版权声明:本文为博主原创文章,如需转载,请注明出处: https://blog.csdn.net/MASILEJFOAISEGJIAE/article/details/88542519
Hadoop概述
Hadoop是Apache基金会开发的一个开源的分布式系统基础架构,用于机器集群的数据存储和大规模数据处理。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
Hadoop 主要由以下模块组成:
- Hadoop Common:包含Hadoop模块相关的库和工具。
- Hadoop Distributed File System (HDFS) :一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
- Hadoop YARN:作业调度和集群资源管理的框架。例如一个作业要申请多少vcpu和内存,这个作业跑在哪一台机器上面。
- Hadoop MapReduce:一种编程模型,基于YARN,用于大型数据集的并行处理。
- Hadoop Ozone(Hadoop 3.2.0的新特性):一种分布式的键值对存储模式。有点类似于Amazon S3。
Hadoop 特点:
- 可靠(reliable)
- 可扩展(scalable)
- 分布式(distributed)
狭义的Hadoop
一个适合大数据分布式存储(HSFS),**分布式计算(MapReduce)**和并行处理的平台。
广义的Hadoop
指Hadoop生态系统,每一个子系统只解决某一个特定的问题领域。
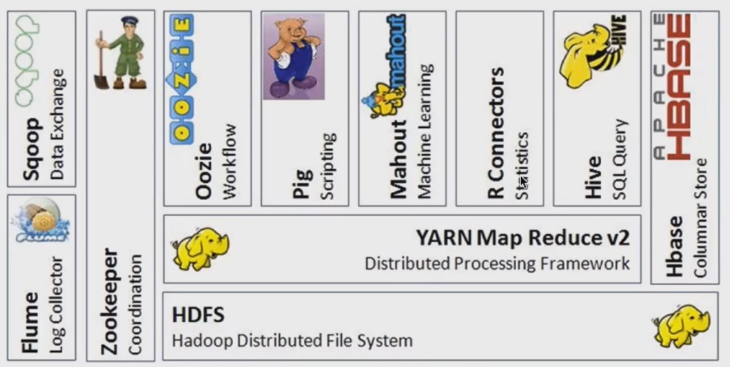
例如:
- HBase:类似于大数据的数据库
- Sqoop:关系型数据库到HDSF的交换工具
- Flume:日志收集工具
为什么公司选择Hadoop作为大数据平台的解决方案?
- 源码开源
- 社区活跃,提问很快就有人回复
- 涉及分布式存储和计算的方方面面:例如Flume进行数据采集、Spark/MR/Hive进行数据处理、HDFS/HBase进行数据存储
- 已经得到广大企业界的验证
HDFS
Hadoop实现了一个分布式文件系统Hadoop Distributed File System (HDFS),源于Google的GFS论文(发表于2003年),HDFS是GFS的克隆版。
HDFS设计目标
- HDFS实现了非常巨大的分布式文件系统。
因为单机版的文件系统的存储能力是非常有限的,例如Windows的文件系统。如果使用分布式的方式存放文件,就可以通过增加机器硬件的方式,进行水平地扩容,从而满足大数据存储的基本要求。
- HDFS可以运行在普通廉价的硬件上。
普通的PC也可以搭建分布式集群,进行分布式数据存储。
- 易扩展。
例如存储不够的时候,可以通过水平横向地增加机器的方式来扩容来提供存储量。
- 能为用户提供性能不错的文件存储服务。
由于运行在普通廉价的硬件上,很容易损坏,造成数据丢失,所以,HDFS,会用块为单元来存储文件,一般一个块的大小为128MB。举例:130MB的文件,会被拆分成两个文件:128MB和2MB。此外,这两个块会以多个副本的方式,存放在集群的不同的结点之上。这样的好处在于,一台机器挂了,其他机器还有两个副本可以使用。
HDFS的优点
- 高容错
