提要:本系列文章主要参考MIT 6.828课程以及两本书籍《深入理解Linux内核》 《深入Linux内核架构》对Linux内核内容进行总结。
内存管理的实现覆盖了多个领域:
- 内存中的物理内存页的管理
- 分配大块内存的伙伴系统
- 分配较小内存的slab、slub、slob分配器
- 分配非连续内存块的vmalloc分配器
- 进程的地址空间
内核初始化后,内存管理的工作就交由伙伴系统来承担,作为众多内存分配器的基础,我们必须要对其进行一个详细的解释。但是由于伙伴系统的复杂性,因此,本节会首先给出一个简单的例子,然后由浅入深,逐步解析伙伴系统的细节。
伙伴系统简介
伙伴系统将所有的空闲页框分为了11个块链表,每个块链表分别包含大小为1,2,4,\(2^3\),\(2^4\),...,\(2^{10}\)个连续的页框(每个页框大小为4K),\(2^{n}\)中的n被称为order(分配阶),因此在代码中这11个块链表的表示就是一个长度为11的数组。考察表示Zone结构的代码,可以看到一个名为free_area的属性,该属性用于保存这11个块链表。
struct zone {
...
/*
* 不同长度的空闲区域
*/
struct free_area free_area[MAX_ORDER];
...
};
结合之前的知识,我们总结一下,Linux内存管理的结构形如下图:
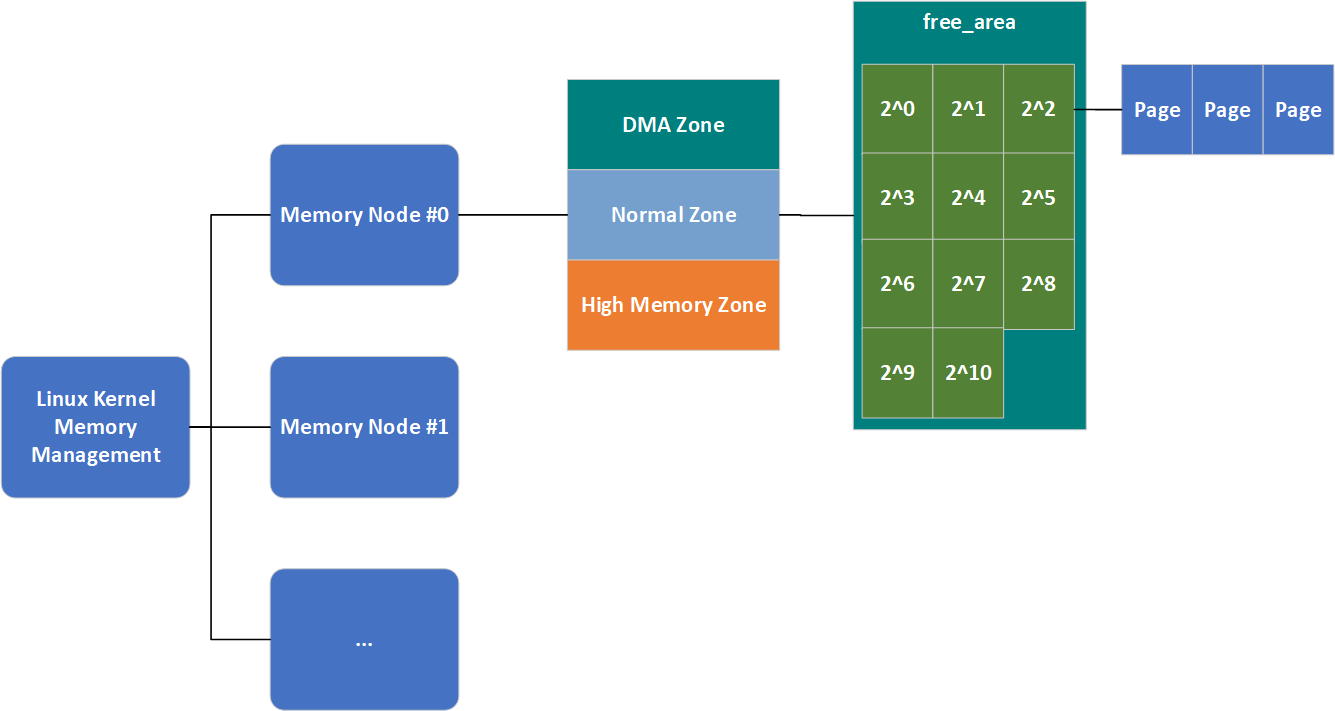
当然,这还不是完整的,我们本节就会将其填充完整。最后借用《深入理解Linux内核》中的一个例子简单介绍一下该算法的工作原理进而结束简介这一小节。
假设要请求一个256个页框(2^8)的块(即1MB)。
- 算法先在256个页的链表中检查是否有一个空闲块。
- 如果没有这样的块,算法会查找下一个更大的页块,也就是,在512个页框的链表中找一个空闲块。
- 如果存在这样的块,内核就把256的页框分成两等份,一半用作满足请求,另一半插人到256个页框的链表中。
- 如果在512个页框的块链表中也没找到空闲块,就继续找更大的块 一一1024个页框的块。
- 如果这样的块存在,内核把1024个页框块的256个页框用作请求,然后从剩余的768个页框中拿512个插入到512个页框的链表中
