随着乐视硬件抢购的不断升级,乐视集团支付面临的请求压力百倍乃至千倍的暴增。作为商品购买的最后一环,保证用户快速稳定地完成支付尤为重要。所以在2015年11月,我们对整个支付系统进行了全面的架构升级,使之具备了每秒稳定处理10万订单的能力。为乐视生态各种形式的抢购秒杀活动提供了强有力的支撑。
一. 分库分表
在Redis,memcached等缓存系统盛行的互联网时代,构建一个支撑每秒十万只读的系统并不复杂,无非是通过一致性哈希扩展缓存节点,水平扩展web服务器等。支付系统要处理每秒十万笔订单,需要的是每秒数十万的数据库更新操作(insert加update),这在任何一个独立数据库上都是不可能完成的任务,所以我们首先要做的是对订单表(简称order)进行分库与分表。
在进行数据库操作时,一般都会有用户ID(简称uid)字段,所以我们选择以uid进行分库分表。
分库策略我们选择了“二叉树分库”,所谓“二叉树分库”指的是:我们在进行数据库扩容时,都是以2的倍数进行扩容。比如:1台扩容到2台,2台扩容到4台,4台扩容到8台,以此类推。这种分库方式的好处是,我们在进行扩容时,只需DBA进行表级的数据同步,而不需要自己写脚本进行行级数据同步。
光是有分库是不够的,经过持续压力测试我们发现,在同一数据库中,对多个表进行并发更新的效率要远远大于对一个表进行并发更新,所以我们在每个分库中都将order表拆分成10份:order_0,order_1,....,order_9。
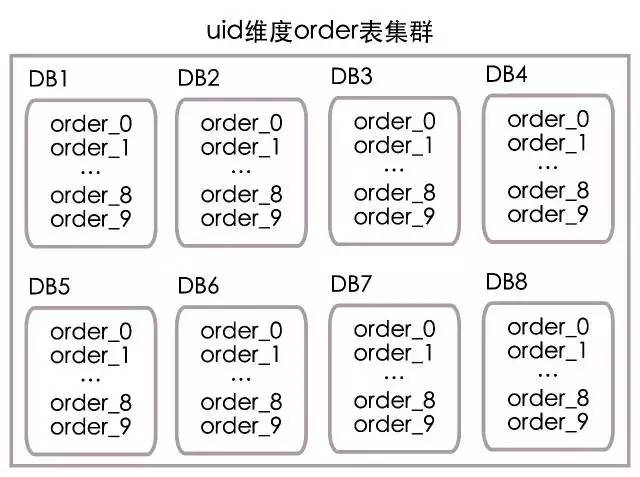
最后我们把order表放在了8个分库中(编号1到8,分别对应DB1到DB8),每个分库中10个分表(编号0到9,分别对应order_0到order_9),部署结构如下图所示:
根据uid计算数据库编号:
数据库编号 = (uid / 10) % 8 + 1
根据uid计算表编号:
表编号 = uid % 10
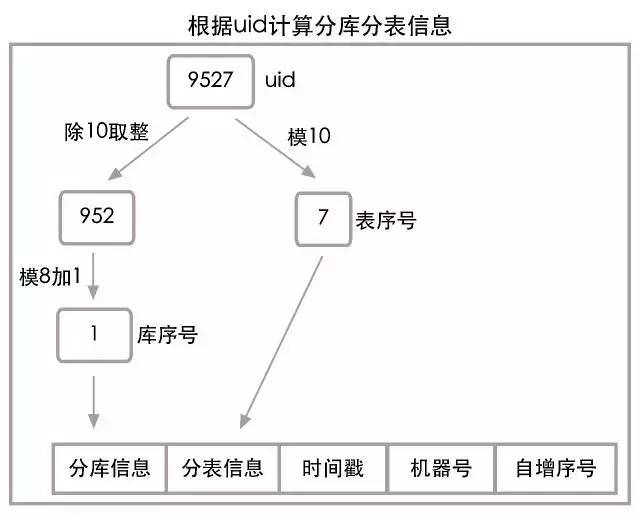
当uid=9527时,根据上面的算法,其实是把uid分成了两部分952和7,其中952模8加1等于1为数据库编号,而7则为表编号。所以uid=9527的订单信息需要去DB1库中的order_7表查找。具体算法流程也可参见下图:

