Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统。最核心的模块包括Hadoop Common、HDFS与MapReduce。
HDFS
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。采用Java语言开发,可以部署在多种普通的廉价机器上,以集群处理数量积达到大型主机处理性能。
HDFS
架构原理
HDFS采用master/slave架构。一个HDFS集群包含一个单独的NameNode和多个DataNode。
NameNode作为master服务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户提供了一个单一的命名空间。
DataNode作为slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。
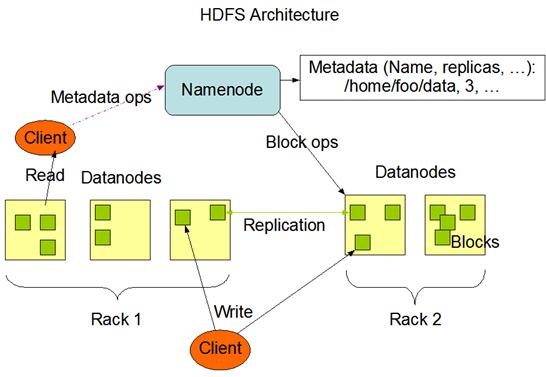
下图为HDFS系统架构图,主要有三个角色,Client、NameNode、DataNode。

文件写入时:
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
当文件读取:
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的block块信息、及其block块所在DataNode的信息。
Client读取文件信息。
HDFS
数据备份
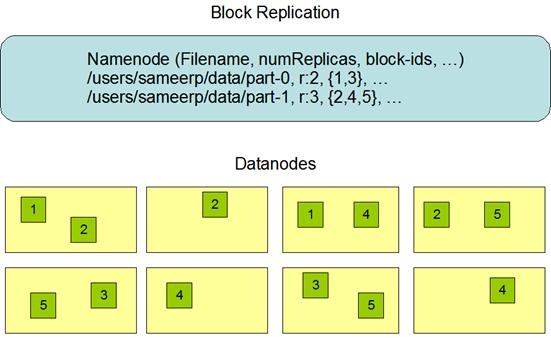
HDFS被设计成一个可以在大集群中、跨机器、可靠的存储海量数据的框架。它将所有文件存储成block块组成的序列,除了最后一个block块,所有的block块大小都是一样的。文件的所有block块都会因为容错而被复制。每个文件的block块大小和容错复制份数都是可配置的。容错复制份数可以在文件创建时配置,后期也可以修改。HDFS中的文件默认规则是write one(一次写、多次读)的,并且严格要求在任何时候只有一个writer。NameNode负责管理block块的复制,它周期性地接收集群中所有DataNode的心跳数据包和Blockreport。心跳包表示DataNode正常工作,Blockreport描述了该DataNode上所有的block组成的列表。
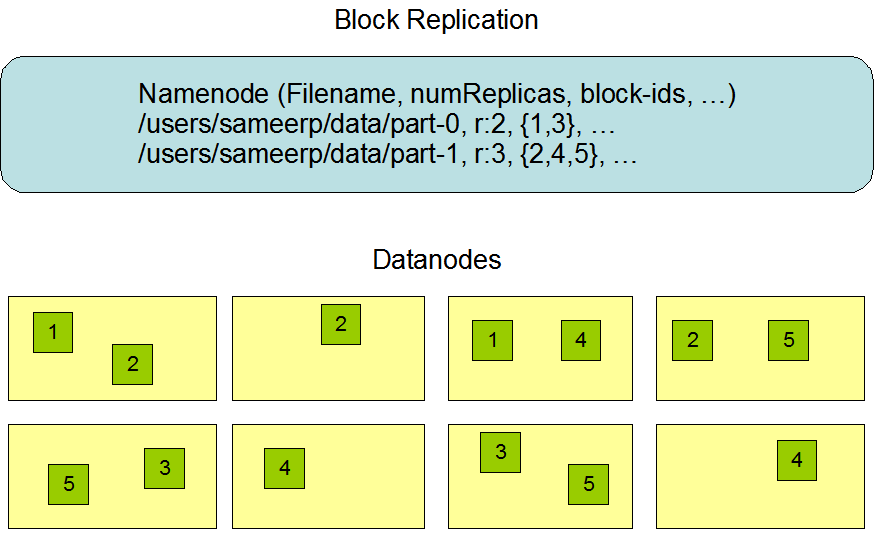
备份数据的存放:
备份数据的存放是HDFS可靠性和性能的关键。HDFS采用一种称为rack-aware的策略来决定备份数据的存放。通过一个称为Rack Awareness的过程,NameNode决定每个DataNode所属rack id。缺省情况下,一个block块会有三个备份,一个在NameNode指定的DataNode上,一个在指定DataNode非同一rack的DataNode上,一个在指定DataNode同一rack的DataNode上。这种策略综合考虑了同一rack失效、以及不同rack之间数据复制性能问题。
