此处对hadoop的历史略过,有兴趣可自行百度。
hadoop主要是用于处理大数据量(PB级别)的数据,hadoop提供了一个稳定的共享存储和分析系统。存储由hdfs实现,分析由mapreduce 实现。这两个功能是hadoop的核心。
hadoop技术栈:
Pig | Chukwa | Hive | Hbase |
Mapreduce | Hdfs | Zookeeper |
core | avro |
扩展:技术栈是一项工作或者职位所需的一系列技术统称。
hadoop技术栈简单介绍:
pig:数据流语言和运行环境,用以检索非常大的数据集。pig运行在mapreduce 和hdfs的集群上。
hive:分布式数据仓库。hive管理hdfs中存储的数据,并提供基于sql的查询语言(由运行时引擎翻译成MapReduce作业)用以查询数据。
chukwa:分布式数据收集和分析系统。chukwa运行hdfs存储数据的收集器,它使用mapreduce来生成报告。
hbase:
mapreduce: 分布式数据处理模式和执行环境,运行于大型商用机集群
hdfs:分布式文件系统,运行于大型商用机集群
zookeeper:一个分布式的、高可用的协调服务。zookeeper提供分布式锁之类的基本服务用于构建分布式应用
core:一系列的分布式文件系统和通用I/O的组件和接口(序列化、javarpc和持久化数据结构)。
avro:一种提供高效、跨语言rpc的数据序列化系统,持久化数据存储
hadoop的两大功能:hdfs和mapreduce
hdfs(hadoop distributed fileSystem)文件分布式系统,
mapreduce
传统关系型数据库跟mapreduce 的区别(此处暂时不涉及理论部分,以后补充)
| 传统关系型数据库 | Mapreduce |
数据大小 | GB | PB |
访问 | 交互性和批处理 | 批处理 |
更新 | 多次读写 | 一次写入多次读取 |
结构 | 静态模式 | 动态模式 |
集成度 | 高 | 低 |
伸缩性 | 非线性 | 线性 |
