版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yy15642766973/article/details/79825091
Hadoop笔记 linux中搭建hadoop开发环境
hadoop是什么?
hadoop是一个平台,是一个适合大数据的分布式存储和计算的平台。
hadoop核心:1.HDFS;2.MapReduce。
hadoop安装方式|hadoop部署方式
hadoop安装方式只有三种:单机安装;伪分布安装;集群安装。
单机方式:在一台上安装运行Hadoop系统,
伪分布式:在单机上用伪分布方式用不同的Java进程模拟分布运行中的namenode、datanode、jobtracker、tasktracker等各类节点。
集群分布:在一个真实的集群环境下运行Hadoop系统,单机模式和和伪分布模式均是用于调试和开发的目的,真正的Hadoop 应用是采用的集群模式。因此我们需要几台服务器主机。
0.下载jdk
登录网址:http://www.oracle.com/technetwork/java/javase/downloads/
选择对应jdk版本下载。(可在Windows下下载完成后,通过文件夹共享到Linux上)
1.登录Linux,切换到root用户
2.在usr目录下建立java安装目录
命令mkdir usr/java
3.将jdk-10-linux-x64.tar.gz拷贝到java目录下并解压
命令:cp /mnt/hgfs/Ubuntu\ share/jdk-10-linux-x64.tar.gz /usr/java
tar -zxvf jdk-10-linux-x64.tar.gz
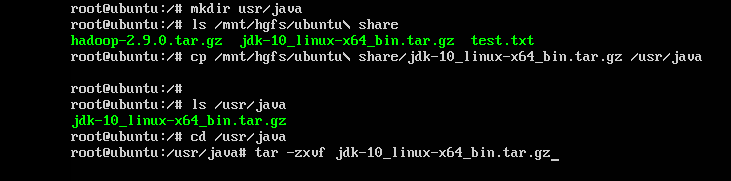
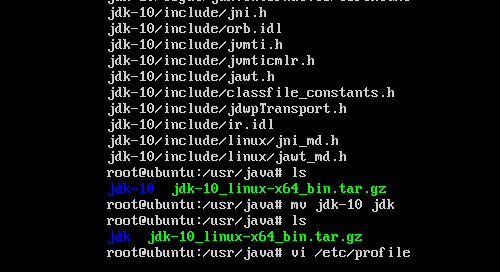
解压后会生成一个目录:jdk-10,为了便于后期配置java环境变量,我们把这个目录重命名为jdk。
命令:mv /usr/java/jdk-10 /usr/java/jdk;
4.接着配置jdk环境变量,编辑/etc/profile文件。
命令:vi /etc/profile
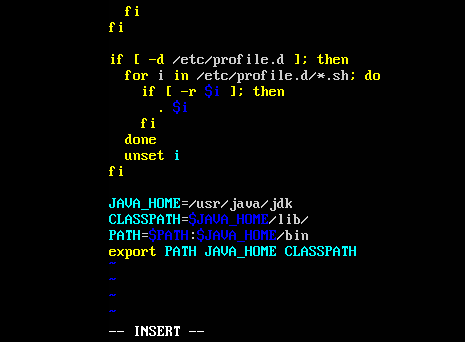
添加如下内容:
JAVA_HOME=/usr/java/jdk
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
重启机器或执行
命令:source/etc/profile
