版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/alphags/article/details/53351627
摘要
调试是学习代码流程,查找BUG,修复错误的重要方法,本文内容主要是讲述在前两篇内容的基础上如何配置Idea和hadoop以使其可以使用远程调试(打断点、逐行运行等)功能
Idea 设置
首先需要将hadoop源码的maven工程导入idea中(这个就不讲了),导入后呢我们可以在模块hadoop-hdfs-project 下找到hadoop namenode启动的源码(在package:org.apache.hadoop.hdfs.server.namenode中,前边第二节我们修改过的)我们在其第一行设置一个断点
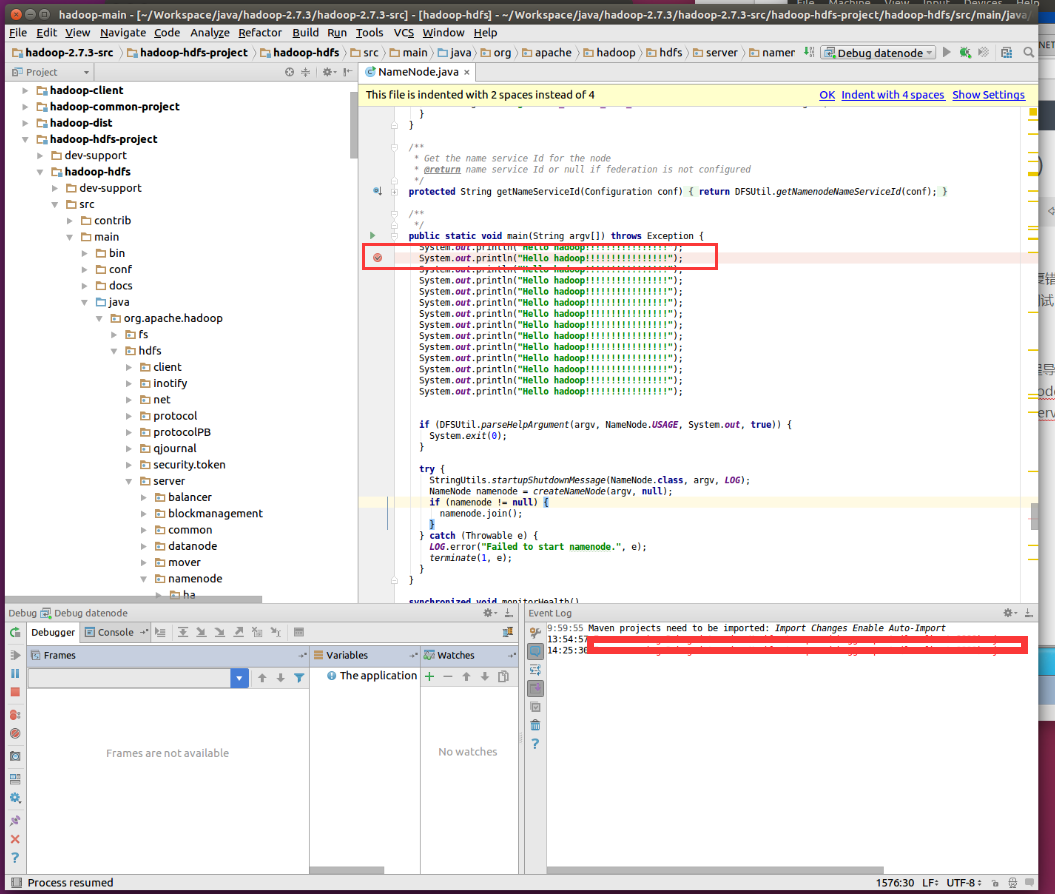
然后依次点击【Run】―【EditConfiguration】在弹出的窗口中点击左上角+号选择remote,如下图所示
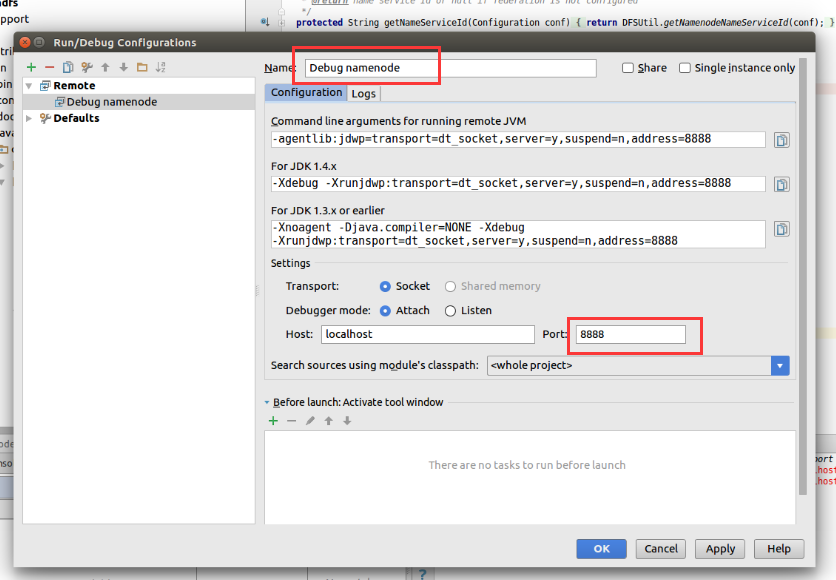
修改名称为Debug namenode,修改端口号为8888
在这里注意
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888
我们对这行代码就行一个简单修改,要将其放到hadoop的启动脚本当中
最后点击【OK】保存即可。
hadoop设置
接下来我们需要把下边这段代码放到hadoop启动脚本中合适的位置
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888
因为我们当前环境是伪分布式模式,如果我们将上述调试代码放到全局的HADOOP_OPTS中的话,那么所有的进程(不只有NameNode 还有DateNode等) 启动的时候都会去绑定8888号端口,这样如果NameNode先启动占用了8888号端口,而DateNode 再试图去绑定8888端口时由于已被NameNode占用从而报错启动失败。因此我们需要将其放到合适的位置
我们在第一节序言部分已经简单看过其启动脚本,这里我们仍是需要修改hdfs这个脚本。
我们看其134行,启动namenode部分的代码
if [ "$COMMAND"="namenode"];then
CLASS='org.apache.hadoop.hdfs.server.namenode.NameNode'
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_NAMENODE_OPTS"
elif [... ...
