版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bocai8058/article/details/82634936
@Author : Spinach | GHB
@Link : http://blog.csdn.net/bocai8058
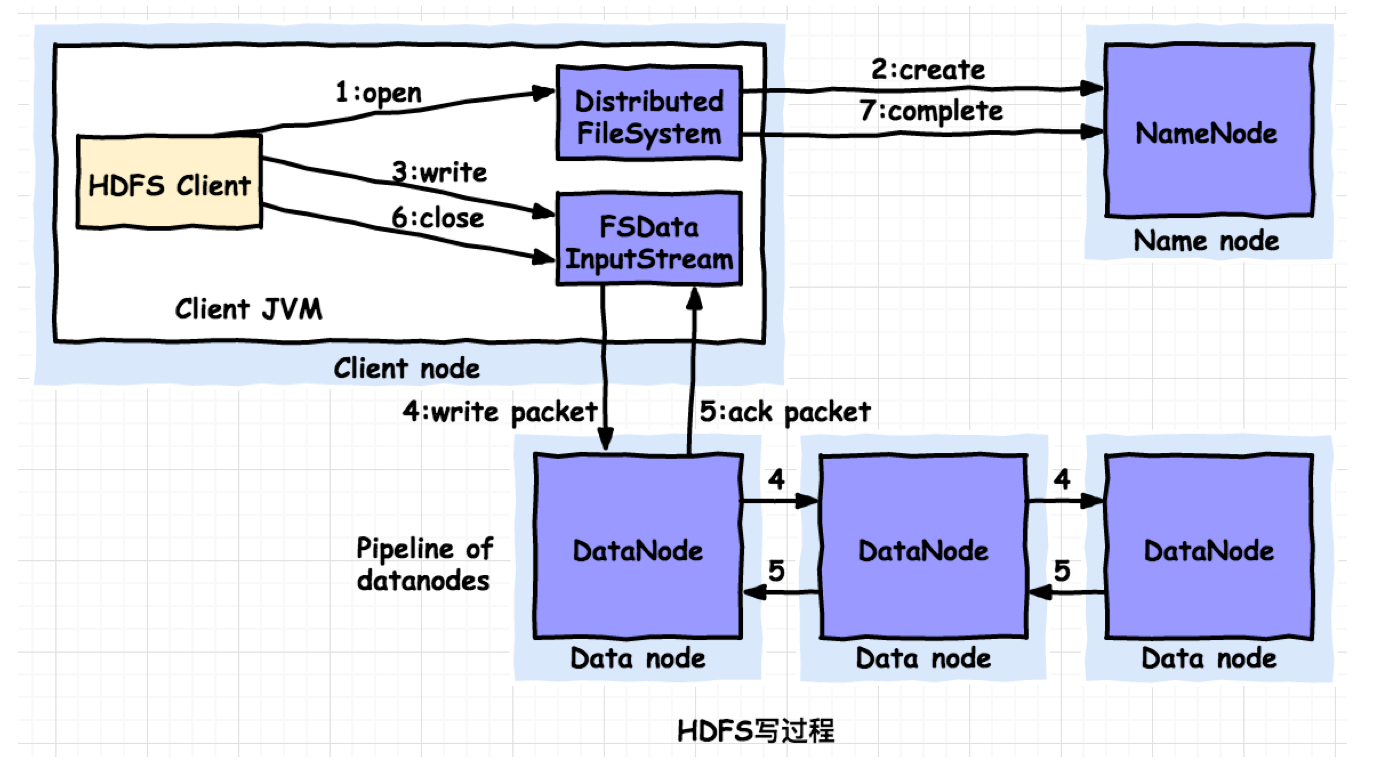
HDFS写(上传)过程
写(上传)流程
- 客户端(Client)向namenode发起RPC请求上传文件,namenode检查文件是否存在,创建者是否有权限进行操作,成功则会为文件创建一个记录edits, 否则会让客户端抛出异常;
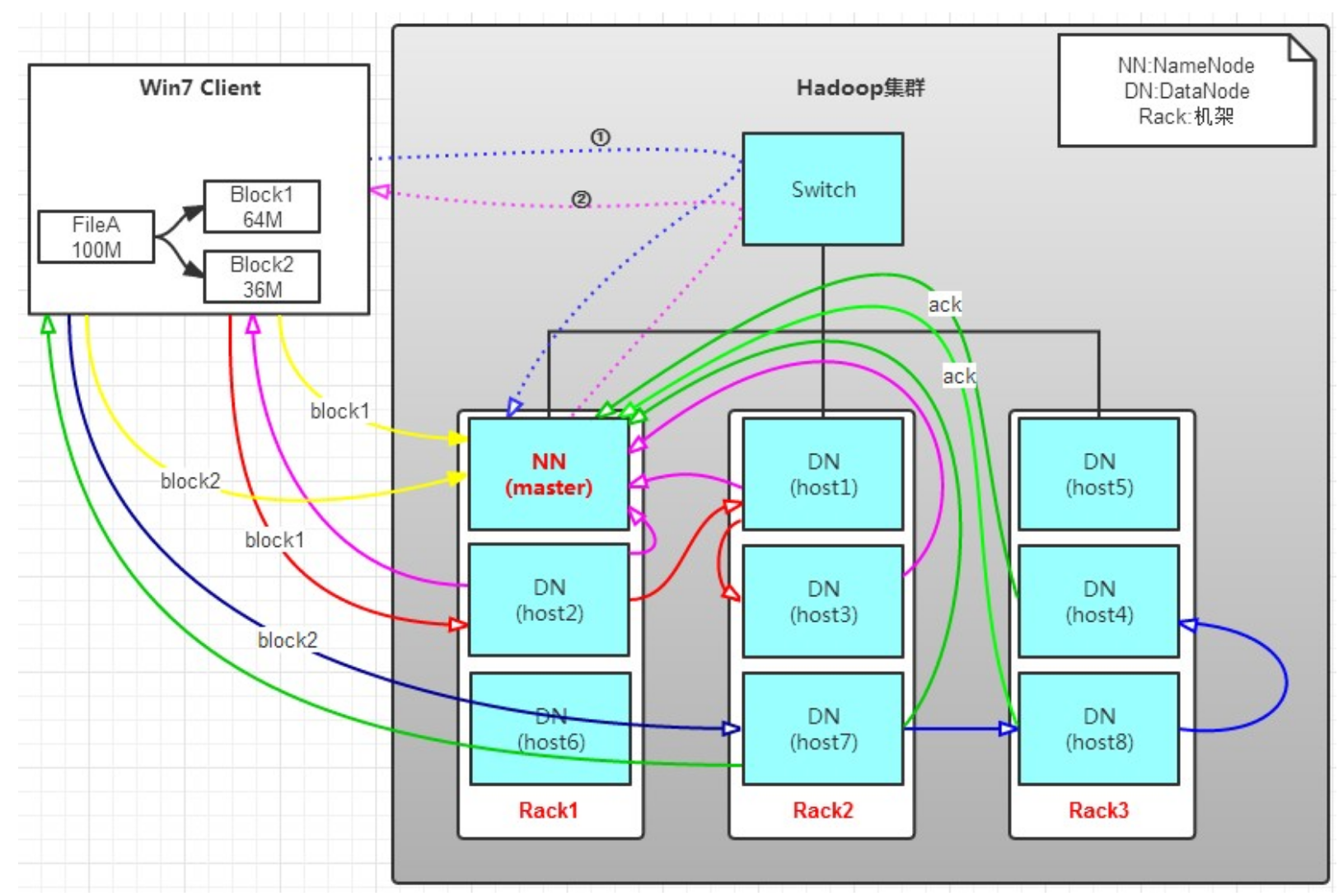
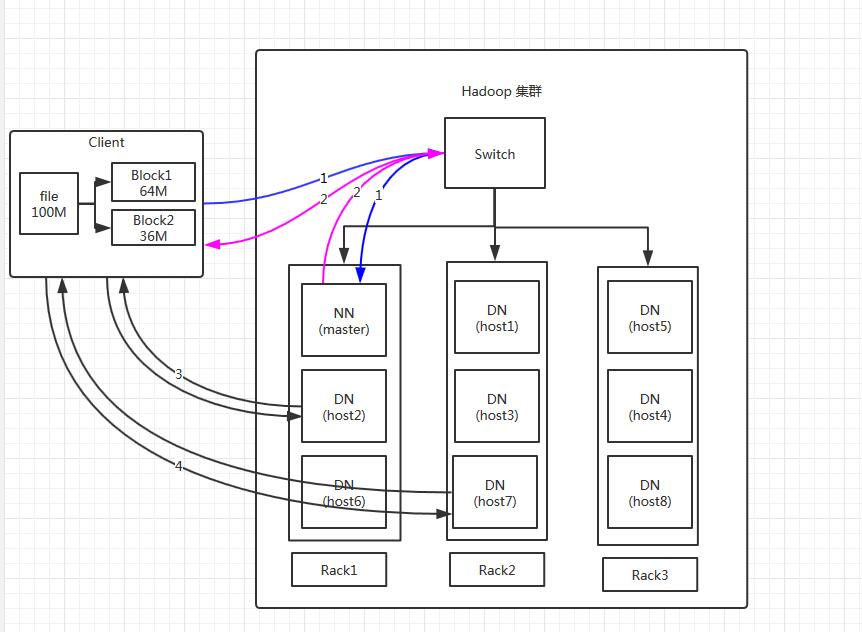
- Client将File进行分块,如block1(128MB)、block2(65MB)。Client向namenodee请求第一个block1 128MB该传输到哪个DataNode服务器;
- namenode返回第一个block1需要传输到的3个(由于副本为3)datanode的信息;
- block1是由多个packets为单位组成的,并在内部以数据队列“data queue(数据队列)”的形式管理这些packets;
- Client请求第一台datanode1(本质上就是RPC调用,建立pipeline),datanode1收到请求会继续调用datanode2,datanode2收到继续调用datanode3,建立pipeline完成,逐步返回给Client;
- Client开始上传File的block1(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(一个packet为64kb)写入,并对数据进行校验,并不是一个packet进行一次校验而是以hunk为单位(512byte),datanode1收到第一个packet会以pipeline形式传给datanode2,datanode2传给datanode3;
