|
一、概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的,在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。对于二次排序的实现,网络上已经有很多人分享过了,但是对二次排序的实现原理及整个MapReduce框架的处理流程的分析还是有非常大的出入,而且部分分析是没有经过验证的。本文将通过一个实际的MapReduce二次排序的例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和Map、Reduce端的日志来验证描述的处理流程的正确性。
二、需求描述 1.输入数据 - sort11
- sort23
- sort288
- sort254
- sort12
- sort622
- sort6888
- sort658
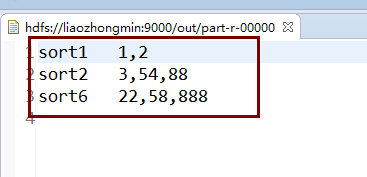
2.目标输出 - sort11,2
- sort23,54,88
- sort622,58,888
1.首先,在思考解决问题思路时,我们应该先深刻的理解MapReduce处理数据的整个流程,这是最基础的,不然的话是不可能找到解决问题的思路的。我描述一下MapReduce处理数据的大概流程:首先,MapReduce框架通过getSplits()方法实现对原始文件的切片之后,每一个切片对应着一个MapTask,InputSplit输入到map()函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过Shuffle操作将数据传输到reduce Task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照key值进行分组,然后每处理完一个分组之后就会去调用一次reduce()函数,最终输出结果。大概流程 我画了一下,如下图: 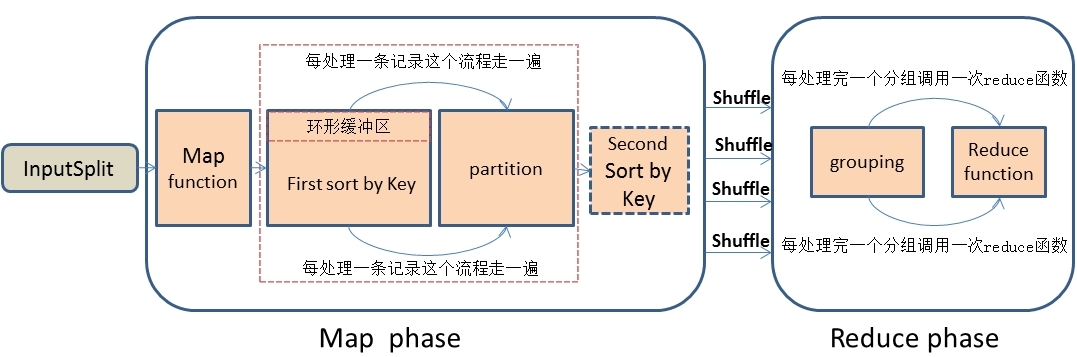
2.具体解决思路 (1):Map端处理 根据上面的需求,我们有一个非常明确的目标就是要对第一列相同的记录,并且对合并后的数字进行排序。我们都知道MapReduce框架不管是默认排序或者是自定义排序都只是对key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的key值和其对应的数据组合成一个新的key值,然后新的key值对应的value还是原始数据中的valu。那么我们就可以将原始数据的map输出变成类似下面的数据结构: - {[sort1,1],1}
- {[sort2,3],3}
- {[sort2,88],88}
- {[sort2,54],54}
- {[sort1,2],2}
- {[sort6,22],22}
- {[sort6,888],888}
- {[sort6,58],58}
- Partition1:{[sort1,1],1}、{[sort1,2],2}
- Partition2:{[sort2,3],3}、{[sort2,88],88}、{[sort2,54],54}
- Partition3:{[sort6,22],22}、{[sort6,888],888}、{[sort6,58],58}
- {[sort1,1],1}
- {[sort1,2],2}
- {[sort2,3],3}
- {[sort2,54],54}
- {[sort2,88],88}
- {[sort6,22],22}
- {[sort6,58],58}
- {[sort6,888],888}
(2).Reduce端处理 经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端按照组合键的第一个字段进行分组,并且每处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理和输出。最终各个分组的数据结果变成类似下面的数据结构: - sort11,2
- sort23,54,88
- sort622,58,888
四、具体实现 1.自定义组合键 - publicclassCombinationKeyimplementsWritableComparable<CombinationKey>{
- privateTextfirstKey;
- privateIntWritablesecondKey;
- publicCombinationKey(){
- this.firstKey=newText();
- this.secondKey=newIntWritable();
- }
- publicCombinationKey(TextfirstKey,IntWritablesecondKey){
- this.firstKey=firstKey;
- this.secondKey=secondKey;
- }
- publicTextgetFirstKey(){
- returnfirstKey;
- }
- publicvoidsetFirstKey(TextfirstKey){
- this.firstKey=firstKey;
- }
- publicIntWritablegetSecondKey(){
- returnsecondKey;
- }
- publicvoidsetSecondKey(IntWritablesecondKey){
- this.secondKey=secondKey;
- }
- publicvoidwrite(DataOutputout)throwsIOException{
- this.firstKey.write(out);
- this.secondKey.write(out);
- }
- publicvoidreadFields(DataInputin)throwsIOException{
- this.firstKey.readFields(in);
- this.secondKey.readFields(in);
- }
- publicintcompareTo(CombinationKeycombinationKey){
- System.out.println("------------------------CombineKeyflag-------------------");
- returnthis.firstKey.compareTo(combinationKey.getFirstKey());
- }
- @Override
- publicinthashCode(){
- finalintprime=31;
- intresult=1;
- result=prime*result+((firstKey==null)0:firstKey.hashCode());
- returnresult;
- }
- @Override
- publicbooleanequals(Objectobj){
- if(this==obj)
- returntrue;
- if(obj==null)