通过上述代码可以看出我们只需要将我们要加的代码放到上述代码的if …elif之间就可以了,使其只有在启动namenode的时候生效,所以我们修改代码如下
if [ "$COMMAND"="namenode"];then
CLASS='org.apache.hadoop.hdfs.server.namenode.NameNode'
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_NAMENODE_OPTS"
HADOOP_OPTS="$HADOOP_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888"
elif [... ...
(通过阅读这里的代码我们也可以看出,我们也可以通过设置环境变量HADOOP_NAMENODE_OPTS 使其值为 -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888 一样可以生效)
测试
经过上述设置接下来我们启动hadoop,看我们打的断点是否生效
$stop-dfs.sh
$start-dfs.sh
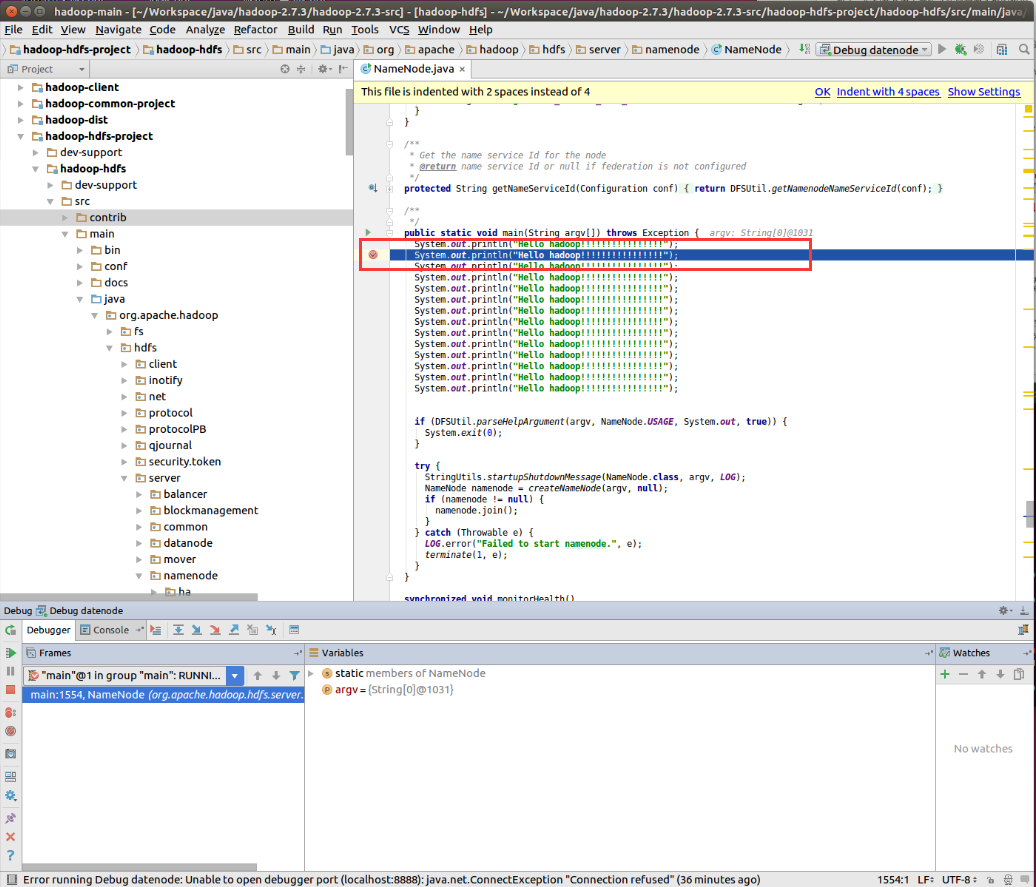
同时在Idea中点击【】【】选择Debug namenode
可以看到程序停在了我们设置断点的地方
总结
其实以上调试内容,不仅仅可以调试hadoop,其他一些程序也可以使用类似的方法进行远程调试。