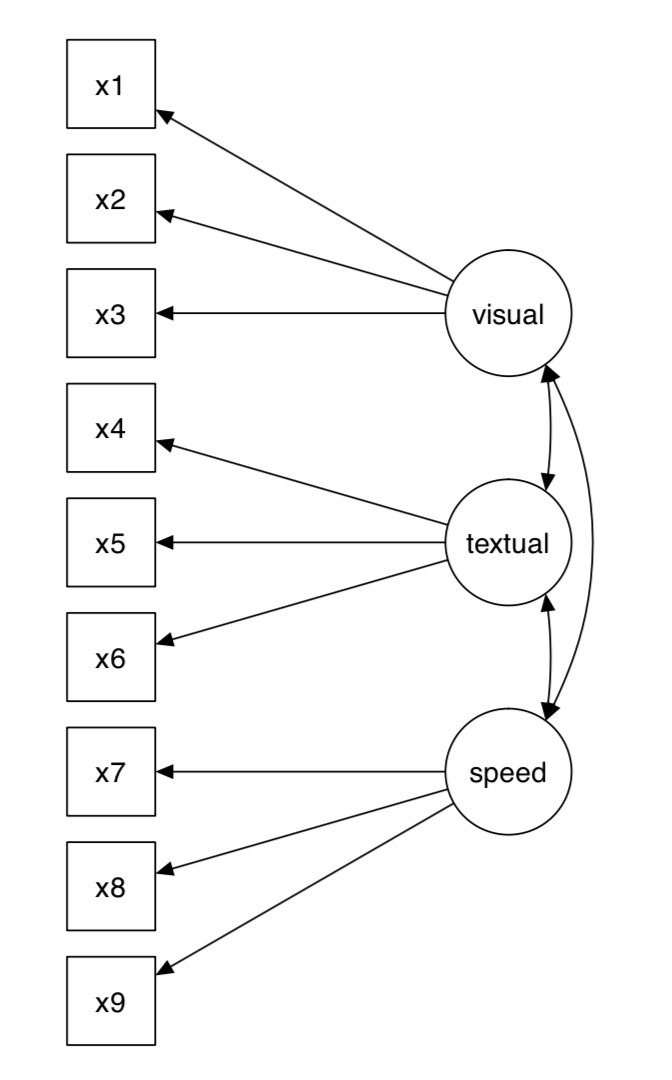
建立模型代码如下:
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9'
# 然后拟合cfa函数,第一个参数是模型,第二个参数是数据集
fit <- cfa(HS.model, data = HolzingerSwineford1939)
# 再通过summary函数给出结果
summary(fit, fit.measure = TRUE)结果展示如下:
# 前6行为头部,包含版本号,收敛情况,迭代次数,观测数,用来计算参数的估计量,模型检验统计量,自由度和相关的p值
lavaan (0.5-23.1097) converged normally after 35 iterations
Number of observations 301
Estimator ML
Minimum Function Test Statistic 85.306
Degrees of freedom 24
P-value (Chi-square) 0.000
#参数fit.measure = TRUE会显示下面从model test baseline model到SRMR的部分
Model test baseline model:
Minimum Function Test Statistic 918.852
Degrees of freedom 36
P-value 0.000
User model versus baseline model:
Comparative Fit Index (CFI) 0.931
Tucker-Lewis Index (TLI) 0.896
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -3737.745
Loglikelihood unrestricted model (H1) -3695.092
Number of free parameters 21
Akaike (AIC) 7517.490
Bayesian (BIC) 7595.339
Sample-size adjusted Bayesian (BIC) 7528.739
Root Mean Square Error of Approximation:
RMSEA 0.092
90 Percent Confidence Interval 0.071 0.114
P-value RMSEA <= 0.05 0.001
Standa