- returnfalse;
- if(getClass()!=obj.getClass())
- returnfalse;
- CombinationKeyother=(CombinationKey)obj;
- if(firstKey==null){
- if(other.firstKey!=null)
- returnfalse;
- }elseif(!firstKey.equals(other.firstKey))
- returnfalse;
- returntrue;
- }
- }
2.自定义分区器 - publicclassDefinedPartitionextendsPartitioner<CombinationKey,IntWritable>{
- publicintgetPartition(CombinationKeykey,IntWritableva lue,intnumPartitions){
- System.out.println("---------------------进入自定义分区---------------------");
- System.out.println("---------------------结束自定义分区---------------------");
- return(key.getFirstKey().hashCode()&Integer.MAX_VALUE)%numPartitions;
- }
- }
- publicclassDefinedComparatorextendsWritableComparator{
- protectedDefinedComparator(){
- super(CombinationKey.class,true);
- }
- publicintcompare(WritableComparablea,WritableComparableb){
- System.out.println("------------------进入二次排序-------------------");
- CombinationKeyc1=(CombinationKey)a;
- CombinationKeyc2=(CombinationKey)b;
- intminus=c1.getFirstKey().compareTo(c2.getFirstKey());
- if(minus!=0){
- System.out.println("------------------结束二次排序-------------------");
- returnminus;
- }else{
- System.out.println("------------------结束二次排序-------------------");
- returnc1.getSecondKey().get()-c2.getSecondKey().get();
- }
- }
- }
- publicclassDefinedGroupSortextendsWritableComparator{
- protectedDefinedGroupSort(){
- super(CombinationKey.class,true);
- }
- @Override
- publicintcompare(WritableComparablea,WritableComparableb){
- System.out.println("---------------------进入自定义分组---------------------");
- CombinationKeycombinationKey1=(CombinationKey)a;
- CombinationKeycombinationKey2=(CombinationKey)b;
- System.out.println("---------------------分组结果:"+combinationKey1.getFirstKey().compareTo(combinationKey2.getFirstKey()));
- System.out.println("---------------------结束自定义分组---------------------");
- returncombinationKey1.getFirstKey().compareTo(combinationKey2.getFirstKey());
- }
- }
- publicclassSecondSortMapReduce{
- privatestaticfinalStringINPUT_PATH="hdfs://liaozhongmin:9000/sort_data";
- privatestaticfinalStringOUT_PATH="hdfs://liaozhongmin:9000/out";
- publicstaticvoidmain(String[]args){
- try{
- Configurationconf=newConfiguration();
- conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,"\t");
- FileSystemfileSystem=FileSystem.get(newURI(OUT_PATH),conf);
- if(fileSystem.exists(newPath(OUT_PATH))){
- fileSystem.delete(newPath(OUT_PATH),true);
- }
- Jobjob=newJob(conf,SecondSortMapReduce.class.getName());
- FileInputFormat.setInputPaths(job,INPUT_PATH);
- job.setInputFormatClass(KeyValueTextInputFormat.class);
- job.setMapperClass(SecondSortMapper.class);
- job.setMapOutputKeyClass(CombinationKey.class);
- job.setMapOutputValueClass(IntWritable.class);
- job.setPartitionerClass(DefinedPartition.class);
- job.setNumReduceTasks(1);
- job.setGroupingComparatorClass(DefinedGroupSort.class);
- job.setSortComparatorClass(DefinedComparator.class);
- job.setReducerClass(SecondSortReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- FileOutputFormat.setOutputPath(job,newPath(OUT_PATH));
