ֻ�й�ͷ���ܱ�ǿ!
ǰһƪ��������nginx+ftp��������ļ�������
�����������崻�����ô�죿
������hdfs�ֲ�ʽ�ļ�ϵͳ�����������⣨ͬʱҲΪhadoopϵ�п���ͷ��
Ŀ¼
1��Ubuntu14.04������Hadoop(2.8.5)��Ⱥ�������(��ȫ�ֲ�ʽ��
1.1��ǰ����
1.2�������û���
1.3����װssh
1.3.1��ʵ��ssh���ܲ���
1.4����װjdk
1.5����װhadoop
1.6����������
2.1����¡��ʱ�������
2.2��ssh���ܵ�½
1��3�������A,B,C ���������������
2.3����hosts��hostname�ļ�
1����hostname�ļ�
2����hosts�ļ�
2.4���������ϵ�hadoop�д����ļ���
2.5������������hadoop�������ļ�
2.6�����ĺõ�hadoop���ӵ��ӻ���
2.7�������и�ʽ��namenode
2.8������hdfs
2.9���鿴hdfs���̣�������+�������
2.10����ֹhdfs
2��HDFS��������
2.1�����ӽ��
2.2�����ؾ���
3��java ����hdfs��Ⱥ
3.1������application.properties:
3.2��HdfsUtils
3.3��controller��
3.4���������
1��������bug��
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
2������һ��bug��������ֳ���һ���µ�����
java.io.IOException: Could not locate executable C:\hadoop-2.8.5\hadoop-2.8.5\bin\winutils.exe in the Hadoop binaries.
3) ����CDHҳ������HDFS�ļ���ַ��������
3.5����֤�Dz��Ǽ�Ⱥ
1��Ubuntu14.04������Hadoop(2.8.5)��Ⱥ�������(��ȫ�ֲ�ʽ��
1.1��ǰ����
һ̨װ�������VMware��win10����= =
Ubuntu14.04����
���������������װ��һ��Ubuntu14.04��ϵͳ������������ܼ����̾�ʡ������
һ�����ɣ�������֮���ٿ�¡2�������ڲ��ÿ�¡��
1.2�������û���
Ϊhadoop��Ⱥר������һ���û��鼰�û�
$ sudo su root //�л���rootȨ����
$ adduser hadoop
��̨������Ҫ����ͬ���ֵ��û����˴�����Ϊhadoop�� ������Ūһ���������֮���ٿ�¡
ubuntu�¿�����adduser����useradd���������û������߲���Ϊ���û������ļ��С�
�����ͼ��

Ȼ��
�����û�����Ҫ��Ȩ�����������û�����sudo�ᱨ��
root�û��£�
vim /etc/sudoers
���ļ����£�
�������¸��ƴ���
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL //������仰��Ϊ����hadoop�û�Ҳ��ʹ��sudo��
���棬��Ȩ���
su hadoop (�л����Լ����˺�)
1.3����װssh
�����ٷ��ĵ���Ҫ��Ҫ����ssh
�鿴�Ƿ�װ��ssh��openssh-server��������Զ�����ӡ�
�Ƽ���������ssh������һ��װ
$sudo apt-get install ssh
���г��õ����
#�鿴ssh��װ�����
dpkg -l | grep ssh
#�鿴�Ƿ�����ssh����
ps -e | grep ssh
#��������
sudo /etc/init.d/ssh start
1.3.1��ʵ��ssh���ܲ���
��Ϊhadoop���й�������Ҫ���ӻ���Ƶ������ssh��½�����û���������½����Ҫһֱ��������
����ȷ��ţ��Ȼ�����������������
1.4����װjdk
�ڰ�װjava֮ǰ������Ҫ���ϵͳ����û�а�װjava,ʹ��java -version�������鿴�Ƿ�װ��java�������װ�������汾��java����ж��֮��װjava1.8.0��
���ص�ַ��https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
���� jdk-8u191-linux-x64.tar.gz
��ʱ���ǽ�����ļ���ѹ����/usr/java/Ŀ¼��(���ڽ�ѹ��֮ǰ�½����Ŀ¼)
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/java/
�ڽ�ѹ��֮��,���û������� $vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
д�껷������֮��ʹ��
$source ~/.bashrc
ʹ���������Ѿ���Ч��
