CentOS��Hadoopα�ֲ�ģʽ��װ�ʼ�
һ. ǰ��
Hadoop α�ֲ�ʽģʽ���ڵ�����ģ�� Hadoop�ֲ�ʽ�������ϵķֲ�ʽ������������α�ֲ�ʽ������ʹ���߳�ģ��ֲ�ʽ��Hadoop������������α�ֲ�ʽ�ͷֲ�ʽ�ģ���������Ҳ�����ƣ�Ψһ��ͬ�ĵط���α�ֲ�ʽ���ڵ����������ã����ݽڵ�����ֽڵ����һ�����������ںܶ��ѧ�߸������߱����ȫ�ֲ�ʽ��Ⱥ��Ӳ�������������ڵ����½���ѧϰ��ʵ�顣���潫���ڰ�װ�ڼ�����������ͽ��������¼�����������ѹ��㡣���˵�ʱ����Linux
Cent OS 6.3�´�ɹ�Hadoopα�ֲ�ʽ���Ի�����
*******************************************************************���ĸ���˵��**************************************************************************
������������2014.3.13������С���ȵĸ��£����ڹ���ԭ��hadoop�汾��λ����hadoop-1.2.1.tar.gz������ϸ��Ҳ���иĶ���ʹ���������̸�����������Ͳ�����
��. �����
����Ի������������������jdk-6u19-linux-i586.bin��hadoop-1.2.1.tar.gz�����Է���������ϵͳLinux Cent OS 6.3��
1��JDK��װ��Java��������������
˵����1.CentOSĬ������£��ᰲװOpenOffice֮�����������Щ������ҪJava��֧�֣�����ϵͳĬ�ϻᰲװJDK�Ļ���������Ҫ�ض���Java��������ý�Ĭ�ϵ�JDK����ɾ����
2.�鿴Ĭ�ϵ�JDK���java -version
3.���������ɾ��Ĭ����װ�µ�JDK������֮��ص���������openoffice��Ҳ����֮ɾ�������ԣ�Ӧ����װ�µ�jdk��жϵͳĬ���Դ���jdk��
***ж��ϵͳ�Դ�ԭJDK�ķ���ʾ������ע�⣬�˲���Ӧ������jdk��װ��Ϻ���ִ����
�ն����룬�鿴gcj�İ汾�ţ�rpm -qa|grep jdk
�õ������
jdk-1.6.0_19-fcs.x86_64
java-1.6.0-openjdk-1.6.0.0-1.49.1.11.4.el6_3.x86_64
�ն����룬ж�أ�yum -y remove java java-1.6.0-openjdk-1.6.0.0-1.49.1.11.4.el6_3.x86_64
�ȴ�ϵͳ�Զ�ж�أ������ն���ʾ Complete��ж�����
1.1 JDK��װ(����ѡ���jdk��װ��root�û��£������������û�ʹ�á���ȻҲ����ѡ��װ������ָ���û��¡�)
root �û���½��ʹ������mkdir /usr/program�½�Ŀ¼/usr/program,���� JDK ��װ��jdk-6u19-linux-i586.bin���������Ƶ�Ŀ¼/usr/program������cd��������Ŀ¼��ִ�����./
jdk-6u13-linux-i586.bin��������������ϼ���װ��ɣ�����Ŀ¼�������ļ���/jdk1.6.0_19���˼�Ϊjdk���ɹ���װ��Ŀ¼��/usr/program/jdk1.6.0_13�¡�
1.2 java������������
root �û���½����������ִ�����vi /etc/profile��,�������������������û�������(ע��/etc/profile ����ļ�����Ҫ������ Hadoop�����û����õ�)��
# set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_19
export JRE_HOME=/usr/program/jdk1.6.0_19/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
��vi�༭�������������ݺ��˳�����ִ����������ʹ������Ч��
[root@localhost ~]#chmod +x /etc/profile ������ִ��Ȩ��
[root@localhost ~]#source /etc/profile��ʹ������Ч��
������Ϻ��������������룺java -version�������������Ϣ˵��java������װ�ɹ���
java version "1.6.0_19"
Java(TM) SE Runtime Environment (build 1.6.0_19-b03)
Java HotSpot(TM) Server VM (build 16.3-b01, mixed mode)
2��SSH��������֤���ã�SSH�������½Ӧ����hadoop��װ�������ڵ��û������ã����籾Hadoopα��Ⱥ���hadoop�û��£���SSH�������½Ӧ����hadoop�û���������

