1.项目背景
公司目前已经部署了分布式文件存储和计算平台(已经上线hadoop,spark,hbase等),业务数据已经以文件的形式存储在hdfs中,业务部门经常提出各种数据需求,因此需要基于spark计算平台开发各种计算任务。公司目前的分布式平台只有一套线上环境,为了避免在学习、测试spark开发的过程中对线上环境造成污染,经过运维同事的规划,提供一台配置较高的pc用于搭建单机(standalone模式)的hadoop
+ spark测试环境,希望通过该环境 了解和熟悉 hadoop,spark的运行模块,机制,流程以及常用操作命令;通过ide开发spark的经典例子WordCount向spark平台提交计算和查看结果。(个人qq:498676231欢迎同仁交流和指正下面博客内容中的问题和错误)
2.主要技术和工具清单ref-software-list.1
3.hadoop + spark 环境搭建简单说明
安装过程中的工具清单见ref-software-list.1,maven,jdk,scala的安装过程比较简单,去各自官网下载对应版本的软件然后解压并配置环境变量即可正常使用了。下面简单介绍一下hadoop,spark的standalone模式的安装(安装在单台主机,伪集群模式),安装方式一般有两种:
1.去官网下载编译好的对应版本的软件,解压到指定目录下,配置环境变量和各自的配置文件,然后启动相应的服务即可。
2.通过linux自带的安装助手工具安装,以本次centos中的实际操作为例,通过
yum install softname1 softname2 ... -y #如果不是root用户sudoyum install softname1 softname2 ... -y
安装相关的平台组件,详细的帖子可以参考
这里补充几个问题点:
q1. yum install 命令安装软件时,命令行中没有显示指定软件版本,ref-software-list.1中我们要安装指定版本的hadoop和yarm该如何控制版本信息呢
a1.
通过配置yum源指定hadoop的版本为cdh5, yum install 命令会根据配置的baseurl自动去适配hadoop的版本,因spark的安装依赖hadoop,hadoop安装完成(版本确定),安装spark时会根据已有的hadoop适配其自身的版本。
本次安装hadoop yum源配置如下,在/etc/yum.repos.d/cdh5.repo (如果没有对应的文件或者目录需要自己创建)添加如下内容:
#PackagesforCloudera'sDistributionforHadoop,Version5,onRedHatorCentOS6x86_64
name=Cloudera'sDistributionforHadoop,Version5
gpgcheck=1
q2. 本次单机模式安装的组件
a2.
hadoop-hdfs hadoop-client hadoop-hdfs-namenode hadoop-hdfs-datanode spark-master spark-worker spark-history-server
安装命令如下:
hadoop-hdfs 相关安装命令
yum install hadoop hadoop-hdfs hadoop-client hadoop-doc hadoop-debuginfo hadoop-hdfs-namenode
yum install hadoop-hdfs-datanode -y
spark 相关安装命令
yum install spark-core spark-master spark-worker spark-history-server -y
q3. 需要修改的相关配置文件
a3.
/etc/hosts 中追加 172.168.xx.xxcdh1 #172.168.xx.xx是当前安装主机的ip,cdh1是hostname产生的网络名称
/etc/sysconfig/network 中内容如下:
NETWORKING=YES
HOSTNAME=cdh1
GATEWAY=172.168.xx.xx
/etc/hadoop/conf 目录下hdfs相关配置文件如下:
core-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cdh1:8020</value>
</property>
<!--
<property>
<name>fs.default.name</name>
<value>hdfs://cdh1:8020/</value>
</property>
-->
</configuration>
hdfs-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///var/lib/hadoop-hdfs/cache/hdfs/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///var/lib/hadoop-hdfs/cache/hdfs/dfs/data</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<xml version="1.0">
<xml-stylesheet type="text/xsl" href="configuration.xsl">
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>cdh1:9001</value>
</property>
</configuration>
/etc/spark/conf 目录下相关配置文件
spark-defaults.conf
spark.master spark://cdh1:7077
spark.eventLog.enabled true
spark.eventLog.dir /user/spark/applicationHistory
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
spark.yarn.historyServer.address http://cdh1:18080
spark-env.sh中添加修改:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=/user/spark/applicationHistory"
/etc/profile中添加spark的环境变量export SPARK_HOME=/usr/lib/spark
q4. 启动相关的组件服务
a4.