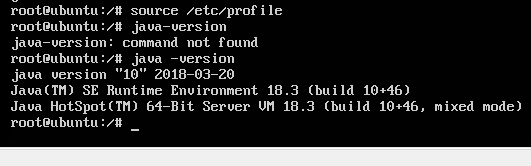
查看安装情况:java-version
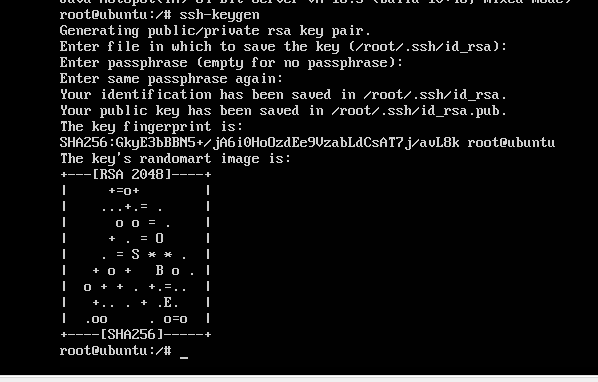
5.配置ssh无密码认证。
执行如下命令:ssh-keygen。此处可以一直敲回车。执行完之后
ls /root/.ssh/
可以在目录下看见两个密钥这是SSH的一对私钥和公钥,
类似于钥匙及锁,把id_dsa.pub(公钥)追加到授权的key里面去。
输入命令:
cp /root/.ssh/id_dsa.pub /root/.ssh/authorized_keys
这条命令是把公钥加到用于认证的公钥文件中,这里的authorized_keys是用于认证的公钥文件
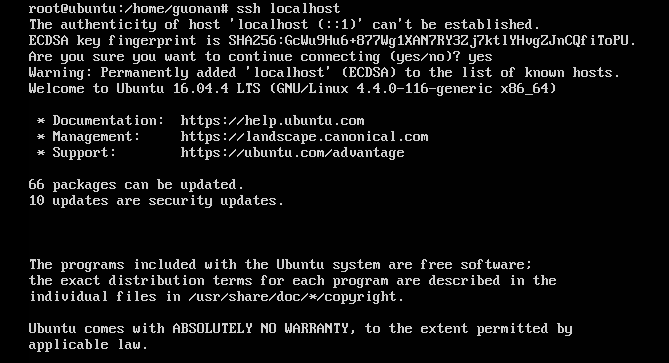
验证SSH是否可以无密码登录本机 ssh localhost
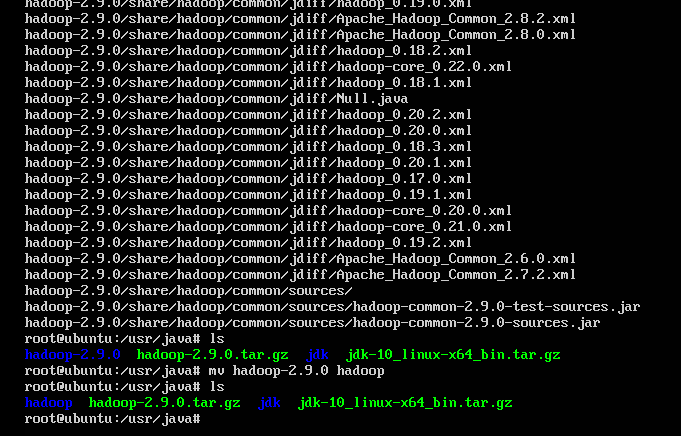
6.解压安装Hadoop
官网下载Hadoop http://mirrors.hust.edu.cn/apache/hadoop/common/
拷贝到/usr/java目录下,并解压缩。
命令:tar zxvf hadoop-2.9.0.tar.gz;
解压后会生成一个名为 hadoop-2.9.0的目录,我们接着把这个目录重命名为hadoop。
命令:mv /usr/java/hadoop-2.9.0 /usr/Java/hadoop;
7.接着配置环境变量。(伪分布模式的配置)
conf/hadoop-env.sh; Hadoop环境变量
conf/core-site.xml 主要完成namenode的ip和端口设置
conf/hdfs-site.xml 主要完成hdfs的数据块副本等参数设置
conf/mapred-site.xml主要完成jobtrackerip和端口设置
conf/masters 完成master结点ip设置
conf/slaves 完成slaves结点ip设置
命令ls /usr/java/hadoop/etc/hadoop/四个配置文件在这里
a.指定JDK的安装位置:
在Hadoop-env.sh中:
export JAVA_HOME=””

b.配置HDFS的地址和端口号:
在core-site.xml中:
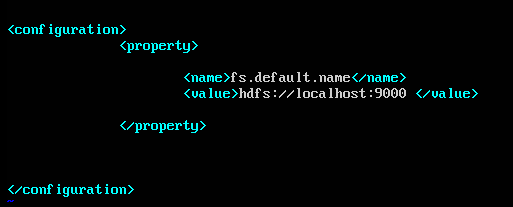
在mapred-site.xml中:
.
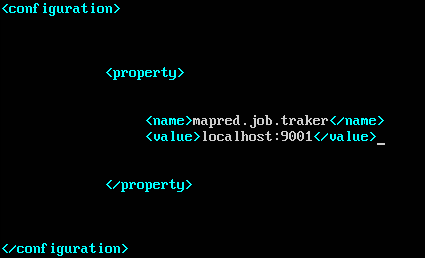
