1、HDFS 命令行操作
1.1、基本语法
bin/hadoop fs 具体命令
1.2、参数大全
通过命令bin/hadoop fs查看
1.3、常用操作命令
1)、启动 Hadoop 集群:

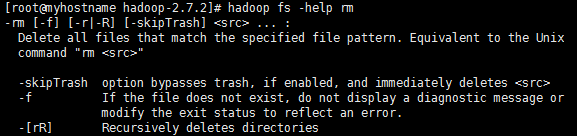
2)、-help:输出这个命令参数
3)、-ls: 显示目录信息

4)、-mkdir:在 hdfs 上创建目录

5)、-moveFromLocal 从本地剪切粘贴到 hdfs
touch abc.txt
hadoop fs -moveFromLocal abc.txt /user/root/test
6)、--appendToFile :追加一个文件到已经存在的文件末尾
touch ximen.txt
vi ximen.txt
hadoop fs -appendToFile ximen.txt /user/root/test/abc.txt
7)、-cat :显示文件内容
8)、-tail:显示一个文件的末尾
9)、-chgrp 、-chmod、-chown:linux 文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /user/root/test/abc.txt
10)、-copyFromLocal:从本地文件系统中拷贝文件到 hdfs 路径去
hadoop fs -copyFromLocal README.txt /user/root/test
11)、-copyToLocal:从 hdfs 拷贝到本地
hadoop fs -copyToLocal /user/root/test/jinlian.txt ./abc.txt
12)、-cp :从 hdfs 的一个路径拷贝到 hdfs 的另一个路径
hadoop fs -cp /user/root/test/abc.txt /abc2.txt
13)、-mv:在 hdfs 目录中移动文件
hadoop fs -mv /abc2.txt /user/root/test/
14)、-get:等同于 copyToLocal,就是从 hdfs 下载文件到本地
hadoop fs -get /user/root/test/abc2.txt ./
15)、-getmerge :合并下载多个文件,比如 hdfs 的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /user/root/test/* ./zaiyiqi.txt
16)、-put:等同于 copyFromLocal
hadoop fs -put ./zaiyiqi.txt /user/root/test/
17)、-rm:删除文件或文件夹
hadoop fs -rm /user/root/test/abc2.txt
18)、-rmdir:删除空目录
hadoop fs -mkdir /test
hadoop fs -rmdir /test
19)、-df :统计文件系统的可用空间信息
hadoop fs -df -h /
20)、-du 统计文件夹的大小信息
hadoop fs -du -s -h /user/root/test 2.7 K /user/root/test
hadoop fs -du -h /user/root/test
21)、-setrep:设置 hdfs 中文件的副本数量
hadoop fs -setrep 2 /user/root/test/abc.txt
2、HDFS 客户端操作
2.1、HDFS 客户端环境准备
jar包准备:
1)解压 hadoop-2.7.2.tar.gz 到非中文目录 。
2)进入 share 文件夹,查找所有 jar 包,并把 jar 包拷贝到_lib 文件夹下 。
3)在全部 jar 包中查找 *sources.jar,并剪切到_source 文件夹。
4)在全部 jar 包中查找 *tests.jar,并剪切到_test 文件夹。
eclipse 准备:
1)、解压自己电脑编译后的hadoop jar包到目录D:\soft\hadoop-2.7.2。
2)、配置 HADOOP_HOME 环境变量
HADOOP_HOME D:\soft\hadoop-2.7.2
PATH %HADOOP_HOME%\bin
3)、创建第一个 java 工程 HdfsClientDemo1
4)、创建 lib 文件夹,然后添加 jar 包
5)、创建包名:com.test.hdfs
6)、创建 HdfsClient 类

注:当我们走公网ip 访问namenode 的时候,可以得到相应的datanode 的注册信息。于是通过对应的注册信息进行访问,但是此时datanode 向namenode 注册的是内网的ip 因为远程访问的机器和hdfs 的机器不在一个内网集群 ,所以会导致虽然有一个datanode 但是没有可用节点。
解决方法在远程调用的相应的配置中加入configuration.set("dfs.client.use.datanode.hostname","true");
使用hostname 进行访问同时在hosts 文件中配置对应的主机名和公网ip 的映射,即可远程成功调用hdfs。
2.2、通过 API 操作 HDFS
1)、HDFS 获取文件系统

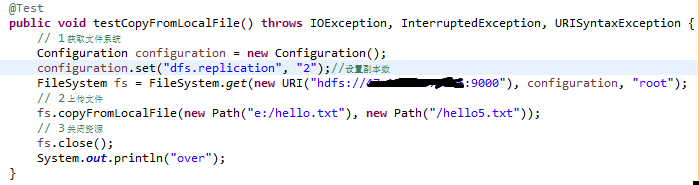
2)、HDFS 文件上传
3)、HDFS 文件下载

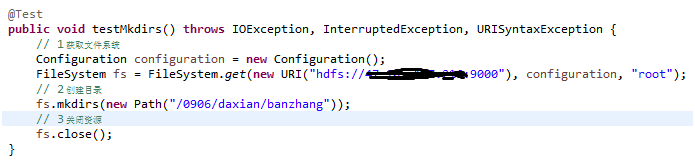
4)、HDFS 目录创建
5)、HDFS 文件夹删除
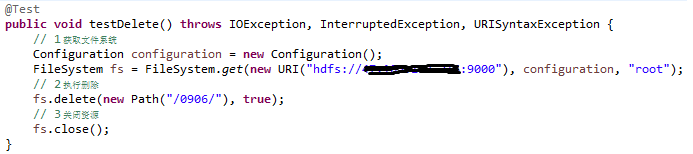
6)、HDFS 文件名更改
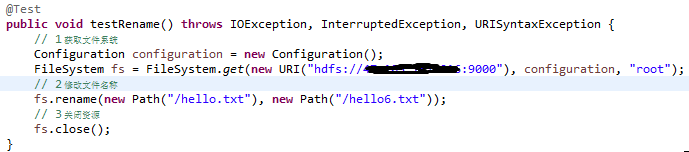
7)、HDFS 文件详情查看(查看文件名称、权限、长度、块信息)

8)、HDFS 文件和文件夹判断

2.3、通过 IO 流操作 HDFS
1)、HDFS 文件上传

2)、HDFS 文件下载

3)、定位文件读取
下载第一块:

下载第二块:

合并文件:
在 window 命令窗口中执行 type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1