因为把文件拆分成块,分布式地存储在不同节点上面,而且是多副本的。
- 适合批处理
存储在HDFS的数据吞吐率是非常高的。
- 适合大数据处理
无论数据多大,都能够处理。
- 可以构建廉价的机器上
节约成本。
HDFS的缺点:
- 不适合低延迟的数据访问
文件以块的方式进行存储,如果文件较大,就会有很多个块,会造成延迟。可以通过HBase(类似于大数据的数据库),可以通过主键的设计来提高查询性能。
- 不适合小文件存储
NameNode通过元数据管理文件的信息,元数据存储了文件的信息,例如文件名和块到DataNodes的映射关系。一个1GB的文件和一个1KB的文件,各自对应着NameNode上面的一个元数据,假设有很多个1KB的文件,就会产生大量的元数据,占据NameNode的内存空间,从而降低集群的性能。
NameNode和DataNodes
HDFS的架构:HDFS具有主/从架构。一个Master(NameNode)带多个Slaves(DataNode)。NameNode和DataNode一般运行在廉价的机器上,这些机器通常运行在GNU/Linux操作系统。HDFS是使用Java语言构建的,任何支持Java的机器都可以运行NameNode或DataNode软件。使用高度可移植的Java语言意味着可以在各种计算机上部署HDFS。
典型部署架构:集群中只有一台机器运行NameNode,其他机器都运行一个DataNode。这样的方式极大地简化了系统的体系结构。
NameNode
- 负责客户端请求的响应,例如,执行文件系统的操作,如打开、关闭、重命名文件和目录
- 负责元数据的管理。例如,决定不同的块到DataNodes的映射关系。
DataNode
- 负责存储文件对应的数据块
- 定期向NameNode发送心跳信息,汇报本身所有的块信息,汇报健康状况
通常群集中每个节点有一个DataNode。在内部,文件按照blocksize的大小,被拆分成多个块,分散地存储在一组DataNode中,防止机器坏掉造成的数据丢失。DataNode负责处理来自客户端的读写请求,以及块的创建和删除操作。
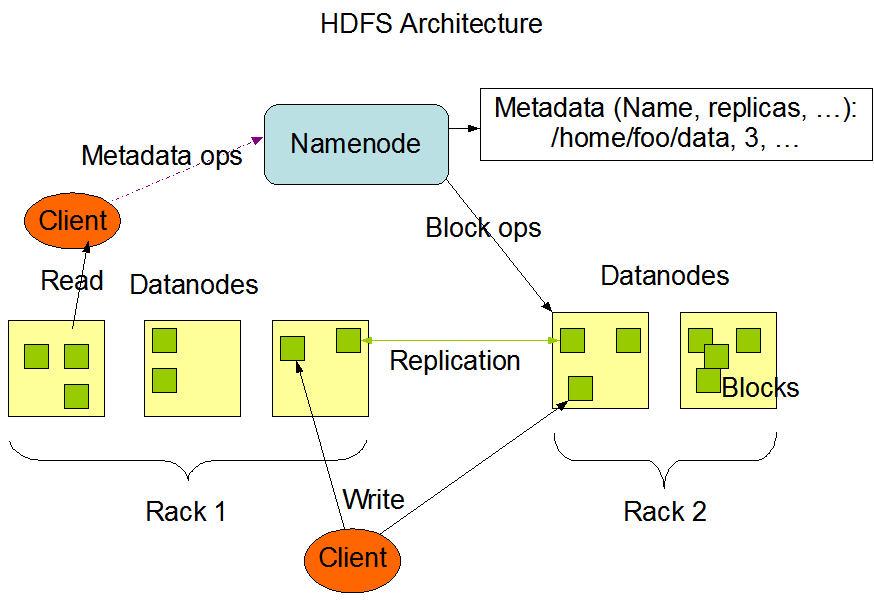
上图有有两个机架(Rack),每个机架上面有多台机器。当客户端发起读文件的请求时,先会去NameNode查文件名称、副本系数、被拆分成多少个块、每个块又存放在哪一个DataNode上面等等,这些信息通过NameNode的元数据(Metadata)进行管理。
数据副本机制
HDFS旨在可靠地在大型集群中中存储非常大的文件。它将每个文件存储为一系列块,对这些块进行数据复制,以实现容错。块大小和副本数可根据文件进行配置。
一个文件中,除最后一个块之外,所有块都具有相同的大小。
应用程序可以指定文件的副本数。副本数可以在文件创建时指定,也可以在以后更改。HDFS中的文件是一次写入的(除了追加和截断),并且在任何时候都只有一个写入器(writer),也就是说不支持并发地写入。
NameNode负责所有块的数据复制。NameNode会定期从集群的每个DataNode接收心跳(Heartbeat)和块报告(Blockreport)。收到心跳意味着DataNode正常运行。块报告包含DataNode上所有块的信息。