- 再把最后的256个插人到256个页框的链表中。
- 如果1024个页框的链表还是空的,算法就放弃并发出错信号
以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为b的一对空闲伙伴块合并为一个大小为2b的单独块。满足以下条件的两个块称为伙伴:
- 两个块具有相同的大小,记作 b。
- 它们的物理地址是连续的。
- 第一块的第一个页框的物理地址是2 x b x \(2^{12}\)的倍数。
注意:该算法是迭代的,如果它成功合并所释放的块,它会试图合并2b的块,以再次试图形成更大的块。然而伙伴系统的实现并没有这么简单。
避免碎片
伙伴系统作为内存管理系统,也难以逃脱一个经典的难题,物理内存的碎片问题。尤其是在系统长期运行后,其内存可能会变成如下的样子:
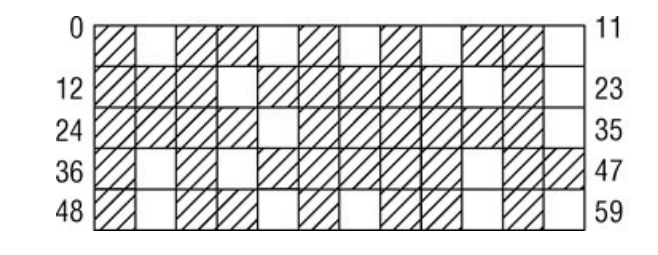
为了解决这个问题,Linux提供了两种避免碎片的方式:
- 可移动页
- 虚拟可移动内存区
可移动页
物理内存被零散的占据,无法寻找到一块连续的大块内存。内核2.6.24版本,防止碎片的方法最终加入内核。内核采用的方法是反碎片,即试图从最初开始尽可能防止碎片。因为许多物理内存页不能移动到任意位置,因此无法整理碎片。
可以看到,内核中内存碎片难以处理的主要原因是许多页无法移动到任意位置,那么如果我们将其单独管理,在分配大块内存时,尝试从可以任意移动的内存区域内分配,是不是更好呢?
为了达成这一点,Linux首先要了解哪些页是可移动的,因此,操作系统将内核已分配的页划分为如下3种类型:
| 类别名称 | 描述 |
|---|---|
| 不可移动页 | 在内存中有固定位置,不能移动到其他地方。核心内核分配的大多数内存属于该类别 |
| 可回收页 | 不能直接移动,但可以删除,其内容可以从某些源重新生成 |
| 可移动页 | 可以随意移动。属于用户空间应用程序的页属于该类别。它们是通过页表映射的。如果它们复制到新位置,页表项可以相应地更新,应用程序不会注意到任何事 |
内核中定义了一系列宏来表示不同的迁移类型:
#define MIGRATE_UNMOVABLE 0 // 不可移动页
#define MIGRATE_RECLAIMABLE 1 // 可回收页
