ǰ��
������һƪ���Ƿ�����һ��MapReduce��ִ���е�һЩϸ�����⣬��һƪ��������MapReduce���д����Ļ������̺�ԭ����
����Mapreduce��һ���ֲ�ʽ�������ı�̿�������û�����������hadoop�����ݷ���Ӧ�á��ĺ��Ŀ�ܡ�
����Mapreduce���Ĺ��������û���д��ҵ����������Դ�Ĭ��������ϳ�һ�������ķֲ�ʽ���������������һ��hadoop��Ⱥ����
һ��MapReduce���д����Ļ�������
��������Ҫ˵������Hadoop2.0֮ǰ��Hadoop2.0֮������𣺡�
���� 2.0֮ǰֻ��MapReduce�����п�ܣ���ô��������ֻ�����ֽڵ㣬һ����master��һ����worker��master������Դ��������������ȣ�workerֻ����������������
���� ������2.0֮�������YARN��Ⱥ��Yarn��Ⱥ�����ڵ�е�����Դ���ȣ�Yarn��Ⱥ�Ĵӽڵ��л�ѡ��һ���ڵ㣨�����redourcemanager������
���� ����������2.0֮ǰ��master�Ĺ�����������Ӧ�ó���ĵ�����
���� ��Դ���ȣ� ������������Ҫ��cpu���ڴ���Դ���Լ��洢��������Ҫ��Ӳ����Դ����resourcemanagerȥ�������
����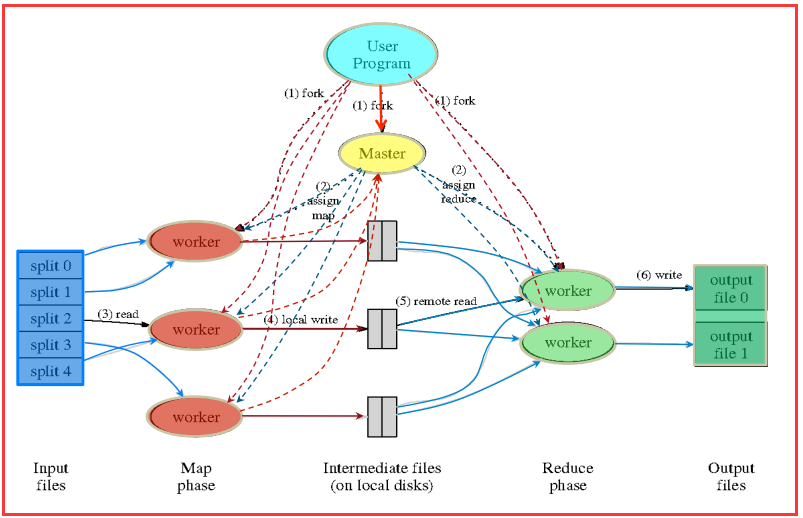
����һ�ж��Ǵ����Ϸ���userprogram��ʼ�ģ�userprogram������MapReduce�⣬ʵ�����������Map������Reduce������
����ͼ��ִ�е�˳�������ֱ���ˡ�
����1��MapReduce���Ȱ�user program�������ļ�����ΪM�ݣ�MΪ�û����壩����ͼ����ʾ�ֳ���split0~4��Ȼ��ʹ��fork���û����̿�������Ⱥ�����������ϡ�
����2��user program�ĸ�������һ����Ϊmaster�������Ϊworker��master�Ǹ�����ȵģ�Ϊ����worker������ҵ��Map��ҵ����Reduce��ҵ����worker������Ҳ��
���������������û�ָ���ġ�
����3����������Map��ҵ��worker����ʼ��ȡ��Ӧ��Ƭ���������ݣ�Map��ҵ��������M�����ģ���splitһһ��Ӧ��Map��ҵ�����������г�ȡ����ֵ�ԣ�ÿһ����ֵ��
������������Ϊ�������ݸ�map������map�����������м��ֵ�Ա��������ڴ��С�
����4��������м��ֵ�Իᱻ����д�뱾�ش��̣����ұ���ΪR������R�Ĵ�С�����û�����ģ�����ÿ�������Ӧһ��Reduce��ҵ����Щ�м��ֵ�Ե�λ�ûᱻͨ��
����������master��master������Ϣת����Reduce worker��
����5��master֪ͨ������Reduce��ҵ��worker������ķ�����ʲôλ�ã��϶���ֹһ���ط���ÿ��Map��ҵ�������м��ֵ�Զ�����ӳ�䵽����R����ͬ����������
��������Reduce worker��������������м��ֵ�Զ����������ȶ����ǽ�������ʹ����ͬ���ļ�ֵ�Ծۼ���һ����Ϊ��ͬ�ļ����ܻ�ӳ�䵽ͬһ������Ҳ����
��������ͬһ��Reduce��ҵ��˭�÷������أ������������DZ���ġ�
����6��reduce worker�����������м��ֵ�ԣ�����ÿ��Ψһ�ļ����������������ֵ���ݸ�reduce������reduce������������������ӵ��������������ļ��С�
����7�������е�Map��Reduce��ҵ������ˣ�master���������user program��MapReduce�������÷���user program�Ĵ��롣
����8������ִ����Ϻ�MapReduce���������R������������ļ��У��ֱ��Ӧһ��Reduce��ҵ�����û�ͨ��������Ҫ�ϲ���R���ļ������ǽ�����Ϊ���뽻����һ
����������MapReduce�����������������У��������������Եײ�ֲ�ʽ�ļ�ϵͳ��GFS���ģ��м������Ƿ��ڱ����ļ�ϵͳ�ģ��������������д��ײ�ֲ�ʽ�ļ�
��������ϵͳ��GFFS���ġ���������Ҫע��Map/Reduce��ҵ��map/reduce����������Map��ҵ����һ���������ݵķ�Ƭ��������Ҫ���ö��map����������ÿ������
����������ֵ�ԣ�Reduce��ҵ����һ���������м��ֵ�ԣ��ڼ�Ҫ��ÿ����ͬ�ļ�����һ��reduce������Reduce��ҵ����Ҳ��Ӧһ������ļ���
��������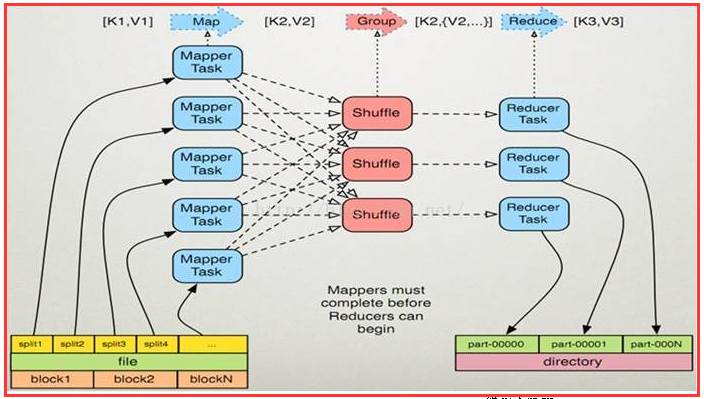
����MapRrduce�������������
����Map/Reduce�����ת��<key, value>��ֵ���ϣ�Ҳ����˵����ܰ���ҵ�����뿴Ϊ��һ��<key, value>��ֵ����ͬ��Ҳ����һ�� <key, value>��ֵ����Ϊ��ҵ��������������
��������ֵ�Ե����Ϳ��ܲ�ͬ��
