版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/gangchengzhong/article/details/80523922
1 概述本文档用于没有配置高可用的HDFS集群版本升级执行的详细步骤说明,版本由2.7.3升级到2.9.0。
2 前提条件假设已有安装配置好整合了Kerberos的HDFS集群和YARN,本文使用5台服务器,角色分别为:
hadoop0:NameNode、SecondaryNameNode、ResourceManager
hadoop1:DataNode、NodeManager
hadoop2:DataNode、NodeManager
hadoop3:DataNode、NodeManager
kerberos:Kerberos
3 升级执行步骤
3.1 备份在升级前最好做好数据和配置文件的备份,以免升级失败需要回滚。
[非重点,这里省略具体步骤]
3.2 部署新版本
[分别在HDFS集群的所有服务器上执行,本文是hadoop0/1/2/3]上传hadoop-2.9.0.tar.gz到/bigdata/目录,执行以下命令解压和创建日志目录:
# cd /bigdata/
# tar -zxvf /bigdata/hadoop-2.9.0.tar.gz
# chown -R hdfs:hadoop /bigdata/hadoop-2.9.0
$ su hdfs
$ mkdir /bigdata/hadoop-2.9.0/logs
$ chmod 775 /bigdata/hadoop-2.9.0/logs
把旧的配置文件(*.sh和*.xml)替换到新版本的配置目录/bigdata/hadoop-2.9.0/etc/hadoop/,本文替换了9个文件,如下图:
修改所有配置文件里面定义的路径指向新版本的路径,例如是hadoop-env.sh的HADOOP_PREFIX=/bigdata/hadoop-2.9.0
3.3 停止HDFS集群因为集群没有配置高可用,所以升级版本必须要先停止旧版本的集群。
# su hdfs
$ cd /bigdata/hadoop-2.7.3
$ sbin/stop-dfs.sh
3.4 复制数据文件HDFS集群的数据文件是保存在${hadoop.tmp.dir}目录,默认是/tmp/hadoop-${user.name},此配置可以在core-site.xml重新配置,建议修改。
本文因为新旧版本的数据目录都是使用同一个,所以不需要复制数据。否则的话需要把数据复制到新版本指向的数据目录。
3.5 启动HDFS集群在NameNode服务器上操作:
使用root用户启动安全DataNodes:
# cd /bigdata/hadoop-2.9.0
# sbin/start-secure-dns.sh
使用hdfs用户启动NameNode:
# su hdfs
$ sbin/start-dfs.sh
启动集群后查看日志会显示正在同步数据:
2018-04-27 15:06:36,754 INFO org.apache.hadoop.hdfs.server.common.Storage: Start linking block files from /bigdata/tmp/hadoop-hdfs/dfs/data/current/BP-185965420-192.168.1.10-1499766135884/previous.tmp/finalized to /bigdata/tmp/hadoop-hdfs/dfs/data/current/BP-185965420-192.168.1.10-1499766135884/current/finalized
同步数据的时候需要等待一段时间,视乎数据量大小。可以使用du -sh 查看对应current目录大小是否和previous.tmp目录大小一致,也可以访问集群的启动过程页面查看:
http://{namenode_ip}:50070/dfshealth.html#tab-startup-progress

本文使用了大概27分钟同步560GB数据。
3.6 升级数据
3.6.1 进入安全模式在NameNode服务器执行以下命令:
# su hdfs
$ kinit hdfs/hadoop0
$ cd /bigdata/hadoop-2.9.0
$ bin/hdfs dfsadmin -safemode enter
Safe mode is ON
[如果不执行此步骤会提示:Safe mode should be turned ON in order to create namespace image]
3.6.2 滚动升级准备$ bin/hdfs dfsadmin -rollingUpgrade prepare
执行以上命令后会显示以下信息:
PREPARE rolling upgrade ...
Proceed with rolling upgrade:
Block Pool ID: BP-185965420-192.168.1.10-1499766135884
Start Time: Fri Apr 27 15:34:37 CST 2018 (=1524814477898)
Finalize Time: <NOT FINALIZED>
重复执行以下命令,直至出现Proceed with rolling upgrade信息
$ bin/hdfs dfsadmin -rollingUpgrade query
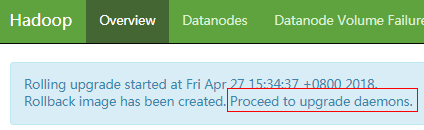
同时,查看集群的概要页面http://{namenode_ip}:50070/dfshealth.html#tab-overview会提示:
Rolling upgrade started at Fri Apr 27 15:34:37 +0800 2018.
