版权声明: https://blog.csdn.net/u013063153/article/details/75201146
Spark Streaming
Storm
Data sources
HDFS, HBase, Cassandra,Kafka
HDFS, Base,Cassandra,Kafka
Resource Manager
YARN, Mesos
YARN, Mesos
Latency
Few seconds
<1 second
Fault tolerance(every recourd processed)
Exactly once
At least once
Reliability
Imporoved reliability(Spark + YARN)
Guarantees on data loss(Storm + Kafka)
区别:
1.Latency
2.Fault tolerance
3.Reliability
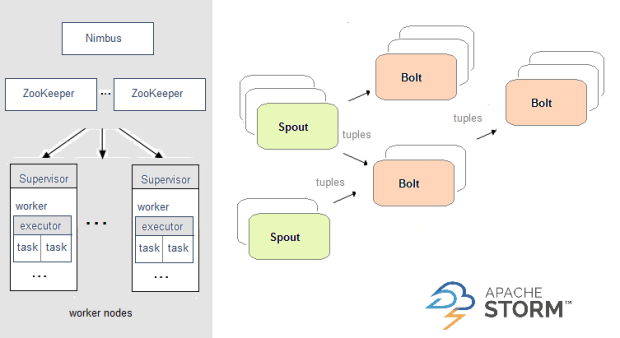
Storm架构
Supervisor:从节点,物理机器
Worker: Supervisor的进程
executor: Worker的线程
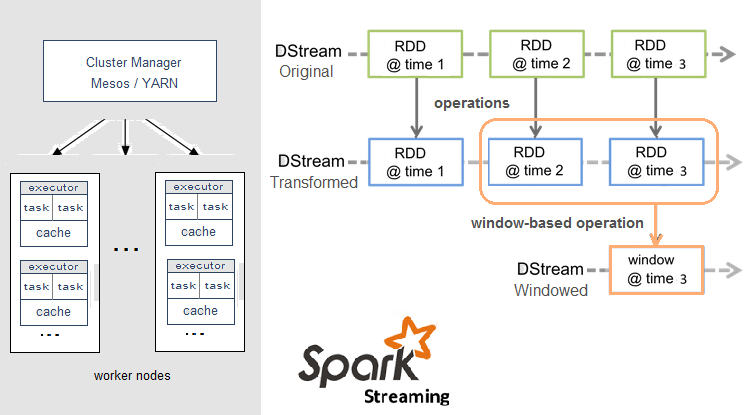
Spark Streaming架构:
worker: 物理节点
executor: 进程
------------------------------
Data Source: