Hadoop 平台搭建完整步骤
环境准备

也可以用VMware.
创建三台虚拟机 hd-master、hd-node1、hd-node2 三台虚拟机服务器中的主机名(hostname)分别更改为master、node1、node2。
创建好虚拟机之后
(1) 我们为了能够更加方便来识别主机,我们使用主机名而不是使用IP地址,以免多处配置带来更多的麻烦。把hd-master、hd-node1、hd-node2三台虚拟机服务器中的主机名(hostname)分别更改为master、node1、node2。
命令如下:
cd /etc/ // 进入配置目录
vi hostname // 编程hostname 配置文件

先点击 Esc : wq 保存
在另外两个节点上进行相同的操作


(2)开启主机的DHCP模式,自动获取ip地址。方法如下:
cd /etc/sysconfig/network-scripts/ //进入网卡编辑目录
vi ifcfg-enp16777736 //编辑网卡enp0s3的配置文件

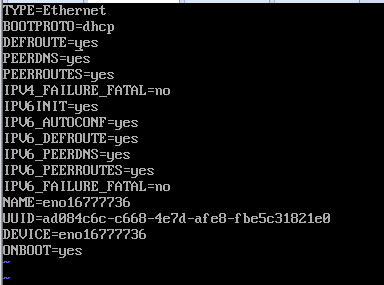
重启网卡 service network restart
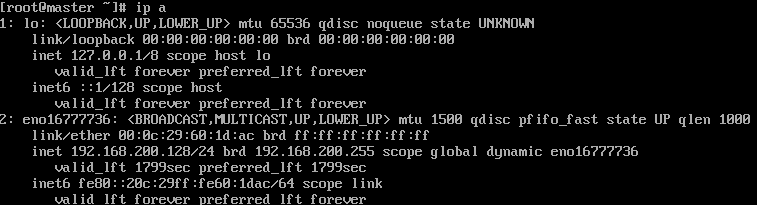
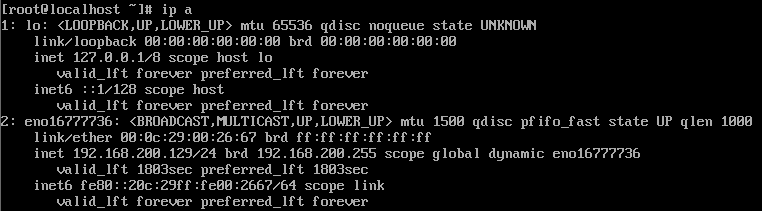
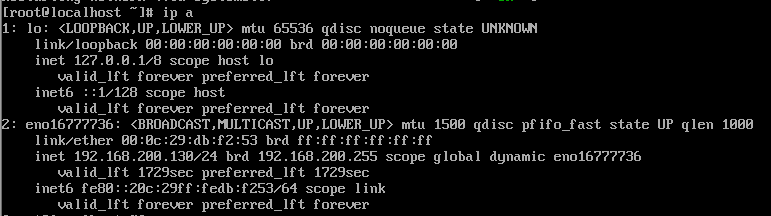
三个虚拟机的ip都记一下
master
node1
node2
(3) 配置hosts
配置 hosts 主要是为了让机器能够相互识别主机
注:hosts文件是域名解析文件,在hosts文件内配置了 ip地址和主机名的对应关系,配置之后,通过主机名,电脑就可以定位到相应的ip地址 。
vi /etc/hosts
在hosts配置文件内容输入如下内容:使用同样的方式更改node1和node2的网卡配置。