- job.setOutputFormatClass(TextOutputFormat.class);
- System.exit(job.waitForCompletion(true)0:1);
- }catch(Exceptione){
- e.printStackTrace();
- }
- }
- publicstaticclassSecondSortMapperextendsMapper<Text,Text,CombinationKey,IntWritable>{
- privateCombinationKeycombinationKey=newCombinationKey();
- TextsortName=newText();
- IntWritablescore=newIntWritable();
- String[]splits=null;
- protectedvoidmap(Textkey,Textvalue,Mapper<Text,Text,CombinationKey,IntWritable>.Contextcontext)throwsIOException,InterruptedException{
- System.out.println("---------------------进入map()函数---------------------");
- if(key==null||value==null||key.toString().equals("")){
- return;
- }
- sortName.set(key.toString());
- score.set(Integer.parseInt(value.toString()));
- combinationKey.setFirstKey(sortName);
- combinationKey.setSecondKey(score);
- context.write(combinationKey,score);
- System.out.println("---------------------结束map()函数---------------------");
- }
- }
- publicstaticclassSecondSortReducerextendsReducer<CombinationKey,IntWritable,Text,Text>{
- StringBuffersb=newStringBuffer();
- Textscore=newText();
- protectedvoidreduce(CombinationKeykey,Iterable<IntWritable>values,Reducer<CombinationKey,IntWritable,Text,Text>.Contextcontext)
- throwsIOException,InterruptedException{
- sb.delete(0,sb.length());
- for(IntWritableva l:values){
- sb.append(val.get()+",");
- }
- if(sb.length()>0){
- sb.deleteCharAt(sb.length()-1);
- }
- score.set(sb.toString());
- context.write(key.getFirstKey(),score);
- System.out.println("---------------------进入reduce()函数---------------------");
- System.out.println("---------------------{["+key.getFirstKey()+","+key.getSecondKey()+"],["+score+"]}");
- System.out.println("---------------------结束reduce()函数---------------------");
- }
- }
- }
五、处理流程 看到前面的代码,都知道我在各个组件上已经设置好了相应的标志,用于追踪整个MapReduce处理二次排序的处理流程。现在让我们分别看看Map端和Reduce端的日志情况。 (1)Map端日志分析 - 15/01/1915:32:29INFOinput.FileInputFormat:Totalinputpathstoprocess:1
- 15/01/1915:32:29WARNsnappy.LoadSnappy:Snappynativelibrarynotloaded
- 15/01/1915:32:30INFOmapred.JobClient:Runningjob:job_local_0001
- 15/01/1915:32:30INFOmapred.Task:UsingResourceCalculatorPlugin:null
- 15/01/1915:32:30INFOmapred.MapTask:io.sort.mb=100
- 15/01/1915:32:30INFOmapred.MapTask:databuffer=79691776/99614720
- 15/01/1915:32:30INFOmapred.MapTask:recordbuffer=262144/327680
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- ---------------------进入map()函数---------------------
- ---------------------进入自定义分区---------------------
- ---------------------结束自定义分区---------------------
- ---------------------结束map()函数---------------------
- 15/01/1915:32:30INFOmapred.MapTask:Startingflushofmapoutput
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- ------------------进入二次排序-------------------
- ------------------结束二次排序-------------------
- 15/01/1915:32:30INFOmapred.MapTask:Finishedspill0
- 15/01/1915:32:30INFOmapred.Task:Task:attempt_local_0001_m_000000_0isdone.Andisintheprocessofcommiting
- 15/01/1915:32:30INFOmapred.LocalJobRunner:
- 15/01/1915:32:30INFOmapred.Task:Task'attempt_local_0001_m_000000_0'done.