副本的选择:
为了降低整体的带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个rack上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么将首先尝试读本地数据中心的副本。
安全模式:
系统启动后先进入安全模式,此时系统中的内容不允许修改和删除,直到安全模式结束。安全模式主要是为了启动检查各个DataNode上数据块的安全性。
MapReduce
MapReduce
来源
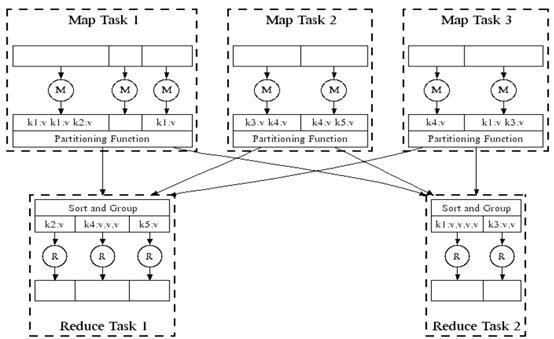
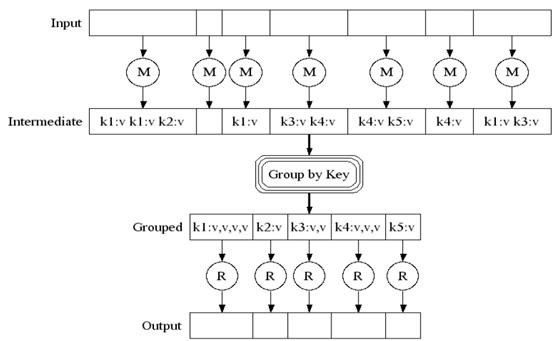
MapReduce是由Google在一篇论文中提出并广为流传的。它最早是Google提出的一个软件架构,用于大规模数据集群分布式运算。任务的分解(Map)与结果的汇总(Reduce)是其主要思想。Map就是将一个任务分解成多个任务,Reduce就是将分解后多任务分别处理,并将结果汇总为最终结果。熟悉Function Language的人一定感觉很熟悉,不是什么新的思想。
MapReduce
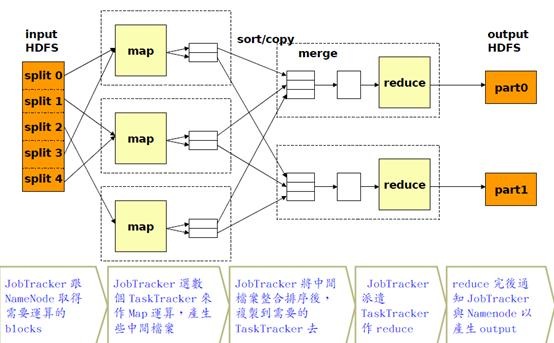
处理流程
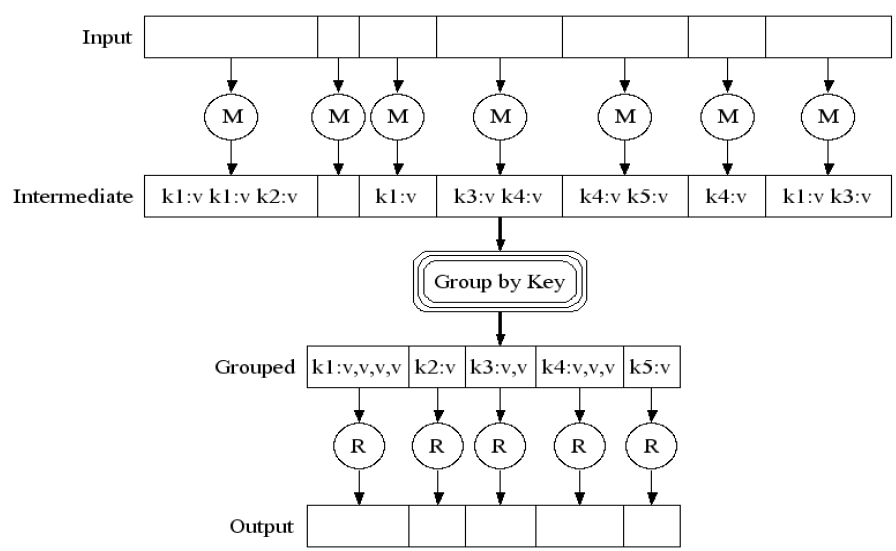

上图就是MapReduce大致的处理流程。在Map之前,可能还有对输入数据的Split过程以保证任务并行效率,在Map之后可能还有Shuffle过程来提高Reduce的效率以及减小数据传输的压力。
Hadoop
Hadoop被定位为一个易于使用的平台,以HDFS、MapReduce为基础,能够运行上千台PCServer组成的系统集群,并以一种可靠、容错的方式分布式处理请求。
Hadoop
部署
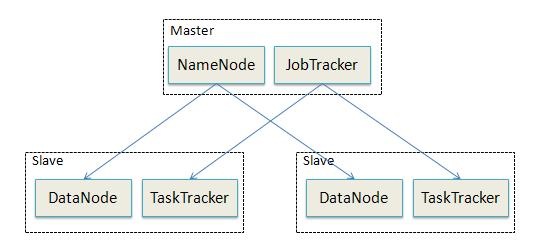
下图显示Hadoop部署结构示意图
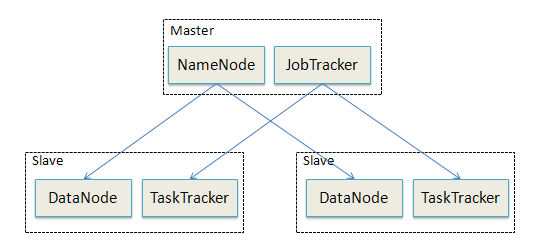
在Hadoop的系统中,会有一台master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台slave,每一台slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
Hadoop
处理流程
在描述Hadoop处理流程之前,先提一个分布式计算最为重要的设计原则:Moving Computation is Cheaper than Moving Data。意思是指在分布式计算中,移动计算的代价总是低于移动数据的代价。本地计算使用本地数据,然后汇总才能保证分布式计算的高效性。
下图所示Hadoop处理流程:
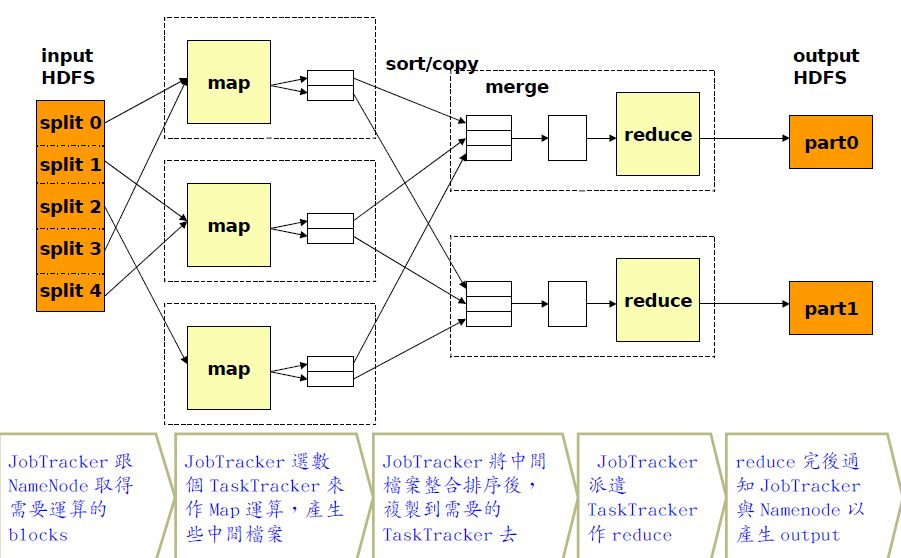
Hadoop
安装
到目前为止,已经完成了基础理论的介绍,下面介绍Hadoop的安装过程。
硬件条件:3台PCServer。