(4) ssh 免密登录
ssh 一路回车
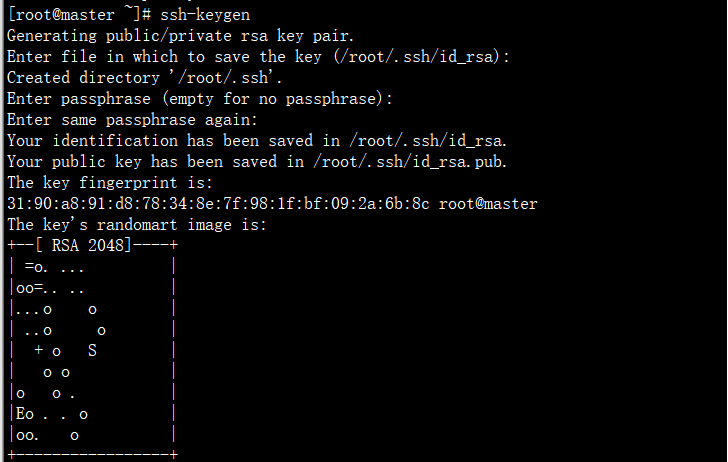
ssh-keygen
使用如下命令将公钥复制要node1和node2节点中:
ssh-copy-id root@node1
ssh-copy-id root@localhost
ssh-copy-id root@node2
使用 ssh node1 实验是否能免密登录
注意:ssh免密设置后会在如下目录生成四个文件

(5) JDK环境安装(环境配置好后, 拷贝带其他节点)
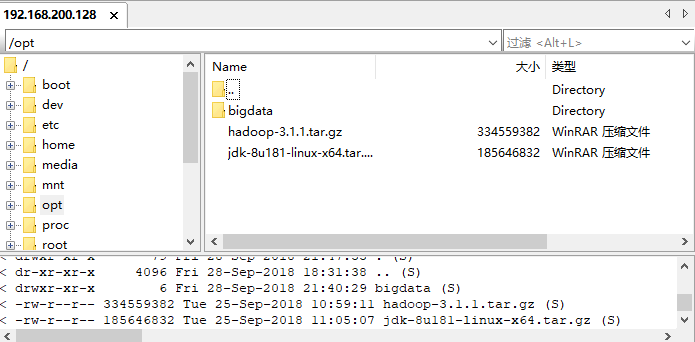
在 master 中新建目录 /opt/bigdata/, 此目录下存放 hadoop 大数据所需要的环境包.
- 把下载好的JDK包和hadoop上传至master主机中,JDK是安装Hadoop的基础环境,所以需要优先安装好JDK环境(最好把包考到opt目录下下)

