1. 没有阅读软件设计丛书的习惯,更多人偏向于阅读偏应用层面的书籍,“talk is cheap,show me the code”往往更符合大多数人的习惯。
2. 没有太多的开发经验支撑。没有踩过坑,就不会意识到设计的重要性,无法产生共情。
3. 年代有些久远,这本书写于2004年,书中很多软件设计的反例,在当时是非常流行的,但是在现在已经基本绝迹了。大师之所以为大师,是因为其能跨越时代的限制,预见未来的问题,这也是为什么DDD在十几年前就被提出,却在微服务逐渐流行的现阶段才被大家重视。
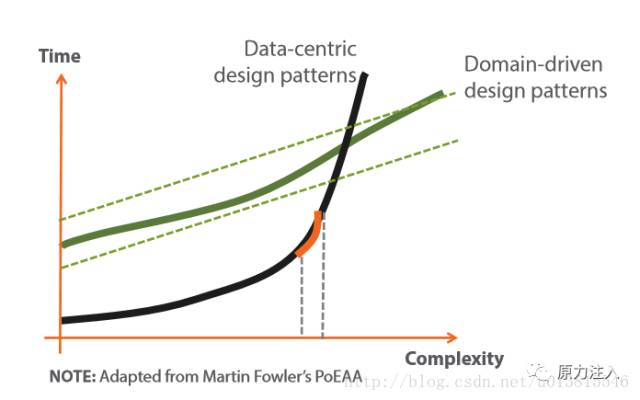
图1:复杂性与开发周期关系
遵循领域驱动设计的规范使得项目初期的开发甚至不如不使用它来的快,原因有很多,程序员的素质,代码的规范,限界上下文的划分…甚至需求修改后导致需要重新建模。但是遵循领域驱动设计的规范,在项目越来越复杂之后,可以不至于让项目僵死。这也是为什么很多系统不断迭代着,最终就黄了。书名的副标题“软件核心复杂性应对之道”正是阐释了这一点。
模式: smart ui是个反模式
可能很多读者还不知道smart ui是什么,但是在这本书写作期间,这种设计风格是非常流行的。在与一位领域驱动设计方面的资深专家的交谈中,他如下感慨到软件发展的历史:
2003年时,正是delphi,vb一类的smart ui程序大行其道,Java在那个年代,还在使用jsp来完成大量的业务逻辑操作,4000行的jsp是常见的事;2005年spring hibernate替换了EJB,社区一片欢呼,所有人开始拥护action,service,dao这样的贫血模型(充血模型,贫血模型会在下文论述);2007年,Rails兴起,有人发现了Rails的activeRecord是涨血模型,引起了一片混战;直到现在的2017年,微服务成为主流系统架构。
在现在这个年代,不懂个MVC分层,都不好意思说自己是搞java的,也不会有人在jsp里面写业务代码了
(可以说模板技术freemarker,thymeleaf已经取代jsp了),
但是在那个年代,还没有现在这么普遍地强调分层架构的重要性。
这个章节其实并不重要,因为mvc一类的分层架构已经是大多数java初学者的“起点”了,大多数DDD的文章都不会赘述这一点,我这里列出来是为了让大家知晓这篇文章的时代局限性,在后续章节的理解中,也需要抱有这样的逻辑:这本书写于2004年。
模式: Entity与Value Object
我在不了解DDD时,就对这两个术语早有耳闻。entity又被称为reference object,我们通常所说的Java bean在领域中通常可以分为这两类,(可别把value object和常用于前台展示的view object,vo混为一谈)
entity的要义在于生命周期和标识,value object的要义在于无标识,通常情况下,entity在通俗意义上可以理解为数据库的实体,(不过不严谨),value object则一般作为一个单独的类,构成entity的一个属性。
举两个例子来加深对entity和value object的理解。
例1:以电商微服务系统中的商品模块,订单模块为例。将整个电商系统划分出商品和订单两个限界上下文(Bound Context)应该是没有争议的。如果是传统的单体应用,我们可以如何设计这两个模块的实体类呢?
会不会是这样?

class Product{
String id;//主键
String skuId;//唯一识别号
String productName;
Bigdecimal price;
Category category;//分类
List<Specification> specifications;//规格
...
}
class Order{
String id;//主键
String orderNo;//订单号
List<OrderItem> orderItems;//订单明细
BigDecimal orderAmount;//总金额
...
}
class OrderItem{
String id;
Product product;//关联商品
BigDecimal snapshotPrice;//下单时的价格
}
看似好像没问题,考虑到了订单要保存下单时候的价格(当然,这是常识)但这么设计却存在诸多的问题。
在分布式系统中,商品和订单这两个模块必然不在同一个模块,也就意味着不在同一个网段中。
上述的类设计中直接将Product的列表存储到了Order中,也就是一对多的外键关联。这会导致,每次访问订单的商品列表,都需要发起n次远程调用。
反思我们的设计,其实我们发现,订单BC的Product和商品BC的Product其实并不是同一个entity,在商品模块中,我们更关注商品的规格,种类,实时价格,这最直接地反映了我们想要买什么的欲望。而当生成订单后,我们只关心这个商品买的时候价格是多少,不会关心这个商品之后的价格变动,还有他的名称,仅仅是方便我们在订单的商品列表中定位这个商品。
如何改造就变得明了了
class OrderItem{
String id;
String productId;//只记录一个id用于必要的时候发起command操作
String skuId;
String productName;
...
BigDecimal snapshotPrice;//下单时的价格
}
是的,我们做了一定的冗余,这使得即使商品模块的商品,名称发生了微调,也不会被订单模块知晓。这么做也有它的业务含义,用户会声称:我买的时候他的确就叫这个名字。记录productId和skuId的用意不是为