���$java �Cversion ���java�汾

��װ�ɹ�
1.5����װhadoop
����Hadoop
https://hadoop.apache.org/releases.html
���а汾����source��Դ�룩��binary���ѱ��룩�汾����ѡ�˺���
hadoop-2.8.5.tar.gz
��ѹ������ѹ��/usr/hadoop:
$sudo mkdir /usr/hadoop
$sudo tar zxvf hadop-2.8.5.tar.gz -C /usr/hadoop
#��bashrc�ļ�
$sudo vim ~/.bashrc
----------------------
#set hadoop environment
export HADOOP_INSTALL=/usr/hadoop/hadoop-2.8.5
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
---------------------
��ִ�����
$source ~/.bashrc
����Ƿ�װ�ɹ���ִ���������������������ʾ�ɹ���hdfs
1.6����������
���������������Ļ���hadoop�Ѿ����Ե��������ˡ��������Դ������Ӽ��顣
hadoop��������hadoop/share/hadoop/mapreduce/�£���Ϊhadoop-mapreduce-examples-�汾��.jar
$cd /usr/hadoop/hadoop-2.8.5
#����inputĿ¼����������/usr/hadoop/hadoop-2.8.5/etc������xml�ļ�����Ŀ¼��
$ sudo mkdir input
$ sudo cp etc/hadoop/*.xml input
#����ʾ�������input�з���' '������ƥ�����ĵ��ʳ��ֵĴ���������Ϊdfs��ͷ�ĵ��ʣ�
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar grep input output 'dfs[a-z.]+'
#�鿴���
$ cat output/*
����������У�����success���ɹ���hadoop�»��Զ�����һ��output�ļ�������Ž���������´�����ʱ�����Զ����ǣ��ٴ�����ʾ��ʱ�ᱨ����Ҫ�Ȱ��ϴεĽ��ɾ����
������Error:JAVA_HOME is not set and could not be found
���ȼ��~/.bashrc�е�JAVA_HOME
https://stackoverflow.com/questions/8827102/hadoop-error-java-home-is-not-set
$sudo vim /usr/local/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_191
����һ��
�ɹ�

2.1����¡��ʱ�������
��ʡ��
2.2��ssh���ܵ�½
��������1.3.1��
https://www.linuxidc.com/Linux/2016-04/130722.htm
SSH��Ҫͨ��RSA�㷨��������Կ��˽Կ�������ݴ�������ж����ݽ��м�����������
�ݵİ�ȫ�ԺͿɿ��ԣ���Կ�����ǹ������֣���������һ�������Է��ʣ�˽Կ��Ҫ���ڶ����ݽ��м��ܣ��Է����˵�ȡ���ݡ��ܶ���֮������һ�ַǶԳ��㷨����Ҫ�ƽ�Ƿdz����Ѷȵġ�Hadoop��Ⱥ�ĸ������֮����Ҫ�������ݵķ��ʣ������ʵĽ����ڷ����û����Ŀɿ��Ա��������֤��hadoop���õ���ssh�ķ���ͨ����Կ��֤�����ݼӽ��ܵķ�ʽ����Զ�̰�ȫ��¼��������Ȼ�����hadoop��ÿ�����ķ��ʾ���Ҫ������֤����Ч�ʽ����ͣ����Բ���Ҫ����SSH������ķ���ֱ��Զ�����뱻���ʽ�㣬�����������߷���Ч�ʡ�
1��3�������A,B,C ���������������
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
���ԣ�$ssh localhost
exit �˳�
2����A���µ�id_rsa.pub���Ƶ�B���û��£���B����.ssh/authorized_keys�ļ����scp���ơ��£û���ʱû���������ǵǣ�������Ҫ��ͬ����
$ifconfig
192.168.23.137 A
192.168.23.135 B
192.168.23.136 C
�;�һ�����ӣ���A���µ�id_rsa.pub���Ƶ�B��
hadoop@zj-virtual-machine:~$ scp ~/.ssh/id_dsa.pub hadoop@192.168.23.135:~/.ssh/authorized_keys
�����
The authenticity of host '192.168.23.135 (192.168.23.135)' can't be established.
ECDSA key fingerprint is 75:7f:24:c6:cf:81:66:da:57:98:21:7b:a8:b3:91:1f.
