打开Ubuntu终端
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
su - hadoop
sudo apt-get update
sudo apt-get install openssh-server
ssh localhost
exit
cd ~/.ssh/
ssh-keygen -t rsa
输入完 $ ssh-keygen -t rsa 语句以后,需要连续敲击三次回车,如下图:
cat ./id_rsa.pub >> ./authorized_keys
ssh localhost
如果不需要输入密码(出现下图,既安装成功)
前面有一篇单独安装JDK的,就不在此再次写了https://blog.csdn.net/Asdzxc968/article/details/88314696
http://mirrors.hust.edu.cn/apache/hadoop/common/
sudo mkdir /hadoop
我的hadoop放在下载文件夹下(中文的乌班图)
sudo tar -zxvf /home/hadoop/下载/hadoop-2.7.7.tar.gz
2、移动文件
sudo mv hadoop-2.7.7 /hadoop
注意此时我实在下载目录下
打开配置文件
sudo gedit /etc/profile
环境变量(在打开的文件,写入环境变量)
export HADOOP_HOME= /hadoop/hadoop-2.7.7
export PATH= ${HADOOP_HOME} /bin:${HADOOP_HOME} /sbin:$PATH
使用source /etc/profile 命令使配置文件生效。
在终端输入
hadoop version
注意,和测试JAVA的环境变量不同的是,这里的version前面没有-
需要修改四个文件,四个文件都在hadoop_path/etc/hadoop/ hadoop_path hadoop安装目录
< configuration> < propert> < name> </ name> < value> </ value> </ propert> </ configuration> 2、hdfs-site.xml
< configuration> < property> < name> </ name> < value> </ value> </ property> </ configuration> 3、mapred-site.xml
注意:目录没有这个文件,但是有一个mapred-site.xml.template ,复制并重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
< configuration> < property> < name> </ name> < value> </ value> </ property> </ configuration> 4、yarn-site.xml
< configuration> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> </ configuration> hdfs namenode -format
启动的时候遇到一个问题,找不到JAVA_HOME,但是echo $JAVA_HOME 就可以获取到
启动的时候遇到了一个问题,提示权限不够,无法启动
chmod a+w $HADOOP_HOME
增加权限 解决。
start-yarn.sh
可以使用start-all.sh 启动所有进程
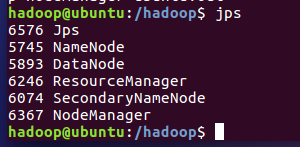
jsp 命令查看所有进程
http://localhost:8088 http://localhost:50070
stop-all.sh 一次推出所有进程stop-dfs.sh stop-yarn.sh 分别关闭进程