Rollback image has been created. Proceed to upgrade daemons.
 3.6.3 升级NameNode和SecondaryNameNode
3.6.3 升级NameNode和SecondaryNameNode继续在NameNode服务器执行以下命令,注意上一步骤已使用kinit命令登录kerberos:
$ sbin/hadoop-daemon.sh stop namenode
$ sbin/hadoop-daemon.sh start namenode -rollingUpgrade started
3.6.4 升级所有DataNode分别在所有DataNode执行以下命令:
在hadoop1上执行:
# su hdfs
$ kinit hdfs/hadoop1
$ bin/hdfs dfsadmin -shutdownDatanode hadoop1:50020 upgrade
$ bin/hdfs dfsadmin -getDatanodeInfo hadoop1:50020
Retrying connect to server: hadoop1/192.168.1.11:50020. Already tried 0 time(s)
在hadoop2上执行:
# su hdfs
$ kinit hdfs/hadoop2
$ bin/hdfs dfsadmin -shutdownDatanode hadoop2:50020 upgrade
$ bin/hdfs dfsadmin -getDatanodeInfo hadoop2:50020
Retrying connect to server: hadoop2/192.168.1.12:50020. Already tried 0 time(s)
在hadoop3上执行:
# su hdfs
$ kinit hdfs/hadoop3
$ bin/hdfs dfsadmin -shutdownDatanode hadoop3:50020 upgrade
$ bin/hdfs dfsadmin -getDatanodeInfo hadoop3:50020
Retrying connect to server: hadoop3/192.168.1.13:50020. Already tried 0 time(s)
3.6.5 启动DataNode在NameNode服务器上使用root用户执行:
# sbin/start-secure-dns.sh
3.7 检查数据完整性在NameNode服务器上操作:
上传CheckHDFSShell.jar到/bigdata/hadoop-2.9.0/目录,然后执行以下命令:
# su hdfs
$ cd /bigdata/hadoop-2.9.0
$ bin/hadoop jar CheckHDFSShell.jar \
hdfs.CheckHDFSIntegrity \
hdfs://hadoop0:9000 \
/user hdfs/hadoop0@BDP.DOMAIN \
/bigdata/kerberos-1.16/var/krb5kdc/hdfs.keytab
出现以下结果表示正常:
.....
Adding Directory: hdfs://hadoop0:9000/user
finished the check, /user/* is fine.
3.8 其它验证方式
3.8.1 查看集群页面访问集群的概要页面http://{namenode_ip}:50070/dfshealth.html#tab-overview,查看Version等信息是否正确,这里是2.9.0版本。
访问DataNode页面http://{namenode_ip}:50070/dfshealth.html#tab-datanode,查看所有DataNode是否为In service状态。
3.8.2 读取数据在NameNode上使用Spark读取数据:
打开spark-shell:
# su spark
$ /bigdata/spark-2.2.1-bin-hadoop2.7/bin/spark-shell \
--principal hdfs/hadoop0@BDP.DOMAIN \
--keytab /bigdata/kerberos-1.16/var/krb5kdc/hdfs.keytab
读取数据:
scala> spark.read.parquet("hdfs://hadoop0:9000/user/test/*").show(1, false)
如果一切正常会显示1条数据。
3.8.3 启动YARN在NameNode上执行以下命令启动YARN:
# su yarn
$ cd /bigdata/hadoop-2.9.0
$ sbin/start-yarn.sh
访问YARN页面http://{namenode_ip}:8088查看状态是否正常。
3.9 完成滚动升级在NameNode上执行以下命令完成升级:
# su hdfs
$ bin/hdfs dfsadmin -rollingUpgrade finalize
执行后会显示以下信息:
FINALIZE rolling upgrade ...
Rolling upgrade is finalized.
Block Pool ID: BP-185965420-192.168.1.10-1499766135884
Start Time: Fri Apr 27 15:34:37 CST 2018 (=1524814477898)
Finalize Time: Fri Apr 27 16:23:48 CST 2018 (=1516004628839)