首先启动hdfs的namenode服务,(第一次)启动前先格式化namenode
hadoop namenode -format
然后执行启动hdfs namenode的命令
/etc/init.d/hadoop-hdfs-namenode restart
#抛出/var/lib/hadoop-hdfs/cache/hdfs/dfs/name/current/VERSION 权限不够的问题
#因为hadoop安装完成之后,hdfs对文件的处理是hdfs用户,该用户没有/var/lib/hadoop-hdfs目录的操作权限
执行如下命令给hdfs分配/var/lib/hadoop-hdfs目录的操作权限
chown hdfs.hdfs /var/lib/hadoop-hdfs -R
依次执行以下命令:
/etc/init.d/hadoop-hdfs-namenode
restart
/etc/init.d/hadoop-hdfs-datanode
restart
/etc/init.d/spark-master
restart
/etc/init.d/spark-worker
restart
/etc/init.d/spark-history-server
restart
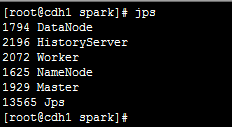
所有服务启动之后,执行jps,查看所有相关的已经正常启动的服务
![]()
![]()
运行一个spark自带的例子检验一切是ok的。
$SPARK_HOME/bin/run-example SparkPi 10,输出如下(无异常抛出):
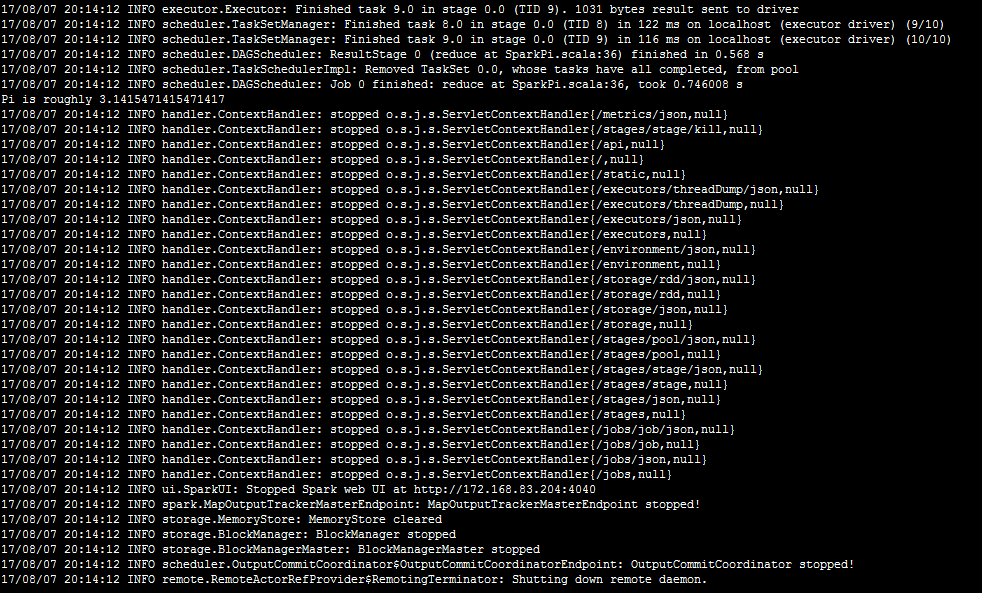
![]()
到目前为止hadoop和spark的安装基本完成!!!