更新一小部分数据,关系型数据库效率高。更新大部分数据库的时候关系型数据库的效率比mapreduce差。
MapReduce理解:
读完mapreduce部分以下是我对mapreduce的认识。
另一个概念 job、jobtracker、tasktracker
mapreduce 作业(job) 是客户端执行的单位:包括输入数据、MapReduce程序和配置信息。hadoop通过把作业分成若干个小任务(task)来工作,其中包括两种任务类型的任务:map任务和reduce任务。两种类型的节点控制着作业执行过程:jobtracker 和多个tasktracker。jobtracker是主线程,他通过调度任务在tasktracker上运行,来协调所有运行在系统上的作业。tasktracker在运行任务的同时,把进度报告传送到jobtracker,jobtracker则记录着每项任务的整体进展状况。如果其中一个失败,jobstracker则会重新调度任务到另一个tasktracker。
mapreduce内部包括两部分,一个是map函数,一个是reduce函数。
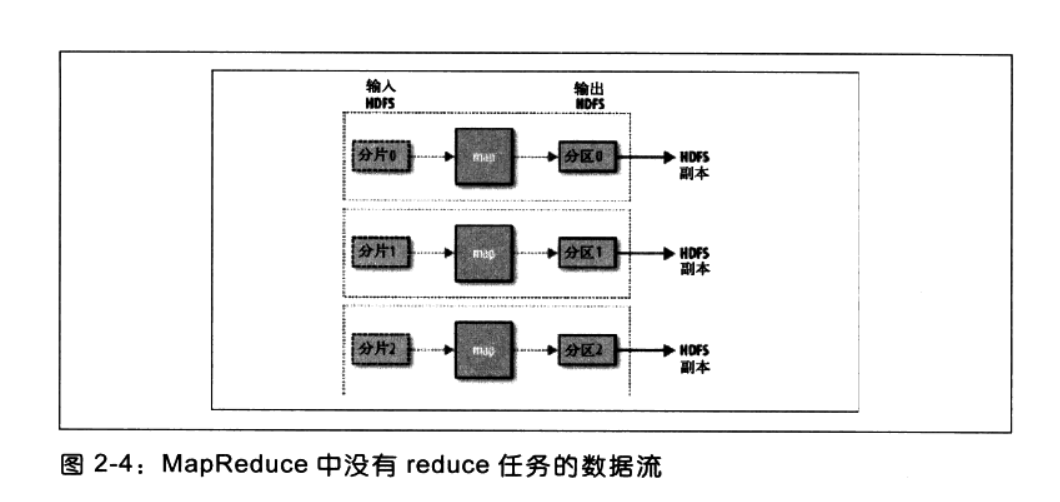
hadoop会把数据流分割成等长分片(input split),hadoop为每个分片创建一个map任务,这个小数据片如下图几种方式经过map函数处理后传递给reduce函数进行处理数据然后输出文件,在此过程中分片的大小是可以调节的,但是最好是64M,64M是HDFS默认的大小。map任务的执行节点和输入数据的存储节点是同一节点,hadoop的性能达到最佳(数据局部性优化 data locality optimization)。
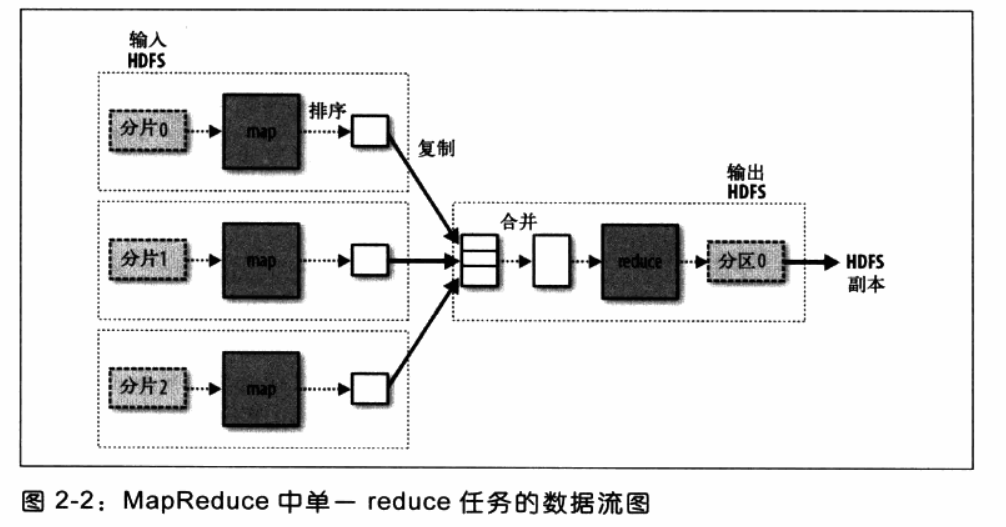
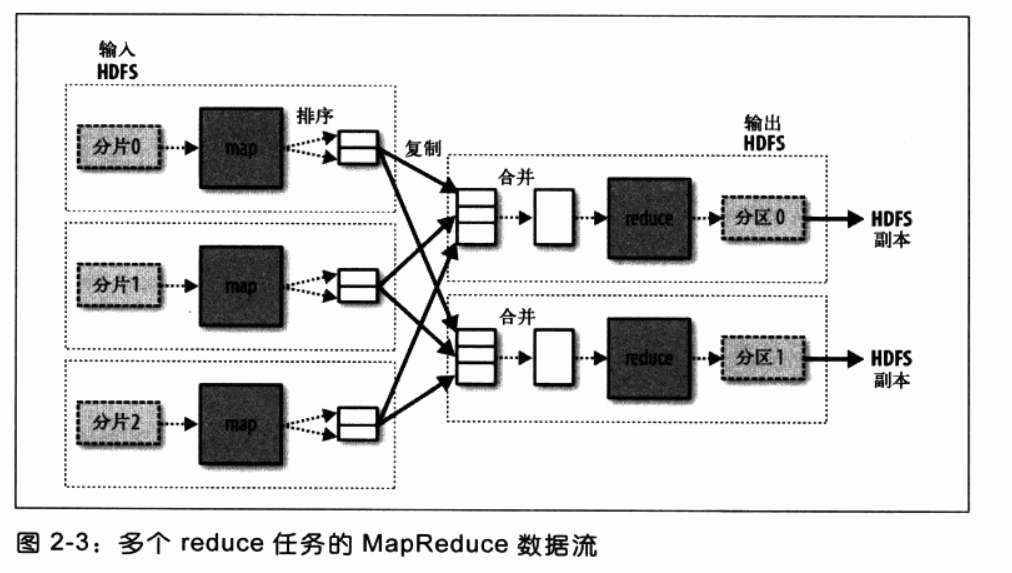
如果有多个reduce,map任务会对其输出进行分区,为每一个reduce任务创建一个分区,每个分区包含很多键(及其关联的值),这种行为成为“洗牌”。