- 15/01/1915:32:30INFOmapred.Task:UsingResourceCalculatorPlugin:null
- 15/01/1915:32:30INFOmapred.LocalJobRunner:
(2)Reduce端日志分析 - 15/01/1915:32:30INFOmapred.Merger:Merging1sortedsegments
- 15/01/1915:32:30INFOmapred.Merger:Downtothelastmerge-pass,with1segmentsleftoftotalsize:130bytes
- 15/01/1915:32:30INFOmapred.LocalJobRunner:
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:0
- ---------------------结束自定义分组---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:-1
- ---------------------结束自定义分组---------------------
- ---------------------进入reduce()函数---------------------
- ---------------------{[sort1,2],[1,2]}
- ---------------------结束reduce()函数---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:0
- ---------------------结束自定义分组---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:0
- ---------------------结束自定义分组---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:-4
- ---------------------结束自定义分组---------------------
- ---------------------进入reduce()函数---------------------
- ---------------------{[sort2,88],[3,54,88]}
- ---------------------结束reduce()函数---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:0
- ---------------------结束自定义分组---------------------
- ---------------------进入自定义分组---------------------
- ---------------------分组结果:0
- ---------------------结束自定义分组---------------------
- ---------------------进入reduce()函数---------------------
- ---------------------{[sort6,888],[22,58,888]}
- ---------------------结束reduce()函数---------------------
- 15/01/1915:32:30INFOmapred.Task:Task:attempt_local_0001_r_000000_0isdone.Andisintheprocessofcommiting
- 15/01/1915:32:30INFOmapred.LocalJobRunner:
- 15/01/1915:32:30INFOmapred.Task:Taskattempt_local_0001_r_000000_0isallowedtocommitnow
- 15/01/1915:32:30INFOoutput.FileOutputCommitter:Savedoutputoftask'attempt_local_0001_r_000000_0'tohdfs:
- 15/01/1915:32:30INFOmapred.LocalJobRunner:reduce>reduce
- 15/01/1915:32:30INFOmapred.Task:Task'attempt_local_0001_r_000000_0'done.
- 15/01/1915:32:31INFOmapred.JobClient:map100%reduce100%
- 15/01/1915:32:31INFOmapred.JobClient:Jobcomplete:job_local_0001
- 15/01/1915:32:31INFOmapred.JobClient:Counters:19
- 15/01/1915:32:31INFOmapred.JobClient:FileOutputFormatCounters
- 15/01/1915:32:31INFOmapred.JobClient:BytesWritten=40
- 15/01/1915:32:31INFOmapred.JobClient:FileSystemCounters
- 15/01/1915:32:31INFOmapred.JobClient:FILE_BYTES_READ=446
- 15/01/1915:32:31INFOmapred.JobClient:HDFS_BYTES_READ=140
- 15/01/1915:32:31INFOmapred.JobClient:FILE_BYTES_WRITTEN=131394
- 15/01/1915:32:31INFOmapred.JobClient:HDFS_BYTES_WRITTEN=40
- 15/01/1915:32:31INFOmapred.JobClient:FileInputFormatCounters
- 15/01/1915:32:31INFOmapred.JobClient:BytesRead=70
- 15/01/1915:32:31INFOmapred.JobClient:Map-ReduceFramework
- 15/01/1915:32:31INFOmapred.JobClient:Reduceinputgroups=3
- 15/01/1915:32:31INFOmapred.JobClient:Mapoutputmaterializedbytes=134
- 15/01/1915:32:31INFOmapred.JobClient:Combineoutputrecords=0
- 15/01/1915:32:31INFOmapred.JobClient:Mapinputrecords=8
- 15/01/1915:32:31INFOmapred.JobClient:Reduceshufflebytes=0
- 15/01/1915:32:31INFOmapred.JobClient:Reduceoutputrecords=3
- 15/01/1915:32:31INFOmapred.JobClient:SpilledRecords=16
- 15/01/1915:32:31INFOmapred.JobClient:Mapoutputbytes=112
- 15/01/1915:32:31INFOmapred.JobClient:Totalcommittedheapusage(bytes)=391118848
- 15/01/1915:32:31INFOmapred.JobClient:Combineinputrecords=0
- 15/01/1915:32:31INFOmapred.JobClient:Mapoutputrecords=8
- 15/01/1915:32:31INFOmapred.JobClient:SPLIT_RAW_BYTES=99
- 15/01/1915:32:31INFOmapred.JobClient:Reduceinputrecords=8
六、总结 本文主要从MapReduce框架执行的流程,去分析了如何去实现二次排序,通过代码进行了实现,并且对整个流程进行了验证。另外,要吐槽一下,网络上有很多文章都记录了MapReudce处理二次排序问题,但是对MapReduce框架整个处理流程的描述错漏很多,而且他们最终的流程描述也没有证据可以支撑。所以,对于网络上的学习资源不能够完全依赖,要融入自己的思想,并且要重要的观点进行代码或者实践的验证。另外,今天在一个hadoop交流群上听到少部分人在讨论,有了hive我们就不用学习些MapReduce程序?对这这个问题我是这么认为:我不相信写不好MapReduce程序的程序员会写好hive语句,最起码的他们对整个执行流程是一无所知的,更不用说性能问题了,有可能连最常见的数据倾斜问题的弄不清楚。
如果文章写的有问题,欢迎指出,共同学习!
|