���������Ҫ��key��value����(classes)�������л���������ˣ���Щ����Ҫʵ��Writable�ӿ������⣬Ϊ�˷�����ִ�����������key�����ʵ�� WritableComparable�ӿ���
����ע�⣺��������������л�������Ҫ�����þ����־û��洢�������������紫��
����һ��Map/Reduce��ҵ��������������������ʾ��
����(input) <k1, v1> -> map -> <k2, v2>-> combine -> <k2, v2> -> reduce -> <k3, v3> (output)��
������ʵ��ǰ�潲��Hadoop IO��ʱ���Ѿ�֪���˽���Writale�ӿڣ�����
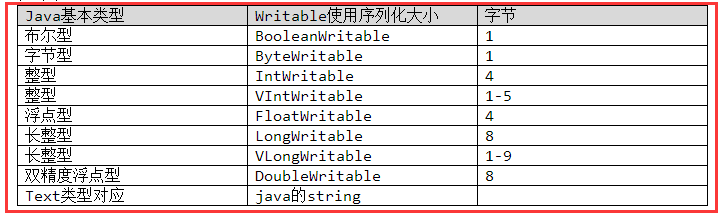
��������Writable�ӿ���һ��ʵ�������л�Э������л�����
����������Hadoop�ж���һ���ṹ������Ҫʵ��Writable�ӿڣ�ʹ�øýṹ������������л�Ϊ�ֽ������ֽ���Ҳ���Է����л�Ϊ�ṹ������
��������
����MapReduceʵ�ʴ�������
����mapreduce ��ʵ�������㷨��һ���֣���ν�����㷨���ǡ����Ƿֶ���֮ �����������ֽ�Ϊ��ͬ���͵������⣨��þ�����ͬ�Ĺ�ģ�����������������⣬Ȼ��ϲ��ɴ�����Ľ���
����mapreduce�������η���һ�֣���������з�Ƭ��Ȼ����ͬ��task���д�����Ȼ��ϲ������յĽ���
����mapreduceʵ�ʵĴ������̿�������ΪInput->Map->Sort->Combine->Partition->Reduce->Output��
����1��Input��
��������������һ���ĸ�ʽ���ݸ�Mapper����TextInputFormat��DBInputFormat��SequenceFileFormat�ȿ���ʹ�ã���Job.setInputFormat�������ã�Ҳ�����Զ����Ƭ������
����2��map��
���������������(key��value)���д�������map(k1,v1)->list(k2,v2),ʹ��Job.setMapperClass�������á�
����3��Sort��
������������Mapper�������������ʹ��Job.setOutputKeyComparatorClass�������ã�Ȼ�������������
����4��Combine��
������������ζ���Sort֮������ͬkey�Ľ�����кϲ���ʹ��Job.setCombinerClass�������ã�Ҳ�����Զ���Combine Class�ࡣ
����5��Partition��
