一、Hadoop是什么
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing.
Hadoop是做可靠的、可扩展的、分布式计算,说白了就是处理海量数据问题的解决方案。
二、Hadoop要解决的问题
hadoop最擅长的是(离线的、海量的)日志处理,几十个T的数据,传统的sql数据库时解决不了的。就算可以解决也是非常非常难的。facebook就用Hive来进行日志分析,淘宝搜索中的筛选也使用的Hive。如今,Hadoop已经是被公认是一套在分布式环境下提供了海量数据的处理能力的解决方案。支付宝使用Hbase对用户的消费记录可以实现毫秒级查询。实时的信息推送等等。

从淘宝的架构上可以清晰的看到,其中间计算层使用的就是Hadoop来处理。
三、海量数据的解决方案
Hadoop的核心是MapReduce和HDFS。
1.通过HDFS解决海量数据的存储
假设有100T数据,存储在4台PC机上(A、B、C、D),A机存储电影,B机存储图片,C机存储邮件,D机存储mp3。如图所示。
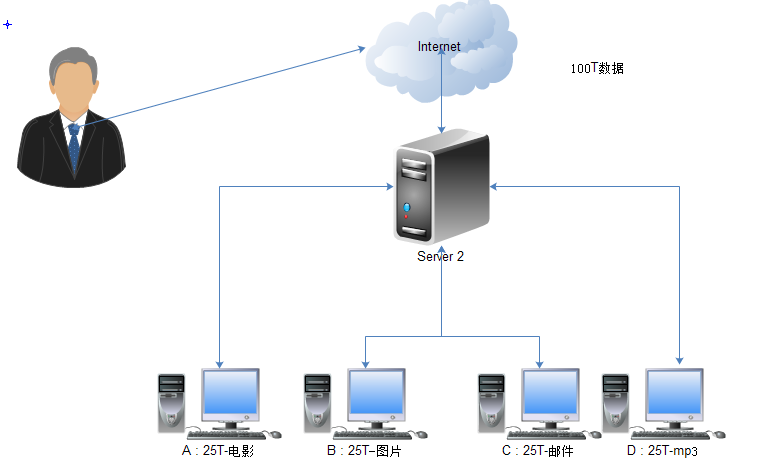
用户很容易通过网络,访问Server2机来访问到这100T数据,但是如果多个用户同时要看电影,那么Server2只能找A机,这样就导致两个问题就是
1).A机的负载压力过大,其他机器闲置
2).一旦A机宕机,那么就无法访问到电影。即使A机有备机,那么在往A机进行写入操作时,A的备机该如何呢?集群条件下呢?
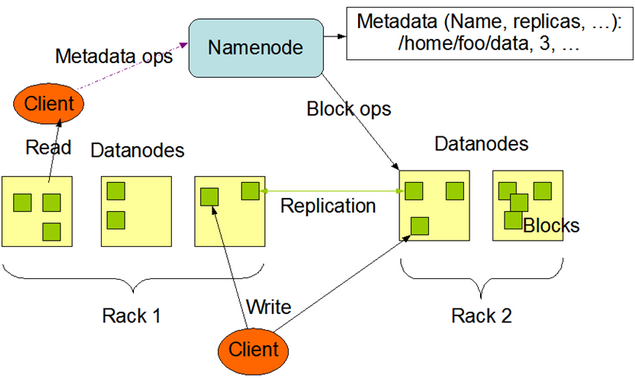
Hadoop的HDFS是如何解决的?
集群会把大文件切成多个文件块,存在不同的PC上,这样负载问题就解决了,每一个block块文件在集群中存在多个副本,副本在不同的机器上,比如block1在4台机器上,那么用户再访问block1的内容时,就可以4台机器同时并发访问,性能告。HDFS通过nameNode负责来记录和映射具体的block在哪台PC上,所以客户端在访问的时候,首先访问的就是namenode,从namenode获取信息,再去找datanode,进行数据的读写操作。
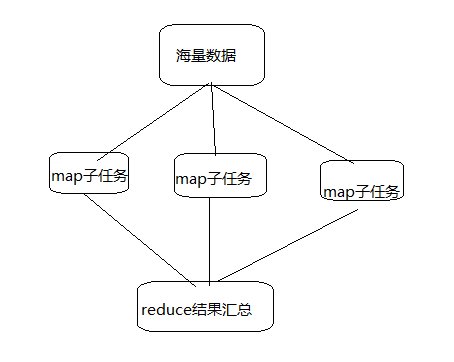
2.通过MapReduce解决海量数据的计算
HDFS将大文件打散存放在不同的机器上,比如一份10T的文本文件,文本文件被打散在不同机器上,那么如何计算select count(行) 操作,取出来计算是不可能的,内存、硬盘、带宽都不允许,Hadoop的MapReduce就是把统计逻辑分发到数据块所在的datanode上,那么每个机器就可以把自己机器上的数据计算出来(Map阶段,本地局部进行处理),不需要走网络,节省了带宽,每个机器都有自己的统计结果。最终的结果是一台机器进行统计不同PC的统计结果(reduce阶段),进行汇总运算,就不存在内存、硬盘、带宽等瓶颈问题(reduce还可以根据业务逻辑,进行分组,多个并发执行)。
</div>