dy = "response" in xhr ? xhr.response : xhr.responseText;
resolve(new Response(body, options));
};
Response构造函数:
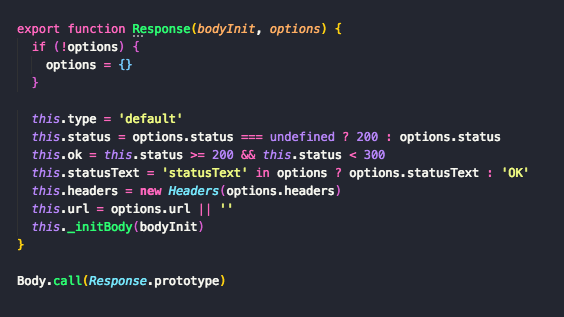
可见在构造函数中主要对options中的status、statusText、headers、url等分别做了处理并挂载到Response对象上。
构造函数里面并没有对responseText的明确处理,最后交给了_initBody函数处理,而Response并没有主动声明_initBody属性,代码最后使用Response调用了Body函数,实际上_initBody函数是通过Body函数挂载到Response身上的,先来看看_initBody函数:
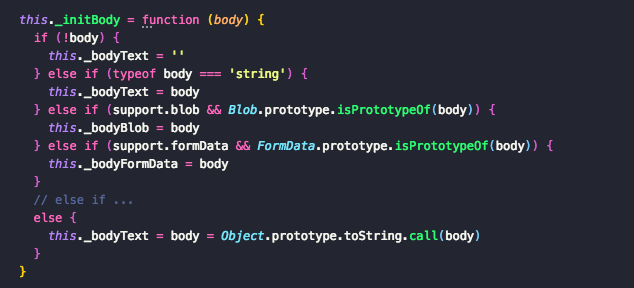
可见,_initBody函数根据xhr.response的类型(Blob、FormData、String...),为不同的参数进行赋值,这些参数在Body方法中得到不同的应用,下面具体看看Body函数还做了哪些其他的操作:

Body函数中还为Response对象挂载了四个函数,text、json、blob、formData,这些函数中的操作就是将_initBody 中得到的不同类型的返回值返回。
这也说明了,在fetch执行完毕后,不能直接在response中获取到返回值而必须调用text()、json()等函数才能获取到返回值。
这里还有一点需要说明:几个函数中都有类似下面的逻辑:
var rejected = consumed(this);
if (rejected) {
return rejected;
}
consumed 函数:
function consumed(body) {
if (body.bodyUsed) {
return Promise.reject(new TypeError("Already read"));
}
body.bodyUsed = true;
}
每次调用text()、json()等函数后会将bodyUsed变量变为true,用来标识返回值已经读取过了,下一次再读取直接抛出TypeError('Already read')。这也遵循了原生fetch的原则:
因为 Responses 对象被设置为了 stream 的方式,所以它们只能被读取一次
十、fetch 的坑点
VUE的文档中对fetch有下面的描述:
使用fetch还有很多别的注意事项,这也是为什么大家现阶段还是更喜欢axios 多一些。当然这个事情在未来可能会发生改变。
由于fetch是一个非常底层的API,它并没有被进行很多封装,还有许多问题需要处理:
- 不能直接传递
java script对象作为参数
- 需要自己判断返回值类型,并执行响应获取返回值的方法
- 获取返回值方法只能调用一次,不能多次调用
- 无法正常的捕获异常
- 老版浏览器不会默认携带
cookie
- 不支持
jsonp
十一、对 fetch 的封装
请求参数处理
支持传入不同的参数类型:
function stringify(url, data) {
var dataString = url.indexOf("?") == -1 ? "?" : "&";
for (var key in data) {
dataString += key + "=" + data[key] + "&";
}
return dataString;
}
if (request.formData) {
request.body = request.data;
} else if (/^get$/i.test(request.method)) {
request.url = `${request.url}${stringify(request.url, request.data)}`;
} else if (request.form) {
request.headers.set(
"Content-Type",
"application/x-www-form-urlencoded;charset=UTF-8"
);
request.body = stringify(request.data);
} else {
request.headers.set("Content-Type", "application/json;charset=UTF-8");
request.body = JSON.stringify(request.data);
}
cookie 携带
fetch在新版浏览器已经开始默认携带同源cookie,但在老版浏览器中不会默认携带,我们需要对他进行统一设置:
request.credentials = "same-origin"; // 同源携带
request.credentials = "include"; // 可跨域携带
异常处理
当接收到一个代表错误的 HTTP 状态码时,从 fetch()返回的 Promise 不会被标记为 reject, 即使该 HTTP 响应的状态码是 404 或 500。相反,它会将 Promise 状态标记为 resolve (但是会将 resolve 的返回值的 ok 属性设置为 false ),仅当网络故障时或请求被阻止时,才会标记为 reject。
因此我们要对fetch的异常进行统一处理
.then(response => {
if (response.ok) {
return Promise.resolve(response);
}else{
const error = new Error(`请求失败! 状态码: ${response.status}, 失败信息: ${response.statusText}`);
error.response = response;
return Promise.reject(error);
}
});
返回值处理
对不同的返回值类型调用不同的函数接收,这里必须提前判断好类型,不能多次调用获取返回值的方法:
.then(response => {
let contentType = response.headers.get('content-type');
if (contentType.includes('application/json')) {
return response.json();
} else {
return response.text();
}
});
jsonp
fetch本身没有提供对jsonp的支持,jsonp本身也不属于一种非常好的解决跨域的方式,推荐使用cors或者nginx解决跨域,具体请看下面的章节。
fetch 封装好了,可以愉快的使用了。
嗯,axios 真好用…
十二、跨域总结
谈到网络请求,就不得不提跨域。
浏览器的同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。通常不允许不同源间的读操作。
跨域条件:协议,域名,端口,有一个不同就算跨域。
下面是解决跨域