����������Mapper���м�������key�ķ�Χ����ΪR�ݣ�Reduce��ҵ�ĸ�������Ĭ��ʹ��HashPartioner��key.hashCode()&Integer.MAX_VALUE%numPartitions����Ҳ�����Զ��廮���ĺ�����
��������ʹ��Job.setPartitionClass���á�
����6��Reduce��
������������Mapper�εĽ�����н�һ��������Job.setReducerClass���������Զ����Reduce�ࡣ
����7��Output��
��������Reducer������ݵĸ�ʽ��
�ġ�һ��job����������
����һ��mapreduce��ҵ��ִ�������ǣ���ҵ�ύ->��ҵ��ʼ��->�������->����ִ��->��������ִ�н��Ⱥ�״̬->��ҵ�����
����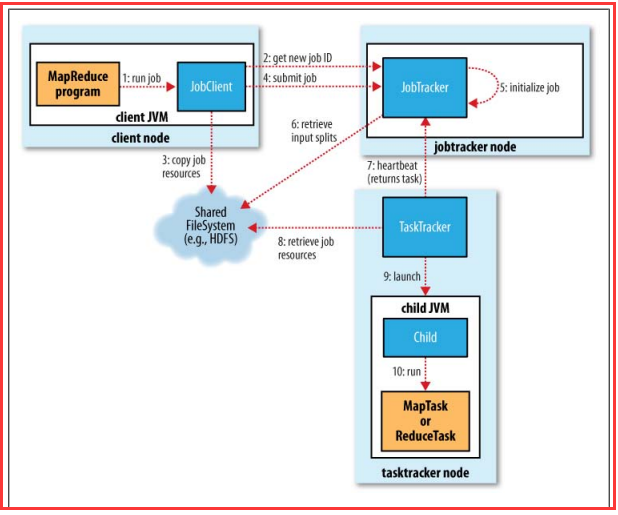
����һ��������mapreduce��ҵ���̣�����4��������ʵ�壺
���������ͻ��ˣ�client����дmapreduce����������ҵ���ύ��ҵ��
��������JobTracker��Э�������ҵ�����У�������ҵ����ʼ����ҵ����TaskTracker����ͨ����
��������TaskTracker������������ҵ��������JobTracker����ͨ����
��������HDFS���ֲ�ʽ�ļ�ϵͳ��������ҵ�����ݺͽ����
4.1���ύ��ҵ
����JobClientʹ��runjob��������һ��JobClientʵ����Ȼ�����submitJob()����������ҵ���ύ���ύ��ҵ�ľ���������£�
��������1��ͨ������JobTracker�����getNewJobId()������JobTracker�����һ����ҵID��
��������2�������ҵ�����·����������·�����ڣ���ҵ�����ᱻ�ύ��������һ����ҵ���н������
��������3��������ҵ�������Ƭ����������㣬��������·�������ڣ���ҵ�������ύ�����ظ�mapreduce����
��������4����������ҵ������Դ(��ҵjar�ļ��������ļ��ͼ���õ��ķ�Ƭ)���Ƶ�HDFS�ϡ�
��������5����֪JobTracker��ҵ��ִ�У�ʹ��JobTracker�����submitJob()�����������ύ��ҵ����
4.2����ҵ��ʼ��
������JobTracker�յ�Job�ύ�������Job������һ���ڲ����У�����Job Scheduler����ҵ����������������ʼ������ʼ���漰������һ����װ����tasks��job����
���������ֶ�task��״̬�ͽ��ȵĸ���(step 5)��������Ҫ���е�һϵ��task�����Job Scheduler���ȿ�ʼ���ļ�ϵͳ�л�ȡ��JobClient�����input splits(step 6)��Ȼ��
������Ϊÿ��split����map task��
4.3������ķ���
����TaskTracker��JobTracker֮���ͨ�ź����������ͨ������������ɵġ�TaskTracker��Ϊһ��������JVM����ִ��һ����ѭ������Ҫʵ��ÿ��һ��ʱ����JobTracker
������������������JobTracker��TaskTracker�Ƿ���Ƿ���ִ���µ���������д�������������ͻ�ΪTaskTracker����һ������
4.4�������ִ��
����TaskTracker���뵽�µ�����֮��Ҫ�ڱ��������ˡ����ȣ��ǽ����ػ�����������������������ݡ�������Ϣ������ȣ�������HDFS���Ƶ����ء�����localizeJob()��ɵġ�
��������ʹ��Streaming��Pipes����Map����Reduce���������Java���key/value���ݸ��ⲿ���̣�Ȼ��ͨ���û��Զ����Map����Reduce���д�����Ȼ���key/value���ص�java�С�
�������оͺ�����TaskTracker���ӽ����ڴ���Map��Reduce����һ����
4.5�����������ִ�н��Ⱥ�״̬
�������Ⱥ�״̬��ͨ��heartbeat(��������)�����º�ά���ġ�����Map Task�����Ⱦ����Ѵ������ݺ������������ݵı���������Reduce Task��������ʵ縴�ӣ�����3���֣�
���������м����ļ�������reduce���ã�ÿ����ռ1/3��
4.6���������
������Job��ɺ�JobTracker����һ��Job Complete��֪ͨ��������ǰ��Job״̬����Ϊsuccessful��ͬʱJobClientҲ����ѭ��֪�ύ��Job�Ѿ���ɣ�����Ϣ��ʾ���û���
�������JobTracker�������ͻ��ո�Job�������Դ����֪ͨTaskTracker������ͬ�IJ���������ɾ���м����ļ���
�塢MapReduce��ܽṹ���������л���
5.1���ṹ
����һ��������mapreduce�������ֲ�ʽ����ʱ������ʵ��������
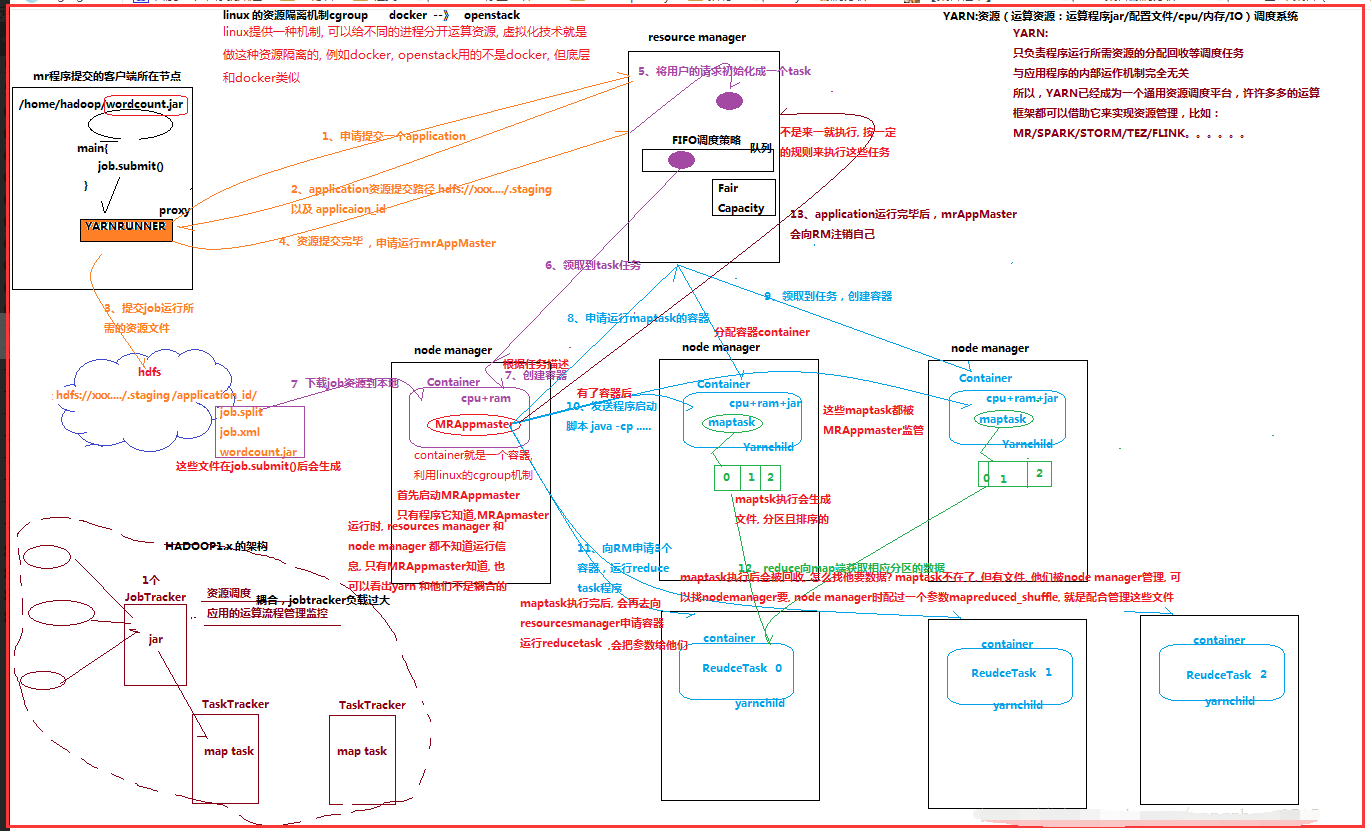
��������MRAppMaster��������������Ĺ��̵��ȼ�״̬Э����Hadoop2.0֮��Ͳ�һ���ˣ�
��������mapTask������map�ε��������ݴ�������
��������ReduceTask������reduce�ε��������ݴ�������
5.2��MapReduce�������̽���
����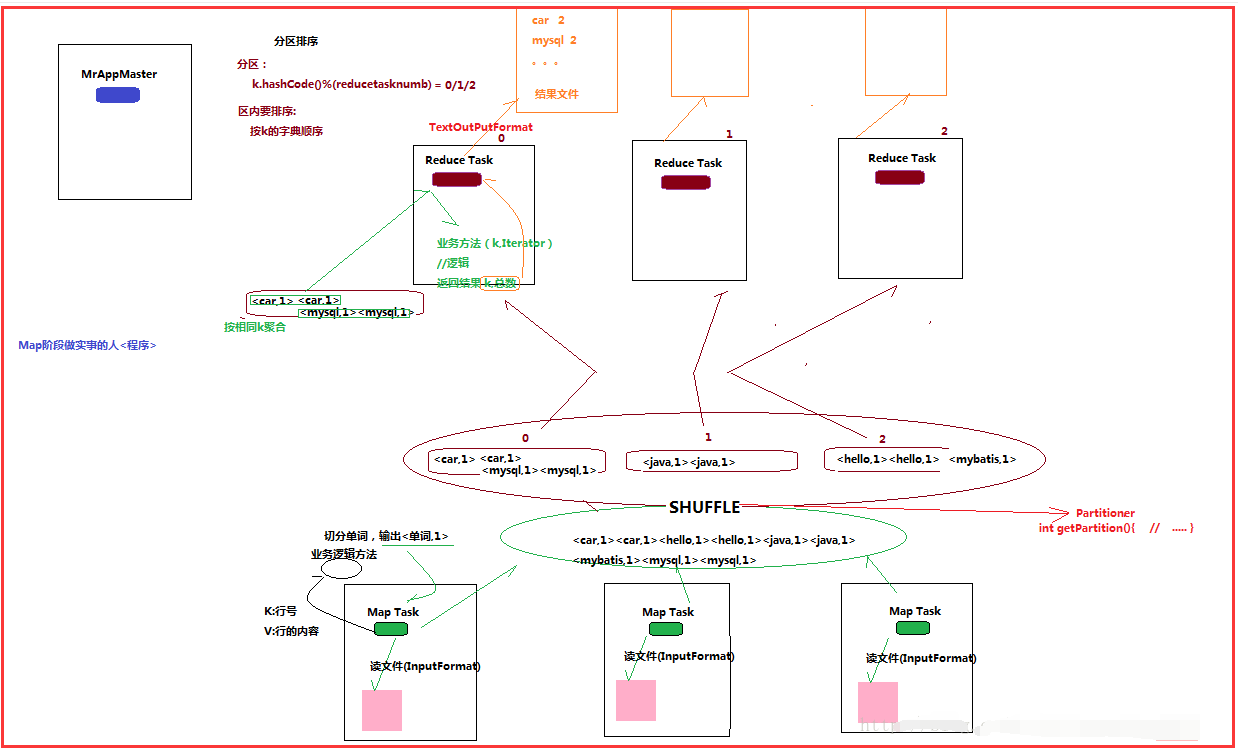
�������̷�����
����1��һ��mr����������ʱ��������������MRAppMaster��MRAppMaster��������ݱ���job��������Ϣ���������Ҫ��maptaskʵ��������Ȼ����Ⱥ�����������
����������Ӧ������maptask���̡�
����2��maptask��������֮���ݸ�����������Ƭ��Χ�������ݴ�������������Ϊ��
�����������ÿͻ�ָ����inputformat����ȡRecordReader��ȡ���ݣ��γ�����KV��
��������������KV�Դ��ݸ��ͻ������map()�������������㣬����map()���������KV���ռ�������
���������������е�KV����K�����������д�������ļ�
����3�� MRAppMaster��ص�����maptask�����������֮����ݿͻ�ָ���IJ���������Ӧ������reducetask���̣�����֪reducetask����Ҫ���������ݷ�Χ�����ݷ�����
����4��Reducetask��������֮����MRAppMaster��֪�Ĵ�������������λ�ã�������̨maptask�������ڻ����ϻ�ȡ�����ɸ�maptask�������ļ������ڱ��ؽ������¹鲢����
��������Ȼ������ͬkey��KVΪһ���飬���ÿͻ������reduce()�������������㣬���ռ���������Ľ��KV��Ȼ����ÿͻ�ָ����outputformat���������������ⲿ�洢��
5.3��MapTask���жȾ�������
����maptask�IJ��ж�����map�ε������������ȣ�����Ӱ�쵽����job�Ĵ����ٶ�
������ô��mapTask����ʵ���Ƿ�Խ��Խ���أ��䲢�ж�������ξ����أ�
5.3.1��mapTask���жȵľ�������
����һ��job��map�β��ж��ɿͻ������ύjobʱ�������ͻ��˶�map�β��жȵĹ滮�Ļ�����Ϊ����������������������ִ������Ƭ��������һ���ض���Ƭ��С�������������ݻ��ֳ����ϵĶ��split����Ȼ��ÿһ��split����һ��mapTask����ʵ������
����������������γɵ���Ƭ�滮�����ļ�����FileInputFormatʵ�����getSplits()������������������ͼ��
����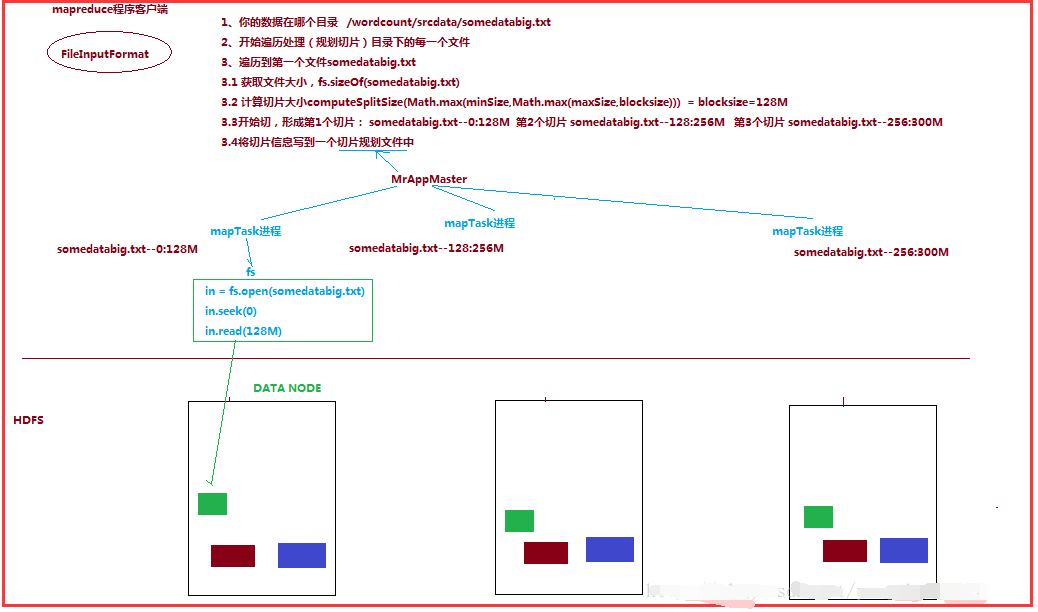
5.3.2��FileInputFormat��Ƭ����
����1��FileInputFormat��Ƭ������Ƭ������InputFormat���е�getSplit()����
����2��FileInputFormat��Ĭ�ϵ���Ƭ���ƣ�
���������ذ����ļ������ݳ��Ƚ�����Ƭ
����������Ƭ��С��Ĭ�ϵ���block��С
������ ��Ƭʱ���������ݼ����壬����������ÿһ���ļ�������Ƭ
������������������������ļ���
��������file1.txt 320M
��������file2.txt 10M
��������FileInputFormat����Ƭ����������γɵ���Ƭ��Ϣ���£�
��������file1.txt.split1�C 0~128
��������file1.txt.split2�C 128~256
��������file1.txt.split3�C 256~320
��������file2.txt.split1�C 0~10M
����3��FileInputFormat����Ƭ�Ĵ�С�IJ�������
��������ͨ������Դ�룬��FileInputFormat�У�������Ƭ��С������Math.max(minSize, Math.min(maxSize, blockSize)); ��Ƭ��Ҫ���⼸��ֵ���������
��������minsize��Ĭ��ֵ��1
�������������� mapreduce.input.fileinputformat.split.minsize
��������maxsize��Ĭ��ֵ��Long.MAXValue
��������������mapreduce.input.fileinputformat.split.maxsize
��������blocksize
������ˣ�Ĭ������£���Ƭ��С=blocksize
����maxsize����Ƭ���ֵ����
��������������ñ�blocksizeС���������Ƭ��С�����Ҿ͵������õ����������ֵ
����minsize ����Ƭ��Сֵ����
�����������ı�blockSize�����������Ƭ��ñ�blocksize����
��
����ѡ������Ӱ�����أ�
������������ڵ��Ӳ������
��������������������ͣ�CPU�ܼ��ͻ���IO�ܼ���
�����������������������
5.3.3��ReduceTask���жȵľ���
����reducetask�IJ��ж�ͬ��Ӱ������job��ִ�в����Ⱥ�ִ��Ч�ʣ�����maptask�IJ���������Ƭ��������ͬ��Reducetask�����ľ����ǿ���ֱ���ֶ����ã�
����//Ĭ��ֵ��1���ֶ�����Ϊ4
����job.setNumReduceTasks(4);