ע��Hadoop ��Ҫʹ��SSH Э�飬namenode ��ʹ��SSH Э������ namenode��datanode ���̣�α�ֲ�ʽģʽ���ݽڵ�����ƽڵ���DZ������������� SSH localhost��������֤��¼�ͻ᷽��ܶࡣʵ���ϣ���H adoop�İ�װ�����У��Ƿ��������¼���ؽ�Ҫ�ģ���������������������¼��ÿ������Hadoop����Ҫ���������Ե�¼��ÿ̨������DataNode�ϣ����ǵ�һ���Hadoop��Ⱥ����ӵ�����ٻ���ǧ̨���������һ����˵��������SSH���������¼���ڴ�����ѡ������SSHΪ�������¼ģʽ������
����Ϊ�����������¼����:
ע�⣺SSH�������½Ӧ����hadoop��װ�������ڵ��û������ã����籾Hadoopα��Ⱥ���hadoop�û��£���SSH�������½Ӧ����hadoop�û�������
���Ȳ鿴�ڡ���ǰ�û���(hadoop)�ļ������Ƿ����.ssh �ļ��У�ע��sshǰ���С�.��������һ�������ļ��У�����������鿴���ļ����Ƿ���ڡ�һ����˵����װSSHʱ���Զ��ڵ�ǰ�û��´�����������ļ��У����û�У������ִ���һ����
���������������hadoop�û��½��еģ�
[hadoop@localhost ~]$ls �Ca
����.ssh�ļ����Ѿ����ڡ�
�������������ע�����������в���˫���ţ������������ţ���
����һ����hadoop�û���¼���ն�ִ���������ssh-keygen -t rsa
[hadoop@localhost ~]$ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/hadoop/.ssh/id_rsa):&���س�Ĭ��·�� &
......
......
ͨ�����������/hadooop/.ssh/ Ŀ¼������id_rsa˽Կ��id_rsa.pub��Կ������/hadoop/.sshĿ¼��namenode�ڵ������������ã�
[hadoop@localhost .ssh]# cat id_rsa.pub > authorized_keys
������ϣ���ͨ��ssh ����IP �����Ƿ���Ҫ�����¼��
�����������߰������·�ʽ���ã�
����ǩ���ļ���
[hadoop@localhost ~]$ ssh-keygen -t dsa -P ' ' �Cf ~/.ssh/id_dsa
����һ�£�ssh-keygen����������Կ�� -t��ע�����ִ�Сд����ʾָ�����ɵ���Կ���ͣ�dsa��dsa��Կ��֤����˼������Կ���ͣ�-P�����ṩ���-fָ�����ɵ���Կ�ļ���(����~������ǰ�û��ļ��У���home/wade )�������������.ssh�ļ����´���id_dsa��id_dsa.pub�����ļ�������SSH��һ��˽Կ����Կ������������Կ�ס�
[hadoop@localhost ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
�����������ڰѹ�Կ�ӵ�������֤�Ĺ�Կ�ļ��С������authorized_keys��������֤�Ĺ�Կ�ļ���
�����������¼������������ϣ���ͨ��ssh ����IP �����Ƿ���Ҫ�����¼�����û����ʾ�������룬���������¼���óɹ���
���ȷʵ���óɹ��ˣ����ǻ��Dz����������½������ܾ���authorized_keys�ļ�û�з���Ȩ�ޣ�ִ�����chmod 600 ~/.ssh/authorized_keys ���ɣ�
3�� Hadoop��װ������
3.0.��������ר�ŵ�hadoop����û�
�����û��飺hadoop��Ȼ���ڴ��û����´���hadoop�û������ڰ�װϵͳ��ʱ����Ҳ�����ڰ�װ��֮���������������
[root@localhost ~]# groupadd hadoop
[root@localhost~]# useradd -g hadoop -d /home/hadoop hadoop
��hadoop�������������û���, -dָ���� hadoop���û���homeĿ¼��/home/hadoop��
[root@localhost~]# passwd hadoop [���û�hadoop���ÿ���]
Ȼ���ѹ��װHadoop
�� ��Hadoop��������hadoop-1.2.1.tar.gz