Are you sure you want to continue connecting (yes/no) yes
Warning: Permanently added '192.168.23.135' (ECDSA) to the list of known hosts.
hadoop@192.168.23.135's password:
id_dsa.pub 100% 615 0.6KB/s 00:00
���������scp Զ�̸���
-r�ݹ�
�����ļ���ַ app���ļ�(�Ӹ�Ŀ¼��ʼ)
Զ��������@Զ������ip:Զ���ļ���ַ(�Ӹ�Ŀ¼��ʼ)
��A���ϲ��ԣ�
ssh 192.168.23.135
exit
��A���µ�id_rsa.pub���Ƶ�C��ͬ��
ps:�������½�Ƿ��û��ģ���.ssh�ļ������û��ļ������йأ�����������ж���û�����abc��hadoop���ǵ�scp��ssh��ʱ����hadoop�û�����һ���û���Ҫ��½�Ļ���Ҫ���´�1��ʼ������Կ
2.3����hosts��hostname�ļ�
�ȼ�˵��������hosts�ļ������ã�����Ҫ����ȷ��ÿ������IP��ַ���������
master����ܿ��ٲ鵽�����ʸ�����㡣������3���������Ͼ���Ҫ���ô��ļ�
1����hostname�ļ�
$sudo vim /etc/hostname
����ļ���Ҫ��ȷ����̨�������֣�������Ϊmaster,�ӻ���Ϊslave1, slave2,���֮ǰ�Ѿ�ȡ�����ֿ��Բ��øģ�ֻҪ֮���Ӧ�������־��У�����һ��Ҫ��master,slave֮��ģ�
�鿴��ǰ�������IP��ַ�Ƕ���
$ifconfig
2����hosts�ļ�
$sudo vim /etc/hosts
���ļ�������
127.0.0.1 localhost(һ��������䣬������ӣ�
192.168.23.137 master
192.168.23.135 slave1
192.168.23.136 slave2
ͬʱ�����������
2.4������������hadoop�д����ļ���
$cd /usr/hadoop/hadoop-2.8.5
$mkdir tmp
$mkdir tmp/dfs
$mkdir tmp/dfs/data
$mkdir tmp/dfs/name
$sudo chown hadoop:hadoop tmp
2.5������������hadoop�������ļ�
��Ҫ�漰���ļ��У�
/usr/hadoop/hadoop-2.8.5/etc/hadoop�еģ�
--------------------------------
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves
----------------------------------
$cd /usr/hadoop/hadoop-2.8.5/etc/hadoop
#�������ļ�ʱ��������hadoop-env.sh�滻�������ļ�������
$cp hadoop-env.sh hadoop-env_old.sh
����Ϊ���ļ��е������ݣ�
��1��hadoop-env.sh
�ҵ�JAVA_HOME��һ��
ע�͵�ԭ����export, ��Ϊ
export JAVA_HOME=/usr/java/jdk1.8.0_191
��2��yarn-env.sh
�ҵ�JAVA_HOME��һ��
ע�͵�ԭ����export, ��Ϊ
export JAVA_HOME=/usr/java/jdk1.8.0_191
��3��core-site.xml
<configuration>
<!-- ָ��hdfs��nameserviceΪns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- ָ��hadoop��ʱĿ¼,���д��� -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.groups</name>
<value>*</value>
</property>
</configuration>
PS:
1��hdfs://master:8020 ��master������������֮ǰ��hostname��Ӧ��8020�Ƕ˿ںţ�ע�ⲻҪռ�����ö˿ھͿ�
2��file: /usr/hadoop/hadoop-2.8.5/tmp ָ�����ոմ������ļ���
3�����е������ļ�< name >��< value >�ڵ㴦��Ҫ�пո���ᱨ��
4��fs.default.name��NameNode��URI��hdfs://������:�˿�/
5��hadoop.tmp.dir ��Hadoop��Ĭ����ʱ·�������������ã�����������ڵ�������������Ī�������DataNode�������ˣ���ɾ�����ļ��е�tmpĿ¼���ɡ��������ɾ����NameNode�����Ĵ�Ŀ¼����ô����Ҫ����ִ��NameNode��ʽ�������
6������������ͬ
��4��hdfs-site.xml
---------------------------------
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
---------------------------------
dfs.name.dir��NameNode�־ô洢���ֿռ估������־�ı����ļ�ϵͳ·���� �����ֵ��һ�����ŷָ��Ŀ¼�б�ʱ��nametable���ݽ��ᱻ���Ƶ�����Ŀ¼�������౸�ݡ�
dfs.data.dir��DataNode��ſ����ݵı����ļ�ϵͳ·�������ŷָ���б��� �����ֵ�Ƕ��ŷָ��Ŀ¼�б�ʱ�����ݽ����洢������Ŀ¼�£�ͨ���ֲ��ڲ�ͬ�豸�ϡ�
dfs.replication��������Ҫ���ݵ�������Ĭ����3������������ڼ�Ⱥ�Ļ������������
( 5 ) mapred-site.xml.template
------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
( 6��yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
(7) slaves
���ļ���¼��hadoop�е����еĴӻ��ڵ�
���ļ������ӣ�
slave1
slave2
2.6�����ĺõ�hadoop���ӵ��ӻ���
�ӻ��������е�hadoop�ļ���������һ���ġ�����ӻ���jdk·������hadoop·����һ��������Ӧ���ļ�����·��(����֮ǰ��bashrc�ȣ����ɡ�Ϊ�˷��㣬���������л���·����ͬ�����������ϵ�hadoop�ļ��зŵ��ӻ��ϵ�ͬһλ�á�ֱ�ӷŵ�usr�¿��ܻ�û��Ȩ�ޣ�������scp�����ļ����£���mv��ȥ
$sudo scp -r /usr/hadoop/hadoop-2.8.5 hadoop@192.168.23.135:/home/hadoop
�ϴ���Ϻ��ڴӻ��ϻῴ�����ļ����¶����hadoop-2.8.5�ļ���
�ӻ��նˣ�
$cd /usr/hadoop
$mv hadoop-2.8.5 hadoop-2.8.5_old //��֮ǰ�ĸ���
$cd ~
$ sudo mv hadoop-2.8.5 /usr/hadoop/
$ sudo chown hadoop:hadoop /usr/hadoop/hadoop-2.8.5
���˼���Ƿ�ÿһ̨���϶����й���ͷ���������в����е�1-6���裨���ƹ�ȥ���൱���ѽ��иò��裬���������Ǹ���ǰ��ij���Ļ��ƺ����������ݣ���·�����������ȣ������ܵ���֮�������
slave2ͬ��
2.7�������и�ʽ��namenode
$ cd /usr/hadoop/hadoop-2.8.5
$ bin/hdfs namenode -format
ע��ֻ���ڳ�ʼʱ��ʽ��namenode�������и�ʽ���ᶪʧ����
2.8������hdfs
$ start-all.sh

2.9���鿴hdfs���̣�������+�������
��ÿһ̨��������
$ jps
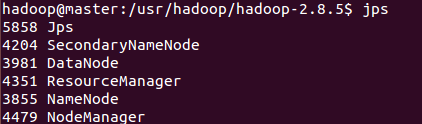
���Կ�����master ��������SecondaryNamenode, ResourceManager, NameNode
����slave��������DataNode,NodeManager
�������
Ĭ�Ϸ��ʵ�ַ��http://namenode��ip:50070

���https://blog.csdn.net/superzyl/article/details/53741033
2.10����ֹhdfs
/usr/local/hadoop$ stop-all.sh
PS�����ڷ���ǽ����Щ�����ᵽ�˹رշ���ǽ��������ʱ��û�������������������˸ò���
�������û����ɹ�
���https://blog.csdn.net/ycisacat/article/details/53325520
2��HDFS��������
hdfs dfs -ls �г�HDFS�µ��ļ�
hadoop dfs -ls in �г�HDFS��ij���ĵ��е��ļ�
hadoop dfs -put test1.txt test �ϴ��ļ���ָ��Ŀ¼��������������ֻ�����е�DataNode�����������ݲ���ɹ�
hadoop dfs -get in getin ��HDFS��ȡ�ļ�������������Ϊgetin��ͬputһ���ɲ����ļ�Ҳ�ɲ���Ŀ¼
hadoop dfs -rmr out ɾ��ָ���ļ���HDFS��
hadoop dfs -cat in/* �鿴HDFS��inĿ¼������
hadoop dfsadmin -report �鿴HDFS�Ļ���ͳ����Ϣ���������
hadoop dfsadmin -safemode leave �˳���ȫģʽ
hadoop dfsadmin -safemode enter ���밲ȫģʽ
=====================
��������binĿ¼ͬ����Ŀ¼��ʹ�ã�����û�㻷��������
hdfs dfs �Cls / ���鿴��Ŀ¼�ļ�
hdfs dfs -ls /tmp/data���鿴/tmp/dataĿ¼
hdfs dfs -cat /tmp/a.txt ���鿴 a.txt���� -text һ��
hdfs dfs -mkdir dir������Ŀ¼dir
hdfs dfs -rmdir dir��ɾ��Ŀ¼dir
2.1�����ӽ��
����չ����HDFS��һ����Ҫ���ԣ��������¼ӵĽڵ��ϰ�װhadoop��Ȼ����$HADOOP_HOME/conf/master�ļ������� NameNode��������Ȼ����NameNode�ڵ�����$HADOOP_HOME/conf/slaves�ļ��������¼ӽڵ����������ٽ������¼ӽڵ��������SSH����
�����������
start-all.sh
Ȼ�����ͨ��http://(Masternode��������):50070�鿴�����ӵ�DataNode
2.2�����ؾ���
start-balancer.sh������ʹDataNode�ڵ���ѡ���������ƽ��DataNode�ϵ����ݿ�ķֲ�
������:��������ʱ���Ȳ鿴logs�����а�����
3��java ����hdfs��Ⱥ
���https://my.oschina.net/zss1993/blog/1574505
https://gitee.com/MaxBill/hadoop/blob/master/src/main/java/com/maxbill/hadoop/hdfs/HdfsUtils.java
http://blog.51cto.com/jaydenwang/1842908
ǰ����ú�hadoop��Ⱥ
#HDFS�������
hdfs.defaultfs=fs.defaultFS
hdfs.host=hdfs://192.168.23.137:8020
hdfs.uploadPath=/user/hadoop/
package jit.hf.agriculture.util;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.io.InputStream;
import java.net.URI;
/**
* @Auther: zj
* @Date: 2018/10/30 12:54
* @Description: hdfs������
*/
@Component
public class HdfsUtils {
@Value( "${hdfs.uploadPath}" )
private String userPath;
@Value( "${hdfs.host}" )
private String hdfsPath;
public void test1(){
System.out.println( userPath);
System.out.println( hdfsPath );
}
/**
* @���� ��ȡHDFS������Ϣ
* @return
*/
private Configuration getHdfsConfig() {
Configuration config = new Configuration();
return config;
}
/**
* @���� ��ȡFS����
*/
private FileSystem getFileSystem() throws Exception {
//�ͻ���ȥ����hdfsʱ������һ���û����ݵ�,Ĭ������£�hdfs�ͻ���api���jvm�л�ȡһ����������Ϊ�Լ����û����ݣ�-DHADOOP_USER_NAME=hadoop
//FileSystem hdfs = FileSystem.get(getHdfsConfig());
//Ҳ�����ڹ���ͻ���fs����ʱ��ͨ���������ݽ�ȥ
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), getHdfsConfig(), "hadoop");
return hdfs;
}
/**
* �ݹ鴴��Ŀ¼
*
*/
public void mkdir(String path) throws Exception {
FileSystem fs = getFileSystem();
Path srcPath = new Path(path);
boolean isOk = fs.mkdirs(srcPath);
if (isOk) {
System.out.println("create dir success...");
} else {
System.out.println("create dir failure...");
}
fs.close();
}
/**
* ��HDFS�����ļ��������ļ��������
*/
public void createFile(String filePath, byte[] files){
try {
FileSystem fs = getFileSystem();
//Ŀ��·��
Path path = new Path( filePath );
//��һ�������
FSDataOutputStream outputStream = fs.create( path );
outputStream.write( files );
outputStream.close();
fs.close();
System.out.println( "�����ļ��ɹ���" );
} catch (Exception e) {
System.out.println( "�����ļ�ʧ�ܣ�" );
}
}
/**
* ��ȡHDFS�ļ�����
*/
public void readFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
Path path = new Path(filePath);
InputStream in = null;
try {
in = fs.open(path);
//���Ƶ��������
IOUtils.copyBytes(in, System.out, 4096, false);
System.out.println( "\n��ȡ�ļ��ɹ���" );
} catch (Exception e) {
System.out.println( "\n��ȡ�ļ�ʧ�ܣ�" );
}
finally
{
IOUtils.closeStream(in);
}
}
/**
* ��ȡHDFSĿ¼��ϸ��Ϣ
*/
public void pathInfo(String filePath) throws Exception {
FileSystem fs = getFileSystem();
FileStatus[] listStatus = fs.listStatus(new Path(filePath));
for (FileStatus fileStatus : listStatus) {
System.out.println(fileStatus.getPath() + ">>>>>" + fileStatus.toString());
}
}
/**
* ��ȡHDFS�ļ��б�
*/
public void listFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
//�ݹ��ҵ����е��ļ�
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path(filePath), true);
while (listFiles.hasNext()) {
LocatedFileStatus next = listFiles.next();
String name = next.getPath().getName();
Path path = next.getPath();
System.out.println(name + "---" + path.toString());
}
}
/**
* �ļ�������
*/
public void renameFile(String oldName, String newName) throws Exception {