连接好后将文件拖到opt目录下即可
tar -zxvf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181/ bigdata/
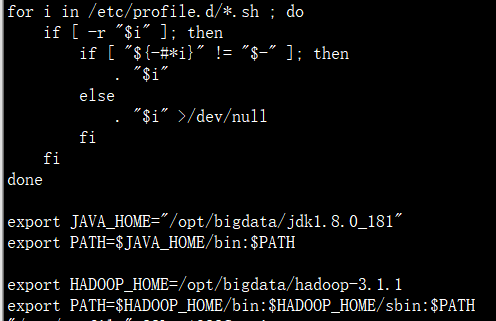
vi /etc/profile
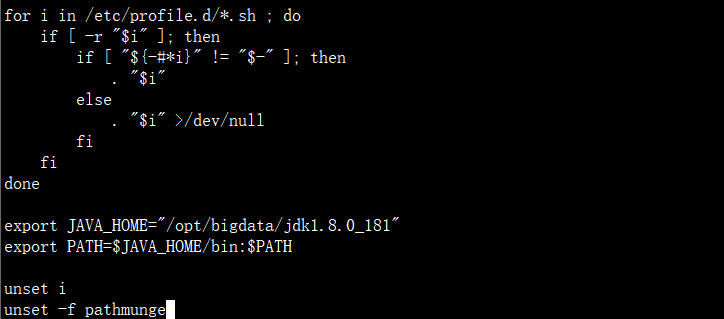
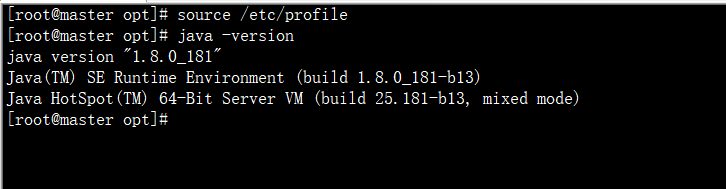
source /etc/profile
java -version #验证环境是否配置成功
(6)Hadoop 安装(环境配置好后, 拷贝带其他节点)
- 把 hadoop 的压缩包解压在当前文件夹然后移动到 bigdata 目录下
tar -zxvf hadoop-3.1.1.tar.gz
mv hadoop-3.1.1 bigdata/
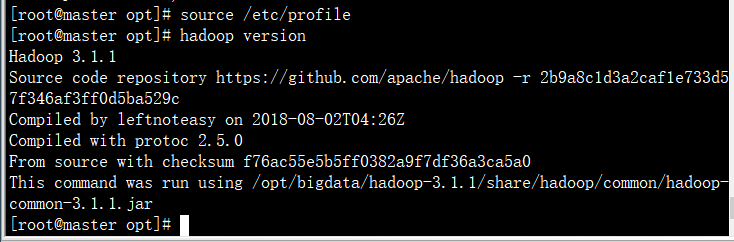
source profile
hadoop verison
配置 hadoop
cd /opt/bigdata/hadoop-3.1.1/etc/hadoop/
我们需要对 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml进行配置
(1) 配置hadoop-env.sh
编辑hadoop-env.sh文件。
命令如下:
vi hadopp-env.sh
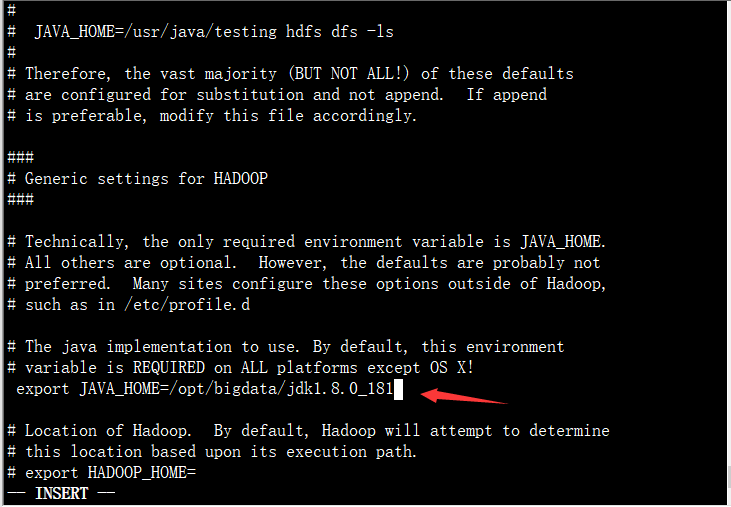
查找JAVA_HOME 配置的位置
:/export JAVA_HOME
输入JAVA_HOME的绝对路径。
export JAVA_HOME=/opt/bigdata/jdk1.8.0_181 (要把前面的注释#去掉)
(2)配置core-site.xml
编辑core-site.xml文件。
vi core-site.xml
进入core-site.xml文件中结构如下所示,找到configuration的位置。
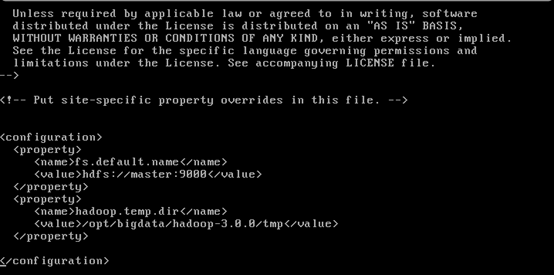
<configuration>
<property>
<name>fs.default.name</name>
<value>localhost:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/temp</value>
</property>
</configuration>
(3) 配置hdfs-site.xml
vihdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0.50070</value>
</property>
</configuration>
(3)配置mapred-site.xml
vimapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
</property>
</value>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/bigdata/hadoop-3.1.1/etc/hadoop,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(5)配置yarn-sit.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
(6)配置workers
此处因为前面配置了hosts,所以此处可以直接写主机名,如果没有配置,必须输入相应主机的ip地址。配置的workers,hadoop会把配置在这里的主机当作datanode。
node1
node2
(7)hadoop复制到其他host
把hadoop复制到所有datanode节点,此处是node1和node2。
命令如下:
scp -r * node1:/opt/
scp -r * node2:/opt/
starta-all.sh 启动