��飺���ŶԴ����ݵ����⣬HDFS�Dz����ڴ����ݵ����ݴ洢��MapReduce�Dz����ڼ���������ķ��䣻
Page Rank ������������ ʲô��MapReduce
1�� �����Ǵ�ҳ�������ȡ��HDFS��������
2�� Map �������Reduce�����룻
3�� Map��������HDFS, Reduce�����Ҳ�� HDFS;
4�� һ����4���������������key��value����ʽ��
5�� һ��MR������job=map+Reduce;
6�� ���е�key,value�������Ͷ���Hadoop�Լ����������ͣ�
7�� String------text; int-----IntWritable ; long -----longWritable null------nulllWritable;��.
8�� ���е�Hadoop���Ͷ�����ʵ��Hadoop���л�����ʵ��Writable�ӿڣ�
9�� ���һ����ʵ����Writable�ӿڣ����Ķ���Ϳ�����ΪMR�������������
HDFS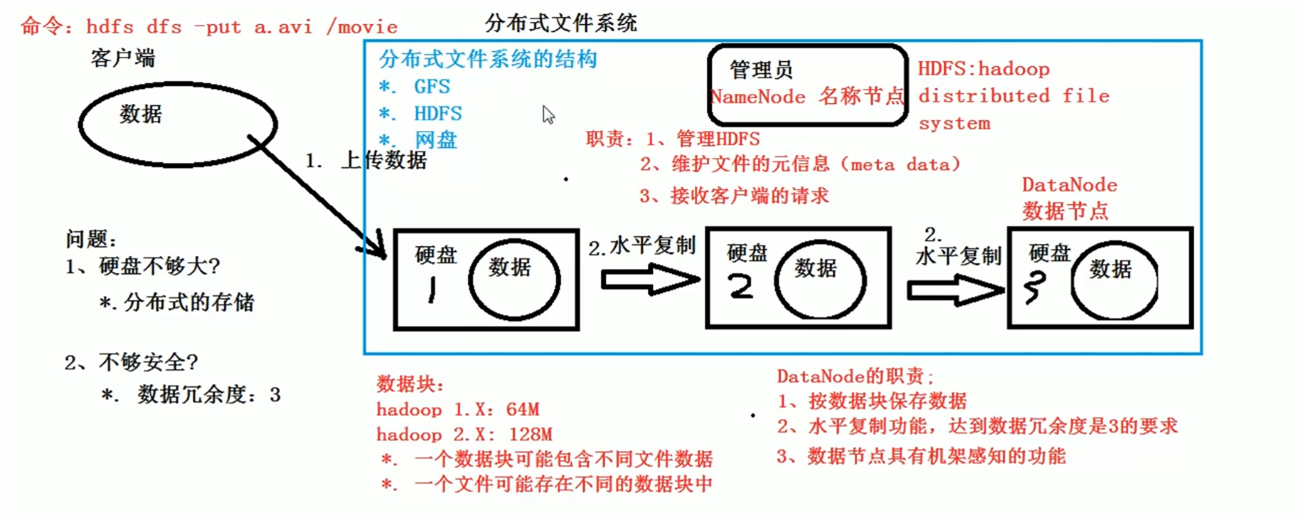
MapReduce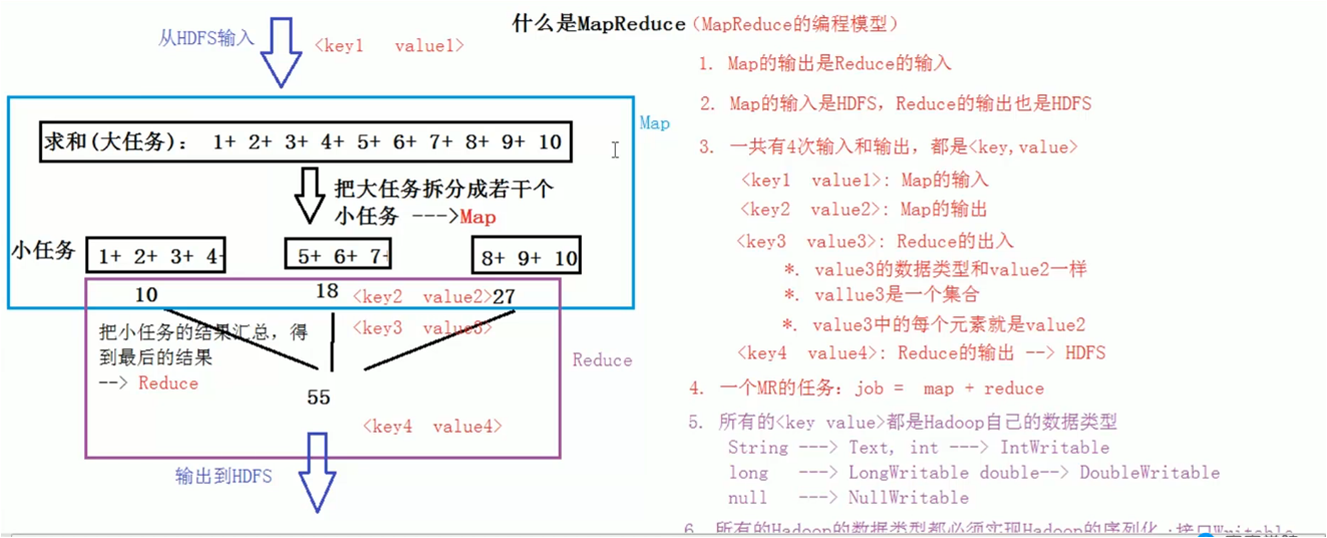
Yarn���ܣ�
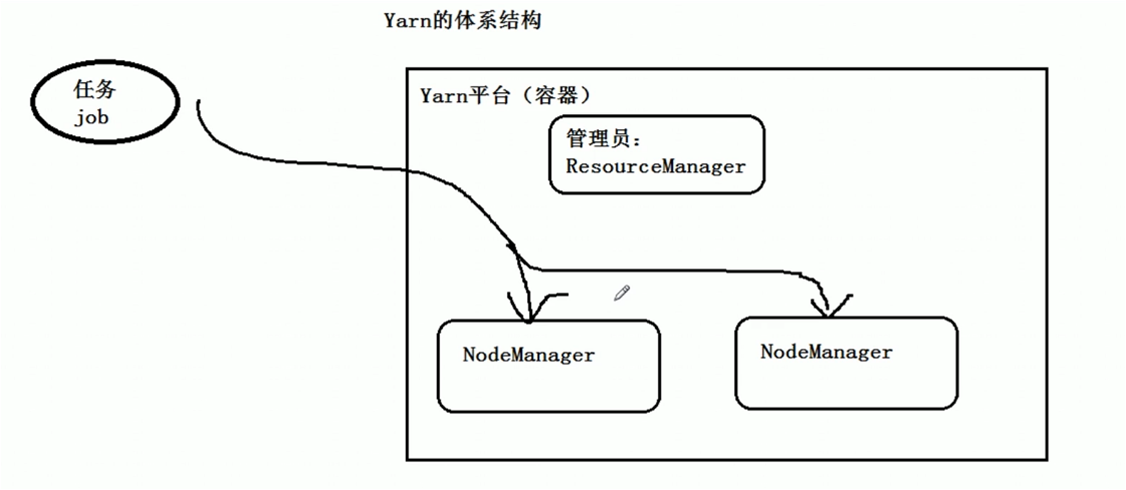
����HDFS��yarn;
1��startdfs.sh stop dfs.sh start yarn.sh stop yarn.sh
2���ܵľ���start �Call.sh stop �Call.sh
YarnҲ�������ڵ�������ִ�еĽڵ� resourceManager �� nodeManager
��װ�ɹ��Ժ���Կ����½��� jps ��Java�����which jps�Ϳ��Կ���λ�ã�
���Բ鿴��־
MapReduce ��Ĭ�ϵ�����
1���ַ��������ֵ�
2�����ְ��� ����
��ע��
- ʲô��hdfs��
hdfs��һ�ֲַ�ʽϵͳ���������namenode�ڵ��datanode�ڵ㡣����˼�壬namenode�ǡ����ֽڵ㡱���洢�����ⲿ�ִ洢����������Ϣ��������datanode�ڵ㣻��datanode�洢�ľ������ݡ�һ��namenode��Ӧһ������datanode�ڵ㣬ÿһ��datanode������һ̨�����ϣ�������Щdatanode��ϵ�һ���γ�һ����Ⱥ��cluster����ʵ�������ķֲ�ʽ�洢�ļ�����Ҫע�����namenode��datanode����������ͬһ̨�����ϡ�
����֮�⣬hdfs�ر�ĵط��ǣ���ǿ�˴洢�ļ��İ�ȫ�Ժ������ԡ�namenode���ڸ����ڵ㣨standby node���������ڵ�������⣬���������еĻ�������崻�������standby�ڵ���ȡ�������datanode�Ĺ���Ȩ�ޣ�����ÿһ�����ݽ������ڼ�����ͬ��datanode���棨���ݼ�Ⱥ��datanode�������������ݸ���������ˣ���Ӧ�Ľ�����һ���洢ӳ���������¼ÿһ�����ݷֱ�洢����Щ�ڵ��У�����namenode���й����Ͳ�ѯ��
- ʲô��yarn
yarn��һ����Դ�������ߣ�����������Դ����������Ҳ�Ǽ�Ϊ��Ȥ��YARN��Yet Another Resource Negotiator����һ����ԴЭ���ߣ���
�������������� ��ResourceManager��NodeManager��ApplicationMaster�Լ�Container��ɣ�����˼���ǽ�JobTracker�е���Դ��������ҵ���Ƚ��з��룬�ֱ�ResourceManager��ApplicationMaster���й�����ApplicationMaster �е�����ǰ�� TaskTracker ��һЩ��ɫ��ResourceManager �е��� JobTracker �Ľ�ɫ��
��.��������
����Ĭ���Ѿ��ɹ���װ���������hadoop����δ��װ��ɲο�������ַ��http://www.imooc.com/learn/391
- namenode����������
���ォnamenode��datanode��������dfs���������������Ϊ�˽��ʹ���ɱ���ȫ������hdfs�Ļ����ܻ�������⡣
ע�⣺��һ������hdfs����Ҫ���и�ʽ������������Ҷ��������������Ŀ�����������������������/sbinĿ¼�½��У�
����namenode
hadoop-daemon.shstart namenode
��֤�Ƿ�����������ͨ��java�Ľ�������jps����⣬�����namenode������˵�������ɹ���������Ҫ�������������ͬ��
����datanode
hadoop-daemon.shstart datanode
����yarn
����yarn�Ľṹ���ԣ��˴��Ƽ���yarn�����й���һ��������
������ʽ���£�
start-yarn.sh
ͬ��ͨ��jps������м�⣬�ܹ���ResourceManager��NodeManager���̡�
��.�鿴������Ϣ
���ͨ�����ϲ����ܹ��ɹ�����hdfs��yarn����ô�Ϳ��Ե���ҳ�в鿴�洢�ļ�����Ϣ����Դ��������Ϣ���鿴�ķ������£�
1. �鿴yarn
����yarn�Ķ˿�Ϊ50700������������ַ��������
yarn001:50700
ע�⣬������ַ������hadoop�������ļ��������õı���һ�£��ҵĽ�����ַ����Ϊyarn001����ͬ��
1. �鿴hdfs
����hdfsϵͳ�Ķοں�Ϊ8088������������ַ��������
yarn001:8088