4.scala + spark 项目集成与打包
hadoop,spark搭建完成之后,接下来就是基于spark(目前支持java,scala,python,r等开发语言)写一个"hello world"了。选择scala作为开发语言(spark是基于scala开发的开源框架,先前版本似乎是不支持java的,最近两年发布的版本已经提供了相关的java
api开发接口)。使用scala开发spark 官网推荐的标配是idea+sbt(个人之前一直习惯使用eclipse + maven开发,做这个例子的时候,开始使用的ide是scala-IDE,就是普通eclipse中安装了一个开发scala的插件。在本地安装完scala之后配置scala-IDE的全局scala-library,工程里面的代码通过按住ctrl链接过去的源码是乱的,另外工程中常报一些奇怪的错误,其原因要么是个人配置有问题要么是eclipse
和 scala-plugin的兼容性不好,于是放弃了scala-IDE;另外maven是良好支持scala相关的包资源管理的,因此个人还是选择了idea + maven 作为开发环境),示例选择了idea + maven,idea里不直接支持scala的开发,也需要安装插件。
两点容易出问题的地方:
a1. 配置scala自身的sdk的时候按照 Configure ->Projects Default ->Project Structure ->Global Libraries ->+ ->Scala SDK 没有弹框反应,这应该是版本兼容性的问题(我之前的idea是ver-2017.2,后来改成ver-2016.3)
a2. 新建基于maven的scala工程时不要勾选 Create from archetype 然后使用 scala-archetype-simple框架自动生成工程,idea会自动导入scala的相关类库和已经指定的类库冲突;按照文档要求生成空的maven工程,删除自动产生的目录在main目录下手工创建scala,test,resources等目录,将scala框架添加到这个工程(在工程上面右键选择
Add Framework Support...),将scala,test,resources 标记为资源的根目录在它们各自上面右键Mark Directory as -> Sources Root。
到此一个新的基于maven的scala空工程已经建立完成,接下来可以往这个工程中新建类,添加相关依赖和打包执行。为了稍微增加一点演示的复杂度,从github上找了一个演示例子learning-spark,工程中同时包含java和scala的代码,希望能同时编译java和scala代码并将相关的依赖jar打包并最终生成一个可执行的jar(fat
编译模式),另外还有thin 编译模式(执行jar和依赖jar分开,依赖jar放在服务器端,每次只需要在本地编译执行jar并上传到服务器,避免频繁传输过大的jar造成网络负载重),参考Scala
+ Spark +Maven之Helloworld
将该工程down下来之后,找到mini-complete-example目录(该目录下包含一个精简版的实例),删除除src和pom.xml以外的所有文件,
将该工程导入idea中,修改pom文件内容(特别注意网上有些讲解scala + spark + maven工程打包的时候在pom.xml文件的dependency中引入了scala-library,scala-compiler等包,而客户端开发环境本身就安装了scala,自然包含了这些包,因此这些依赖引用都要移除掉,本工程中只需要引入spark-core这个依赖包),完整的pom.xml文件如下:
<project>
<groupId>com.oreilly.learningsparkexamples.mini</groupId>
<artifactId>learning-spark-mini-example</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>example</name>
<packaging>jar</packaging>
<version>0.0.1</version>
<repositories>
<repository>
<id>jboss</id>
<name>Maven of jboss.org</name>
<url>http://repository.jboss.org/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
<layout>default</layout>
</repository>
<repository>
<id>oschina</id>
<name>Maven of oschina.net</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
<layout>default</layout>
</repository>
<repository>
<id>spring-libs-snapshot</id>
<url>http://repo.spring.io/libs-snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>Akka repository</id>
<url>http://repo.akka.io/releases</url>
</repository>
<repository>
<id>scala-tools</id>
<url>https://oss.sonatype.org/content/groups/scala-tools</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/releases</url>
</repository>
<repository>
<id>twitter</id>
<url>http://maven.twttr.com/</url>
</repository>
<repository>
<id>central2</id>
<url>http://central.maven.org/maven2/</url>
</repository>
<repository>
<id>central</id>
<name>Maven Repository Switchboard</name>
<layout>default</layout>
<url>http://repo2.maven.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.6.3</spark.version>
<scala.version>2.10</scala.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main</sourceDirectory>
<resources>
<resource>
<filtering>true</filtering>
<directory>src/main/java</directory>
<includes>
<include>*.*</include>
</includes>
</resource>
<resource>
<filtering>true</filtering>
<directory>src/main/scala</directory>
<includes>
<include>*.*</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<!-- 这是个编译java代码的 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<!-- 这是个编译scala代码的 -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>1.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.oreilly.learningsparkexamples.mini.scala.WordCount</mainClass>
</transformer>
<!--
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
-->