以上图为例,NameNode中存储内容有:文件名、副本数和块id。其中,有一个名为part-1的文件,副本数为3,块的id为2,4,5,可见这3个块各自有3个备份,存储在不同节点之中。
MapReduce
Hadoop MapReduce是Hadoop的分布式计算框架,现在已经不太常用了。现在比较常用的是Spark。
MapReduce源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google MapReduce的克隆版。
MapReduce的特点
- 易于编程
MapReduce已经封装好了数据拆分、数据本地性、节点挂了之后的容错性等功能,只需要调用MapReduce的各种API即可完成各种数据处理的操作。不过,相对于Spark,MapReduce的编程还是太麻烦了,Spark会更简单。
- 有良好的扩展性
可以通过添加机器的方法,实现计算能力的线性提高。
- 高容错性
基于HDFS的多副本机制,就近选取数据进行处理。当前节点的任务挂了之后,会转移到副本节点继续运行。这些都在内部封装好了,从而不会让用户感知到节点中途是否挂了。
- 适合海量数据的离线批处理
MapReduce的编程模型和性能,注定了只能应付时效性不高的应用场景,所以延时性高,不能立刻得到结果,只适合离线处理。
MapReduce的缺点
- 不适合实时计算
例如,Web应用,在页面上查询,可以在关系型数据库里面,以毫秒级别的速度获取结果。MapReduce会编译成Map和Reduce两个task进行计算,这两个task都是进程级别的,进程的开启和销毁,开销都是非常大的。
- 不适合流式计算
流式处理:时时刻刻都在产生数据,同时能够马上将这些数据处理完。然而MapReduce的输入数据是静态的,MapReduce启动以后,先要将数据拆分(split)后再执行,无法动态处理。
- 不适合DAG计算
DAG计算指的是多个应用程序存在依赖关系,A作业执行完了之后再到B作业,B执行完了之后再到C。
MapReduce编程模型
MapReduce简要步骤:input -> MapReduce -> output
例子:Wordcount――使用MapReduce来统计各个单词出现的次数。
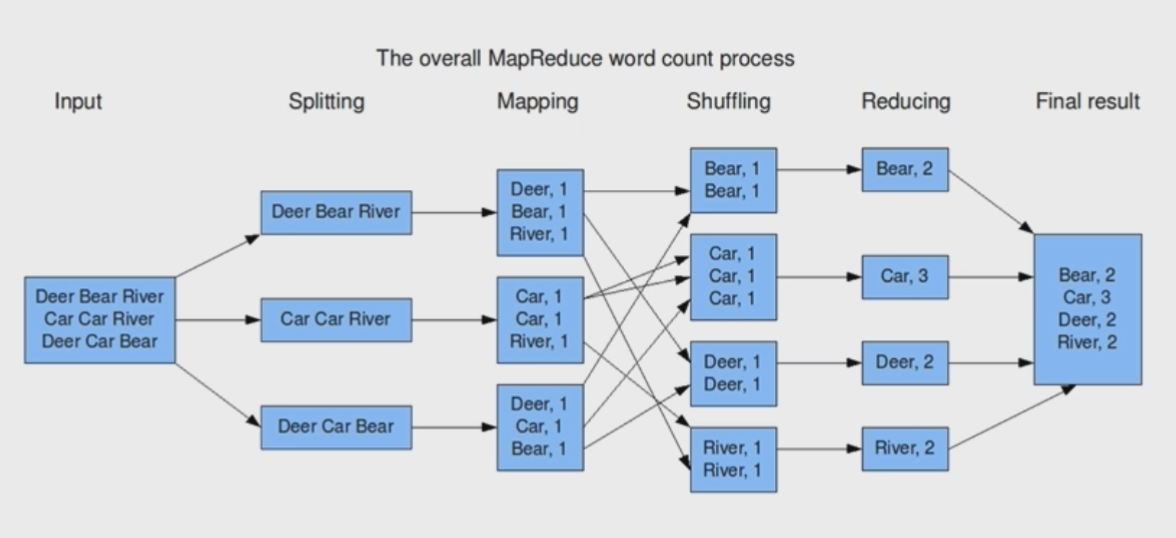
- Input:一个总共有三行的文本文件。
- Split:在分割(Split)过程中,数据按行被拆分成3块,每一块都有3个单词,送到Map步骤进行读取。
- Map:通过空格来截取单词,并单独统计单词在块中出现的次数,例如第二个Map中的两个
Car, 1,从而统计出有两个Car在这个块里面。
- Shuffle:Shuffle操作将Map步骤产生的相同的单词,转移到同一个地方。由于我们要统计分别每个单词出现的总次数,因此要将相同的单词汇总到一起,例如
Bear分到一起,Car分到一起,这就是Shuffle操作。
- Reduce:Shuffle步骤结束后,要将相同单词的出现次数累加起来,从而完成最终的求和统计操作。
- Output:各个单词,及其对应的出现次数。
参考资料:
http://hadoop.apache.org/
https://coding.imooc.com/class/112.html
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html