����������ݷֲ������ȣ����п�����reduce�β���������б
����ע�⣺ reducetask�����������������ã���Ҫ����ҵ����������Щ����£���Ҫ����ȫ�ֻ��ܽ������ֻ����1��reducetask
����������Ҫ����̫���reduce task���Դ����job��˵�����rduce�ĸ������ͼ�Ⱥ�е�reduce��ƽ�����߱ȼ�Ⱥ�� reduce slotsС���������С��Ⱥ���ԣ�������Ҫ��
5.4��mapreduce��shuffle����
����1������
��������mapreduce�У�map�δ�����������δ��ݸ�reduce�Σ���mapreduce�������ؼ���һ�����̣�������̾ͽ�shuffle��
��������shuffle: ϴ�ơ����ơ��������Ļ��ƣ����ݷ����������棩��
��������������˵��������maptask����Ĵ���������ݣ��ַ���reducetask�����ڷַ��Ĺ����У������ݰ�key�����˷���������
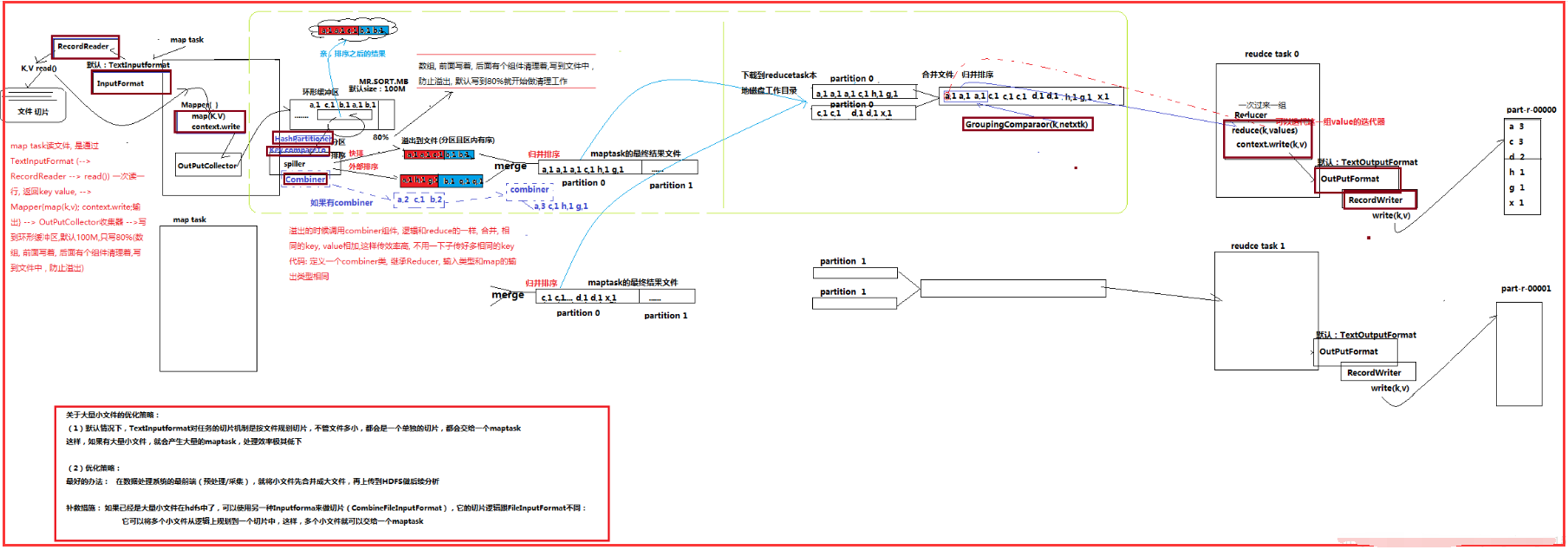
������������partition��ȷ���ĸ����ݽ����ĸ�reduce��
��������Sort����key����
��������Combiner���оֲ�value�ĺϲ�
����2����ϸ���̡���
��������1�� maptask�ռ����ǵ�map()���������kv�ԣ��ŵ��ڴ滺������
��������2�� ���ڴ滺��������������ش����ļ������ܻ��������ļ�
��������3�� �������ļ��ᱻ�ϲ��ɴ������ļ�
��������4�� ����������У����ϲ��Ĺ����У���Ҫ����partitoner���з�������key��������
��������5�� reducetask�����Լ��ķ����ţ�ȥ����maptask������ȡ��Ӧ�Ľ����������
��������6�� reducetask��ȡ��ͬһ�����������Բ�ͬmaptask�Ľ���ļ���reducetask�Ὣ��Щ�ļ��ٽ��кϲ����鲢����
��������7�� �ϲ��ɴ��ļ���shuffle�Ĺ���Ҳ�ͽ����ˣ��������reducetask����������̣����ļ���ȡ��һ��һ���ļ�ֵ��group�������û��Զ����reduce()������
����Shuffle�еĻ�������С��Ӱ�쵽mapreduce�����ִ��Ч�ʣ�ԭ����˵��������Խ����io�Ĵ���Խ�٣�ִ���ٶȾ�Խ��
�����������Ĵ�С����ͨ����������, ������io.sort.mb Ĭ��100M