FileSystem fs = getFileSystem();
Path oldPath = new Path(oldName);
Path newPath = new Path(newName);
boolean isOk = fs.rename(oldPath, newPath);
if (isOk) {
System.out.println("rename success...");
} else {
System.out.println("rename failure...");
}
fs.close();
}
/**
* ɾ��ָ���ļ�
*/
public void deleteFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
Path path = new Path(filePath);
boolean isOk = fs.deleteOnExit(path);
if (isOk) {
System.out.println("delete success...");
} else {
System.out.println("delete failure...");
}
fs.close();
}
/**
* �ϴ��ļ�
*/
public void uploadFile(String fileName, String uploadPath) throws Exception {
FileSystem fs = getFileSystem();
//�ϴ�·��
Path clientPath = new Path(fileName);
//Ŀ��·��
Path serverPath = new Path(uploadPath);
//�����ļ�ϵͳ���ļ����Ʒ���,ǰ�������ָ�Ƿ�ɾ��ԭ�ļ���trueΪɾ����Ĭ��Ϊfalse
fs.copyFromLocalFile(false, clientPath, serverPath);
fs.close();
System.out.println( "�ϴ��ļ��ɹ���" );
}
/**
* �����ļ�
*/
public void downloadFile(String fileName, String downPath) throws Exception {
FileSystem fs = getFileSystem();
fs.copyToLocalFile(new Path(fileName), new Path(downPath));
fs.close();
System.out.println( "�����ļ��ɹ���" );
}
/**
* �ж��ļ��Ƿ����
*/
public boolean existFile(String FileName) throws Exception {
FileSystem hdfs = getFileSystem();
Path path = new Path(FileName);
boolean isExists = hdfs.exists(path);
return isExists;
}
}
package jit.hf.agriculture.controller;
import jit.hf.agriculture.util.HdfsUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* @Auther: zj
* @Date: 2018/10/30 12:52
* @Description:
*/
@RestController
public class HdfsController {
@Autowired
private HdfsUtils hdfsUtils;
//���������ļ�ע���Ƿ���Ч
@GetMapping("/hdfs/test1")
public void HdfsTest1(){
hdfsUtils.test1();
}
/**
* hdfs ����Ŀ¼
*
* ��������- - -
* dir: aaa
*/
@PostMapping("/hdfs/mkdir")
public void HdfsMkdir(@RequestParam("dir") String path) throws Exception {
hdfsUtils.mkdir( path );
}
/**
* ��HDFS�����ļ��������ļ��������
*
* ��������- - -
* filepath: aaa/a.text
* content: hello world
*/
@PostMapping("/hdfs/vim")
public void HdfsVim(@RequestParam("filepath") String filepath,
@RequestParam(value = "content",required=false,defaultValue = "") String content
) throws Exception {
hdfsUtils.createFile( filepath,content.getBytes() );
}
/**
* ��ȡHDFS�ļ�����,cat
* @param filepath
* @throws Exception
*
* ��������- - -
*filepath: aaa/a.text
*/
@GetMapping("hdfs/cat")
public void HdfsCat(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.readFile( filepath );
}
/**
* ��ʾHDFSĿ¼��ϸ��Ϣ(����Ŀ¼�µ��ļ�����Ŀ¼)
* @param filepath
* @throws Exception
*
* ��������- - -
* filepath:aaa
*/
@GetMapping("hdfs/catdir")
public void HdfsAndCatDir(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.pathInfo( filepath );
}
/**
* ��ȡhdfs ָ��Ŀ¼�µ��ļ��б�
* @param filepath
* @throws Exception
*
* ��������- - -
* filepath:aaa
*/
@GetMapping("hdfs/ls")