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
在该工程的根目录下执行mvncleanscala:compilecompilepackage-DskipTests
将在target目录中生成一个learning-spark-mini-example-0.0.1.jar文件 (大约88M),该jar可以提交到spark平台执行
5.向spark 提交任务与执行
演示程序是通过map-reduce的方式统计文本中的word数量,为此先用一个数据生产程序生成包含若干数据行的若干文件(本例中产生100个文件每个文件1000000。以目前spark的计算能力,测试集完全可以更大,考虑是单机伪集群,这个测试集合只作为展示,不考察其实际计算能力)。文件集合在本地,需要上传到hadoop-hdfs中,在hadoop-hdfs中构建如下目录:
hdfsdfs-mkdir-p/user/hadoop/data #构建hdfs内部文件目录
hdfsdfs-mkdir-p/user/spark#spark相关的路径spart-history-server
中eventLog.dir配置该目录的applicationHistory中
hdfs dfs -put datadir/*.txt /user/hadoop/data#datadir/*.txt
是本地数据文件路径 /user/hadoop/data 是hdfs中的文件路径
将learning-spark-mini-example-0.0.1.jar拷贝到服务器,通过spark-submit命令提交任务:
来自官网的使用说明:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
本例中的执行实例:
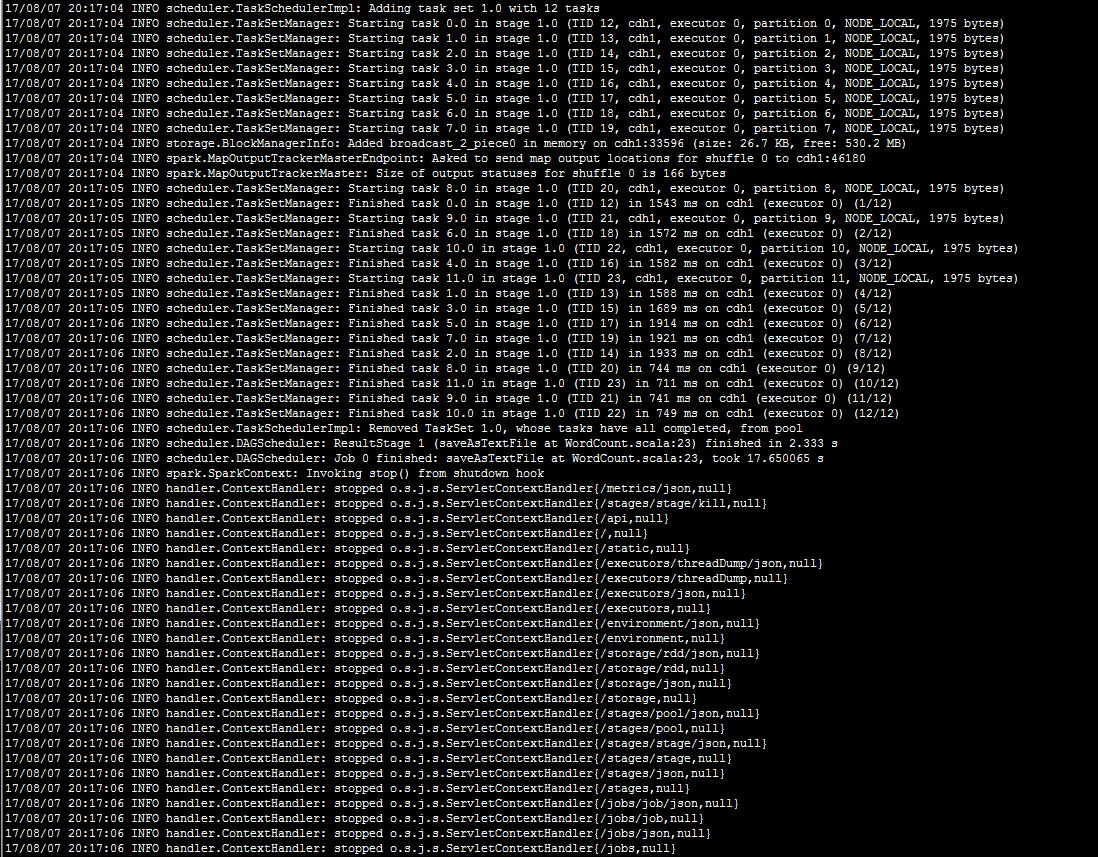
spark-submit --class com.oreilly.learningsparkexamples.mini.scala.WordCount --master spark://cdh1:7077 /user/spark/learning-spark-mini-example-0.0.1.jar hdfs://cdh1:8020/user/hadoop/data/sample_age_data1*.txt /user/spark/stat_rs.txt
执行截图(没有异常抛出,执行成功)
![]()
![]()
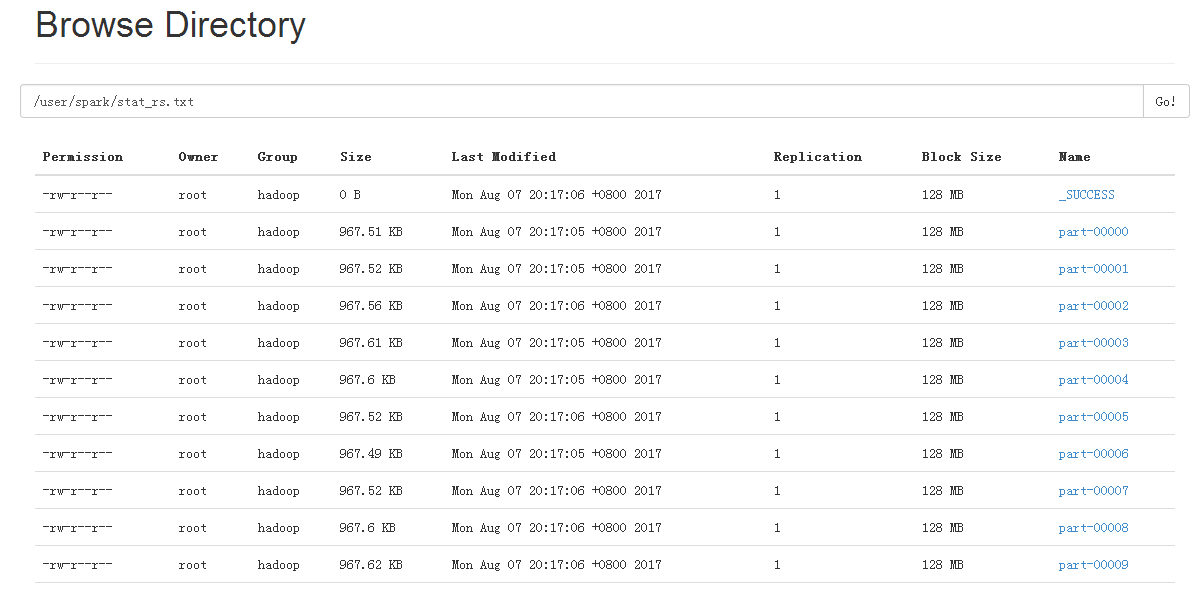
stat_rs.txt文件输出结果
![]()
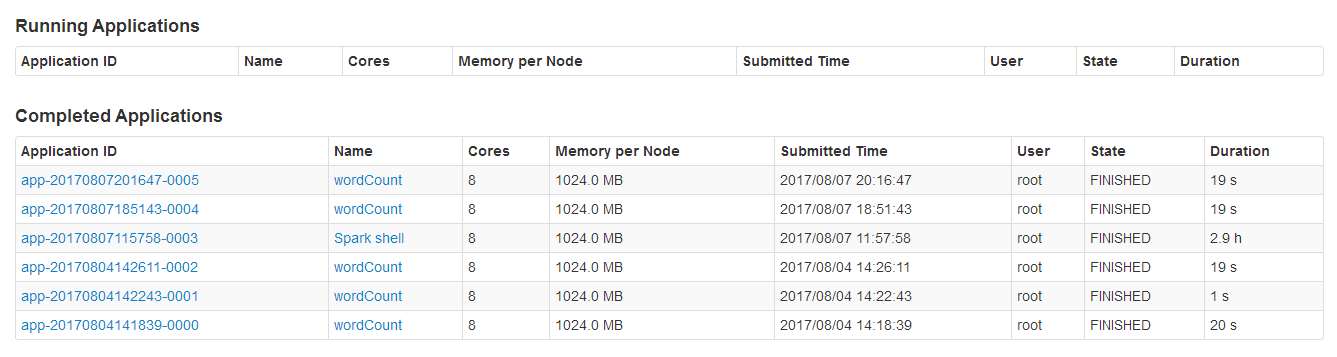
spark监控页面的历史任务提交记录(spark-history-server的配置是有效的,能记录到历史的任务提交记录)
6.参考文章
1.http://www.scala-lang.org/
2.http://hadoop.apache.org/
3.http://spark.apache.org/
4.http://maven.apache.org/plugins/maven-shade-plugin/
5.http://maven.apache.org/plugins/maven-resources-plugin/
6.https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice1/index.html
7.http://www.jianshu.com/p/ecc6eb298b8f
8. http://abcve.com/use-cdh5-install-hadoop-cluster/
9. https://www.zybuluo.com/sasaki/note/242142
10.https://www.cloudera.com/documentation/enterprise/5-4-x/topics/cdh_qs_mrv1_pseudo.html
11.http://blog.javachen.com/2013/04/06/install-cloudera-cdh-by-yum
12.http://dataunion.org/10345.html