下面来讲一个hadoop的实例,统计文件words.txt中单词的个数。
一、环境需求:
1、虚拟机itcast01
2、在虚拟机itcast安装eclipse(注意是linux版本的,安装过程参考前面的博客)
二、过程
1、在itcast01虚拟机上创建文件words.txt文件,并写入一定数据,保存。
2、start-all.sh开启Hadoop服务,hadoop fs -put words.txt hdfs://itcast01:9000/把文件words.txt上传到hdfs服务器的更目录下。
3、打开eclipse,创建java工程。导入hadoop包和相关配置文件。
进入/hadoop安装目录下/share/hadoop/,(1)、把hdfs文件夹下的jar包和hdfs/bin目录下的jar包导入工程)。(2)、把mapreduce文件夹下的jar包和mapreduce/bin目录下的jar包导入工程。(3)、把yarn文件夹下的jar包和yarn/bin目录下的jar包导入工程。(4)、把common文件夹下的jar包和common/bin下的jar包导入工程。(5)、把hadoop安装目录下/etc/hadoop中core-site.xml和hdfs-site.xml文件配置到java工程的src目录下。
4、编写代码程序
建一个WcMapper类
package cn.itcast.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMapper extends Mapper<LongWritable, Text, Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String [] words=line.split(" ");
for(String word:words)
{
context.write(new Text(word),new LongWritable(1));
}
}
}
建一个WcReducer类
package cn.itcast.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable number : values) {
count += number.get();
}
context.write(new Text(key), new LongWritable(count));
}
}
package cn.itcast.hadoop.mr
import java.io.IOException
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
public class WordCountRunner {
public static void main(String [] args) throws IOException, ClassNotFoundException, InterruptedException
{
Job job=Job.getInstance(new Configuration())
//组建Job类,提交给mapreduce
job.setJarByClass(WordCountRunner.class)
job.setMapperClass(WcMapper.class)
job.setReducerClass(WcReducer.class)
//设置输入输出类型
job.setMapOutputKeyClass(Text.class)
job.setMapOutputValueClass(LongWritable.class)
job.setOutputKeyClass(Text.class)
job.setOutputValueClass(LongWritable.class)
//构建输入输出的文件
FileInputFormat.setInputPaths(job,"hdfs://itcast01:9000/words.txt")
FileOutputFormat.setOutputPath(job,new Path("hdfs://itcast01:9000/wordcount821"))
//提交job到mapreduce处理
job.waitForCompletion(true)
}
}
5、将java文件打包成jar文件wordcountRunner.jar。
6、hadoop jar wordcountRunner.jar运行该文件。
7 、输入hadoop fs -ls /发现该目录下生成一个文件wordcount821.txt。
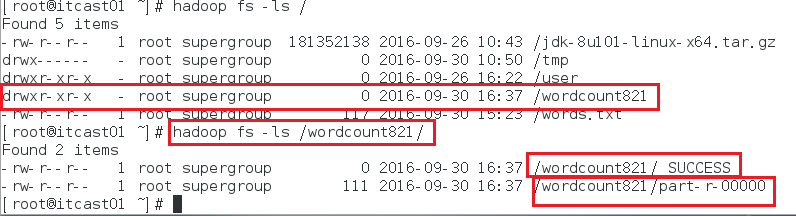
8、再输入hadoop fs -ls /wordcount821/发现出现success,表示java程序运行成功。
9、输入hadoop fs -cat /wordcount821/part-r-00000查看统计结果。