�� ������װĿ¼
[hadoop@localhost~] mkdir ~/hadoop-env
�� ��hadoop-1.2.1.tar.gz�������Ȼ���ѹ��
[hadoop@localhosthadoop_env]$ tar �Czxvf hadoop-1.2.1.tar.gz
ע����ѹ��װ�����ļ�/hadoop-1.2.1����Ϊhadoop����װ��/home/hadoop/hadoop-env/
hadoop-1. 2.1�ļ����£���
��������root�û�������hadoop�Ļ���������
���vi /etc/profile��
#set hadoop
export HADOOP_HOME=/home/hadoop/hadoop-env/ hadoop-1. 2.1
export PATH=$HADOOP_HOME/bin:$PATH
���ִ�����source /etc/profileʹ�����õ��ļ���Ч��
3.1 ����/home/hadoop/hadoop-env/ hadoop-1. 2.1/conf������Hadoop�����ļ�
3.1.1 ����hadoop-env.sh�ļ�
���ļ����vi hadoop-env.sh
���� # set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_19
�༭���˳���
3.1.2 ����core-site.xml
[hadoop@localhost conf]$ vi core-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000/</value> ע��9000����ġ�/��������
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-env/hadooptmp</value>
</property>
</configuration>
˵����hadoop�ֲ�ʽ�ļ�ϵͳ��������Ҫ��Ŀ¼�ṹ��һ����namenode�����ֿռ�Ĵ�ŵط���һ����datanode���ݿ�Ĵ�ŵط�������һЩ�������ļ���ŵط�����Щ��ŵط����ǻ���hadoop.tmp.dirĿ¼�ģ�����namenode�����ֿռ��ŵط�����
${hadoop.tmp.dir}/dfs/name, datanode���ݿ�Ĵ�ŵط����� ${hadoop.tmp.dir}/dfs/data���������ú�hadoop.tmp.dirĿ¼����������ҪĿ¼���������Ŀ¼���棬����һ����Ŀ¼�������õ�������/home/hadoop/hadoop-env/
hadoop-1. 2.1/hadooptmp,��Ȼ���Ŀ¼�����Ǵ��ڵ���
3.1.3 ����hdfs-site.xml
[hadoop@localhost conf]$ vi hdfs-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.1.4 ����mapred-site.xml
[hadoop@localhost conf]$ vi mapred-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3.1.5 ����masters�ļ���slaves�ļ���һ��˶��ļ���Ĭ�����ݼ�Ϊ�������ݣ���������������
[hadoop@localhost conf]$ vi masters
localhost
//ע�⣬�������ļ��е�localhost��������IP:127.0.0.1 ,��[hadoop@localhost ~]�е�localhost������һ�������������߲��Եȣ������������������ַ�����
[hadoop@localhost conf]$ vi slaves
localhost
ע����Ϊ��α�ֲ�ģʽ�£���Ϊmaster��namenode����Ϊslave��datanode��ͬһ̨�����������������ļ��е�ip��һ���ġ�
3.1.6 ��������IP�������� (��һ���dz���Ҫ������)
[root@localhost ~]# vi /etc/hosts
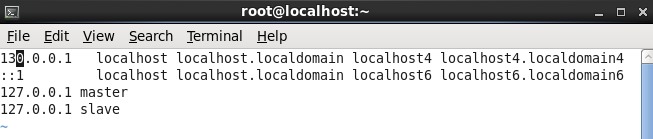
ע����Ϊ����α�ֲ�ģʽ�£�����master��slave��һ̨����
���䣺������������localhost�����������Լ�ָ��һ��������������Ҫ������������������á�
1.�༭��������
[root@localhost ~]# vi /etc/hostname
������mycentos
[root@localhost ~]# vi /etc/sysconfig/network