有了分库分表的结构与算法最后就是寻找分库分表的实现工具,目前市面上约有两种类型的分库分表工具:
1.客户端分库分表,在客户端完成分库分表操作,直连数据库
2.使用分库分表中间件,客户端连分库分表中间件,由中间件完成分
库分表操作
这两种类型的工具市面上都有,这里不一一列举,总的来看这两类工具各有利弊。客户端分库分表由于直连数据库,所以性能比使用分库分表中间件高15%到20%。而使用分库分表中间件由于进行了统一的中间件管理,将分库分表操作和客户端隔离,模块划分更加清晰,便于DBA进行统一管理。
我们选择的是在客户端分库分表,因为我们自己开发并开源了一套数据层访问框架,它的代号叫“芒果”,芒果框架原生支持分库分表功能,并且配置起来非常简单。
芒果主页:mango.jfaster.org
芒果源码:github.com/jfaster/mango
二. 订单ID
订单系统的ID必须具有全局唯一的特征,最简单的方式是利用数据库的序列,每操作一次就能获得一个全局唯一的自增ID,如果要支持每秒处理10万订单,那每秒将至少需要生成10万个订单ID,通过数据库生成自增ID显然无法完成上述要求。所以我们只能通过内存计算获得全局唯一的订单ID。
Java领域最著名的唯一ID应该算是UUID了,不过UUID太长而且包含字母,不适合作为订单ID。通过反复比较与筛选,我们借鉴了Twitter的Snowflake算法,实现了全局唯一ID。下面是订单ID的简化结构图:

上图分为3个部分:
1
时间戳
这里时间戳的粒度是毫秒级,生成订单ID时,使用System.currentTimeMillis()作为时间戳
2
机器号
每个订单服务器都将被分配一个唯一的编号,生成订单ID时,直接使用该唯一编号作为机器号即可。
3
自增序号
当在同一服务器的同一毫秒中有多个生成订单ID的请求时,会在当前毫秒下自增此序号,下一个毫秒此序号继续从0开始。比如在同一服务器同一毫秒有3个生成订单ID的请求,这3个订单ID的自增序号部分将分别是0,1,2。
上面3个部分组合,我们就能快速生成全局唯一的订单ID。不过光全局唯一还不够,很多时候我们会只根据订单ID直接查询订单信息,这时由于没有uid,我们不知道去哪个分库的分表中查询,遍历所有的库的所有表?这显然不行。所以我们需要将分库分表的信息添加到订单ID上,下面是带分库分表信息的订单ID简化结构图:

我们在生成的全局订单ID头部添加了分库与分表的信息,这样只根据订单ID,我们也能快速的查询到对应的订单信息。
分库分表信息具体包含哪些内容?第一部分有讨论到,我们将订单表按uid维度拆分成了8个数据库,每个数据库10张表,最简单的分库分表信息只需一个长度为2的字符串即可存储,第1位存数据库编号,取值范围1到8,第2位存表编号,取值范围0到9。
还是按照第一部分根据uid计算数据库编号和表编号的算法,当uid=9527时,分库信息=1,分表信息=7,将他们进行组合,两位的分库分表信息即为"17"。具体算法流程参见下图:
上述使用表编号作为分表信息没有任何问题,但使用数据库编号作为分库信息却存在隐患,考虑未来的扩容需求,我们需要将8库扩容到16库,这时取值范围1到8的分库信息将无法支撑1到16的分库场景,分库路由将无法正确完成,我们将上诉问题简称为分库信息精度丢失。
为解决分库信息精度丢失问题,我们需要对分库信息精度进行冗余,即我们现在保存的分库信息要支持以后的扩容。这里我们假设最终我们会扩容到64台数据库,所以新的分库信息算法为:
分库信息 = (uid / 10) % 64 + 1
当uid=9527时,根据新的算法,分库信息=57,这里的57并不是真正数据库的编号,它冗余了最后扩展到64台数据库的分库信息精度。我们当前只有8台数据库,实际数据库编号还需根据下面的公式进行计算:
实际数据库编号 = (分库信息 - 1) % 8 + 1
当uid=9527时,分库信息=57,实际数据库编号=1,分库分表信息="577"。
由于我们选择模64来保存精度冗余后的分库信息,保存分库信息的长度由1变为了2,最后的分库分表信息的长度为3。具体算法流程也可参见下图:
如上图所示,在计算分库信息的时候采用了模64的方式冗余了分库信息精度,这样当我们的系统以后需要扩容到16库,32库,64库都不会再有问题。
上面的订单ID结构已经能很好的满足我们当前与之后的扩容需求,但考虑到业务的不确定性,我们在订单ID的最前方加了1位用于标识