|
HostName
|
IP
|
Plan
|
|
fa1
|
10.143.20.211
|
master
|
|
fa2
|
10.143.20.212
|
slave
|
|
fa3
|
10.143.20.213
|
slave
|
预装:操作系统Linux,JDK1.6,ssh,并且保证 sshd一直运行。
安装步骤:
1. 在所有机器上新建hadoop用户,home目录设置为/home/hadoop/
2. 下载Hadoop(这里下载的是hadoop-0.18.3),先解压到master上。
3. 进入/home/hadoop/hadoop-0.18.3/conf目录,修改hadoop-site.xml文件。
hadoop-site.xml文件默认配置为空,它主要被用来覆盖hadoop-default.xml的系统级配置。
<property>
<name>fs.default.name</name>
<value>hdfs:// 10.143.20.211:8980/</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs:// 10.143.20.211:8990/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-0.18.3/tmp/</value>
</property>
<property>
<name> dfs.block.size </name>
<value>51200</value>
</property>
4. 进入/home/hadoop/hadoop-0.18.3/conf目录,修改hadoop-env.sh文件。
export JAVA_HOME= /usr/lib/java6
5. 建立master到slave的ssh访问授权。
6. 通过scp将master上的hadoop-0.18.3目录拷贝到所有slave同名目录上。
7. 在每个slave上修改hadoop-env.sh文件,设置JAVA_HOME。
8. 修改profile文件,扩展PATH路径。
export HADOOP_HOME=/home/hadoop/hadoop-0.18.3/
export PATH=$PATH:$HADOOP_HOME/bin
9. 在master上执行hadoop namenode -format
10. 执行start-all.sh启动。
参考文献:
http://hadoop.apache.org/hdfs/docs/current/hdfs_design.html
http://hadoop.apache.org/mapreduce/docs/current/mapred_tutorial.html
http://www.slideshare.net/waue/hadoop-map-reduce-3019713
http://www.infoq.com/cn/articles/hadoop-intro
{kind=link}
{kind=link}
{kind=link}