2.��������IP�������� (��һ���dz���Ҫ������)
[root@mycentos ~]# vi /etc/hosts

ע����Ϊ����α�ֲ�ģʽ�£�����master��slave��һ̨����
˵����������λ�õ����ñ���Э��һ�£�Hadpoop�������������������������÷dz���Ҫ��
���������������û�����������������õ�mycentos������������������׳�������û��ǽ���������Ϊmaster����������ʹ127.0.0.1 master��Ӧ��
4�� Hadoop����
4.1 ���� /home/hadoop/hadoop-env/ hadoop-1. 2.1/binĿ¼�£���ʽ��namenode
[hadoop@localhost bin]$ hadoop namenode -format
Ȼ�������ʾѡ����Ӧ������������ɸ�ʽ����
4.2����hadoop�����
��/home/hadoop/hadoop-env/ hadoop-1. 2.1/binĿ¼�£�ִ��start-all.sh����
������ɺ���[root@master bin]# jps����鿴hadoop�����Ƿ�������ȫ�����������Ӧ�������½��̣���������ʾ��

����hadoopα�ֲ�ʽ��Ⱥ�ɹ���
˵����1.secondaryname��namenode��һ�����ݣ�����ͬ�����������ֿռ���ļ����ļ����map��ϵ����������������һ̨�����ϣ�����master����֮������ͨ��secondaryname���ڵĻ����һ����ֿռ䣬���ļ����ļ����map��ϵ���ݣ��ָ�namenode��
2.����֮����/usr/local/hadoop/hadoop-1.0.1/hadooptmp�µ�dfs�ļ����������
dataĿ¼���������ŵ���datanode�ϵ����ݿ����ݣ���Ϊ�����õ��ǵ���������name�� data����һ�������ϣ�����Ǽ�Ⱥ�Ļ���namenode���ڵĻ�����ֻ����name�ļ��У���datanode��ֻ����data�ļ��С�
���䣺
�ڴ�����У��ڴ˻��ڳ��ֵ�������࣬���������������̲������������Ҫô��datanode����������������namenode����TaskTracker�����쳣������ķ�ʽ���£�
1.��Linux�¹رշ���ǽ��ʹ��service iptables stop����ر�hadoop��stop-all.sh
1) ��������Ч
������ chkconfig iptables on
�رգ� chkconfig iptables off
2) ��ʱ��Ч��������ʧЧ
������ service iptables start
�رգ� service iptables stop
��Ҫ˵�����Ƕ���Linux�µ���������������������ִ�п����رղ�����
�ڿ����˷���ǽʱ�����������ã�������ض˿ڣ�
��/etc/sysconfig/iptables �ļ��������������ݣ�
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
��ʼ��ʹ�õ���service��ʽ�������ܲ����ã����ʹ����chkconfig������ʽ����Ч��
2.�ٴζ�namenode���и�ʽ����/home/hadoop/hadoop-env/ hadoop-1. 2.1/binĿ¼��ִ��hadoop namenode -format����
3.�Է�������������
4.�鿴datanode����namenode��Ӧ����־�ļ�����־�ļ�������/home/hadoop/hadoop-env/ hadoop-1. 2.1/logsĿ¼�¡�
5.�ٴ���/binĿ¼����start-all.sh�����������н��̣�ͨ�����ϵļ�������Ӧ���ܽ��������������ȫ�������ˡ�
6.��ִ��hadoop�������ʱ�����dz���������ʾ��

�����������鿴hadoop-1.2.1��hadoop��hadoop-config.sh�ű������ֶ���HADDP_HOME�����ж�
����������£�
��hadoop-env.sh ������һ������������export HADOOP_HOME_WARN_SUPPRESS=true
4.3 �鿴��Ⱥ״̬
[hadoop@localhost bin]$ hadoop dfsadmin -report
4.4����WEBҳ���²鿴Hadoop�������
4.4.1��IE��������벿��Hadoop��������IP��http://localhost:50070��
ʾ��ͼ��
4.4.2���룺http://localhost:50030
ʾ��ͼ��
5. Hadopʹ��(һ����������wordcount)
���������ı��д��������ij���WordCount��Hadoop��Ŀ¼�µ�java�����hadoop-examples-1.2.1.jar�У�ִ�в������£�
5.1. ��������hadoop���н���:bin/start-all.sh��Ȼ����/home/hadoop/hadoop-env/
hadoop-1. 2.1/���½�Ŀ¼test������������)����test�´����ı�file01��file02���ֱ������������ʡ�
5.2.��hdfs�ֲ�ʽ�ļ�ϵͳ����Ŀ¼input��
[hadoop@localhost bin]$hadoop fs -mkdir input
Ȼ�����ʹ��[hadoop@localhost bin]$hadoop fs -ls�鿴:
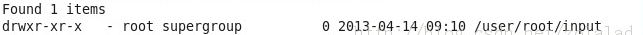
ע��ɾ��Ŀ¼��[hadoop@localhost bin]$hadoop fs -rmr ***��ɾ���ļ���hadoop
fs -rm ***
5.3.�뿪hodoop�İ�ȫģʽ[hadoop@localhost bin]$hadoop dfsadmin �Csafemode leave
ע��Hadoop�İ�ȫģʽ�������[hadoop@localhost bin]$hadoop dfsadmin �Csafemode enter/leave/get/wait
Hadoop��HDFSϵͳ�ڰ�ȫģʽ��ֻ�ܽ��С��������������ܽ����ļ��ȵ�ɾ�����������²�����
5.4.��������linux�ļ�ϵͳ���Ƶ�HDFS�ֲ�ʽ�ļ�ϵͳ�е�input�ļ�������
[hadoop@localhost bin]$hadoop fs -put /home/hadoop/hadoop-env/hadoop-1.2.1/test/* input
5.5.ִ�������е�WordCount��
[hadoop@localhost bin]$hadoop jar/home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar wordcount
input output
���

5.6.�鿴ִ�н��:[hadoop@localhost bin]$hadoop dfs -cat
output/*

5.7.ִ����Ϻɽ���web����ˢ�²鿴running job��completed
job����ʾ��
5.8.�ر�hadoop���н���:[hadoop@localhost
bin]$stop-all.sh��
˵�����������ò��豾�����Զ���ʵ����֤���ǿ��еģ����ܲ������ŵ����÷�������ӭѧ��ָ��������