public void HdfsLs(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.listFile( filepath );
}
/**
* �ļ�������
*
* ��������- - -
* oldName:aaa/b.text
* newName:aaa/c.text
*/
@PostMapping("hdfs/renameFile")
public void HdfsRenameFile(@RequestParam("oldName") String oldName,
@RequestParam("newName") String newName) throws Exception {
hdfsUtils.renameFile( oldName,newName );
}
/**
* ɾ��ָ���ļ�
* @param filepath
* @throws Exception
*
* ��������
* filepath:aaa/c.text
*/
@GetMapping("hdfs/deleteFile")
public void HdfsDeleteFile(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.deleteFile( filepath );
}
/**
* �ϴ��ļ�
* @param fileName
* @param uploadFile
* @throws Exception
*
* ��������
*
* fileName: C:\\Users\\zj\\Desktop\\hello.txt
* uploadName:aaa
*/
@PostMapping("hdfs/uploadFile")
public void UploadFile(@RequestParam("fileName") String fileName,
@RequestParam("uploadFile") String uploadFile) throws Exception {
hdfsUtils.uploadFile( fileName,uploadFile );
}
/**
* �����ļ�
* @param fileName
* @param downPath
* @throws Exception
*
* ��������
* fileName:aaa/hello.txt
* downPath:C:\\
*/
@PostMapping("hdfs/downloadFile")
public void DownloadFile(@RequestParam("fileName") String fileName,
@RequestParam("downPath") String downPath) throws Exception {
hdfsUtils.downloadFile( fileName, downPath);
}
/**
* �ж��ļ��Ƿ����
*
* ��������
*
*/
@GetMapping("hdfs/existFile")
public void ExistFile(@RequestParam("fileName") String filName) throws Exception {
hdfsUtils.existFile( filName );
}
}
����������https://blog.csdn.net/ycf921244819/article/details/81706119
https://www.cnblogs.com/huxinga/p/6875929.html
��������ϵ�hadoop-2.8.5��ѹ��windows��
�ŵ�c:/agricultureĿ¼��
����
public class AgricultureApplication {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "C:\\agriculture\\hadoop-2.8.5");
SpringApplication.run(AgricultureApplication.class, args);
}
}
��Ҫ����winutils.exe hadoop.dll���������hadoop��װĿ¼��bin���С����ص�ַ��https://github.com/srccodes/hadoop-common-2.2.0-bin
��Ȼ��2.2.0�ģ������ײ��Կ��õġ�������Ͻ�ѹ���������bin�����ȫ�����ƣ�Ȼ����hadoop��װĿ¼��bin���У��������ͬ���滻�������ˡ�
���
����һ������
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
����ɲο�https://www.cnblogs.com/kevinq/p/5103653.html
�����û��


���������
https://blog.csdn.net/looc_246437/article/details/77480312
��hdfsUtils�����ӣ�
/**
* ��ȡHDFS��Ⱥ�����нڵ�������Ϣ
* @throws Exception
*/
public void getListNode() throws Exception {
FileSystem fs = getFileSystem();
DistributedFileSystem hdfs = (DistributedFileSystem)fs;
DatanodeInfo[] dataNodeStats = hdfs.getDataNodeStats();
for(int i=0;i<dataNodeStats.length;i++){
System.out.println("DataNode_"+i+"_Name:"+dataNodeStats[i].getHostName());
}
��hdfscontroller�����ӣ�
/**
* ��ȡHDFS��Ⱥ�����нڵ�������Ϣ
* @throws Exception
*/
@GetMapping("hdfs/getListNode")
public void HdfsGetListNode() throws Exception {
hdfsUtils.getListNode();
}
���ԣ�
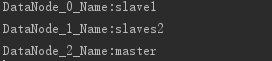
�������Ǽ�Ⱥ