#define MIGRATE_MOVABLE 2 // 可移动页
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* 不能从这里分配 */
#define MIGRATE_TYPES 5
对于其他两种类型(了解就好):
- MIGRATE_RESERVE:如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_RESERVE分配内存
- MIGRATE_ISOLATE:是一个特殊的虚拟区域,用于跨越NUMA结点移动物理内存页。在大型系统上,它有益于将物理内存页移动到接近于使用该页最频繁的CPU。
伙伴系统实现页的可移动性特性,依赖于数据结构free_area,其代码如下:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
| 属性名 | 描述 |
|---|---|
| free_list | 每种迁移类型对应一个空闲页链表 |
| nr_free | 所有列表上空闲页的数目 |
与zone.free_area一样,free_area.free_list也是一个链表,但这个链表终于直接连接struct page了。因此,我们的内存管理结构图就变成了如下的样子:

与NUMA内存域无法满足分配请求时会有一个备用列表一样,当一个迁移类型列表无法满足分配请求时,同样也会有一个备用列表,不过这个列表不用代码生成,而是写死的:
/*
* 该数组描述了指定迁移类型的空闲列表耗尽时,其他空闲列表在备用列表中的次序。
*/
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE },/* 从来不用 */
};
该数据结构大体上是自明的:在内核想要分配不可移动页时,如果对应链表为空,则后退到可回收页链表,接下来到可移动页链表,最后到紧急分配链表。
在各个迁移链表之间,当前的页面分配状态可以从/proc/pagetypeinfo获得:
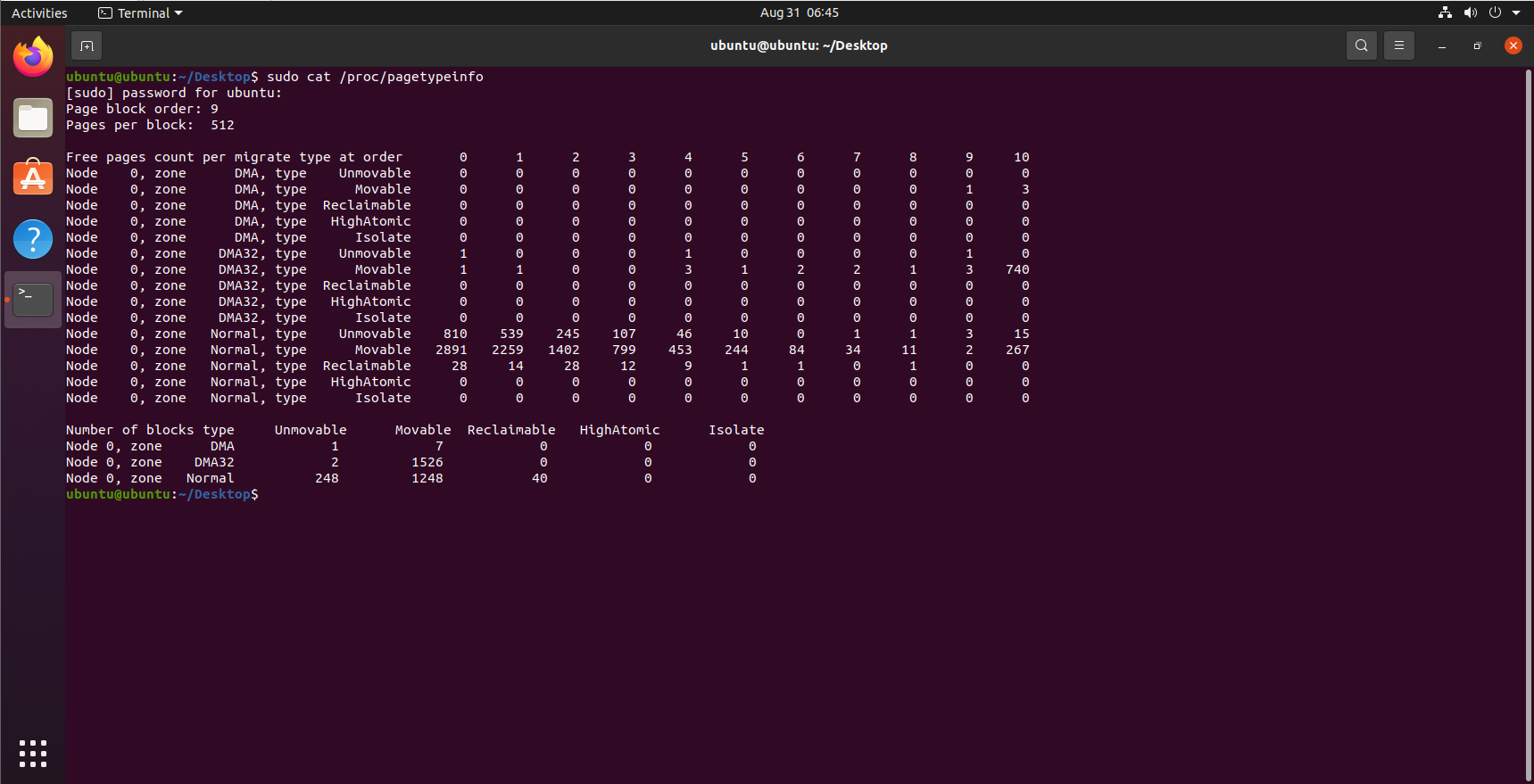
虚拟可移动内存域
可移动页给与内存分配一种层级分配的能力(按照备用列表顺序