在hdfs-site.xml中:
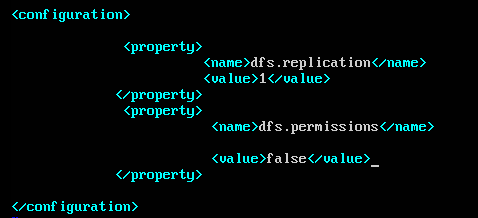
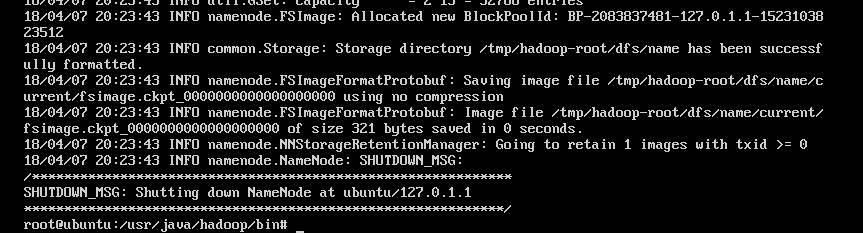
格式化Hadoop并启动验证:
格式化Hadoop:
./bin/hadoop namenode -format
启动Hadoop:
./bin/start-all.sh(全部启动)
验证Hadoop是否安装成功,打开浏览器,分别输入网址:
http://localhost:50030(MapReduce的web页面)
http://localhost:50070(HDFS的web页面)
若都能查看,说明Hadoop已经安装成功。
但是但是我没有安装成功 ,笔者也是一名新手,安装路上遇到过很多问题,下面来解决问题。
,笔者也是一名新手,安装路上遇到过很多问题,下面来解决问题。
以上安装方法也是笔者在网上查到并执行,但是笔者忘了很多的方法也都过时了,拿Hadoop来说,上面的方法是1.0版的,但是我下载的Hadoop是最新版的2.x,1和2的文件配置有很大的不同。
下面来讲2.x版本的文件配置
a. 在hadoop文件下建立tmp文件
命令 mkdir tmp
b. hdfs-site.xml
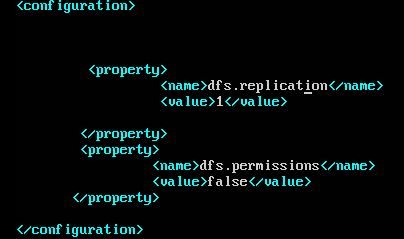
c. core-site.xml
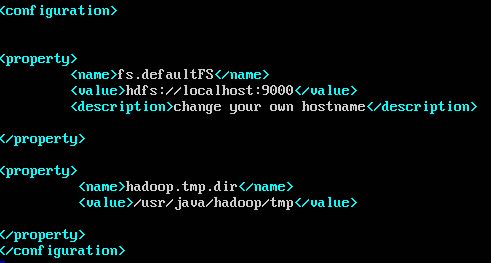
d. mapred-site.xml.template

e. 多了一个文件配置yarn-site.xml,版本1是没有的。

f. 格式化和启动也有所不同
格式化 ./hdfs namenode -format

说明格式化成功了
g. 启动 Hadoop版本1在bin目录下,版本2在sbin下面 sbin# ./start-hfs.sh start-yarn.sh
hadoop2以后没有tasktracker 与jobtracker 了,
详细参考:yarn详解:http://www.aboutyun.com/thread-7678-1-1.html
这个让你明白为什么没有tasktracker 与jobtracker
h. 下面打开浏览器,验证是否安装成功
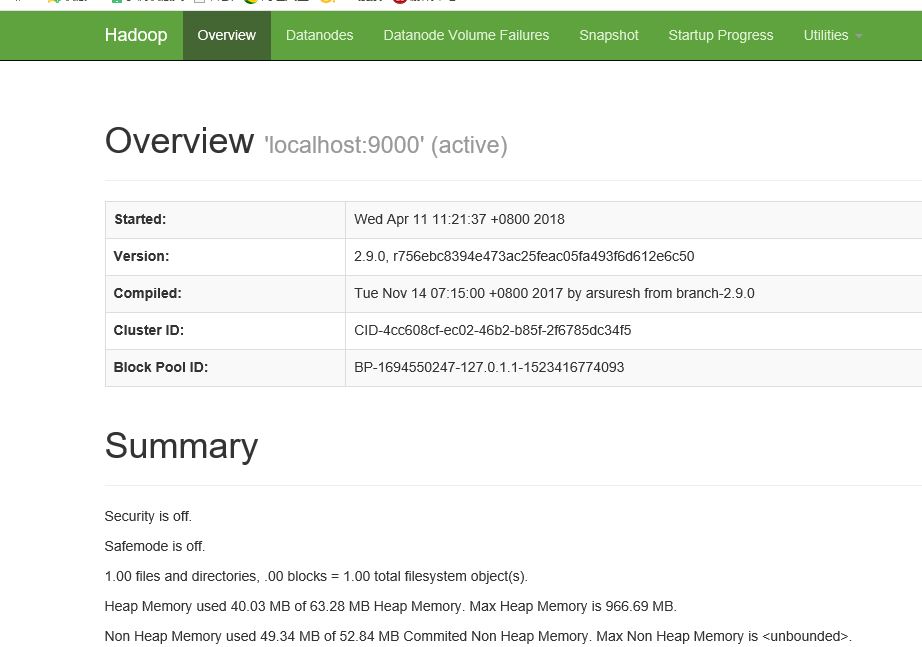
50070 成功
错误:
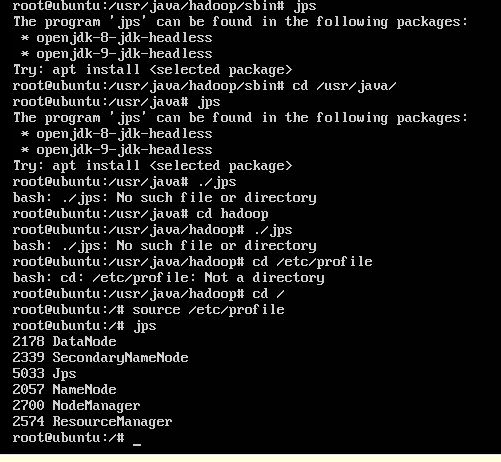
jps用不了了。不知道为什么。尝试各种方法,后来发现要先source etc/profile ,问题解决如图