- 最后一个datanode3成功存储之后会返回一个ack packet(确认队列),在pipeline里传递至客户端,在客户端的开发库内部维护着“ack queue”,成功收到datanode返回的ack packet后会从“ack queue”移除相应的packet。
- 每个成功的datanode还要向namenode发送通知,进行edits更新;
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode, 保持replications设定的数量。
- 客户端完成数据的写入后,会对数据流调用close()方法,关闭数据流;
写(上传)代码实现流程
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test.txt");
FSDataOutputStream outStream = fs.create(file);
outStream.writeUTF("Welcome to HDFS Java API!!!");
outStream.close();
- 初始化FileSystem,客户端调用create()来创建文件;
- FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
- DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
- 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
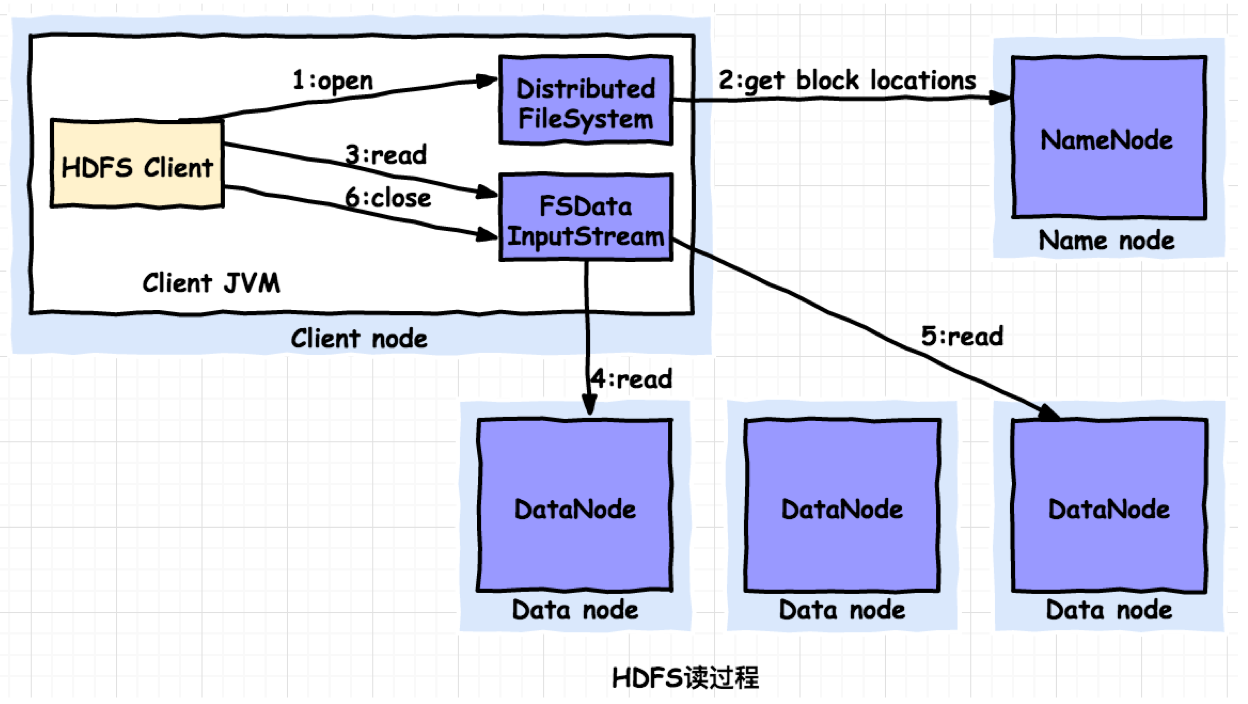
HDFS读(下载)过程
读(下载)流程
- Client向namenode发送读取请求;
- namenode查看Metadata信息,确认文件存在且用户对其有访问权限,namenode 会告诉client 这个文件的第一块数据块的标号和保存该数据块的datanode列表(这个列表是按照datanode与Client距离进行了排序);
- Client根据返回的信息找到相应的datanode,逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
读(下载)代码实现流程
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test.txt");
FSDataInputStream inStream = fs.open(file);
String data = inStream.readUTF();
System.out.println(data);
inStream.close();
- 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
- FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。【注意:这里的序号不是一一对应的关系】
- 同样DFSInputStream也会通过校验和确定datanode发来的数据是否完整,如果发现有损失的块,就在DFSInputStream试图从其他datanode读取其副本之前通知namenode。
(这个设计的一个重点是,namenode告知客户端每个块中最佳的datanode,并让客户端直接连接到该datanode检索数据。由于数据流分散在集群中的所有datanode,所以这种设计能使HDFS可扩展到大量的并发客户端。同时,namenode 只需要响应块设置的请求(这些信息存储在内存中,因而非常高效),无需响应数据请求,否则随着客户端数量的增长,namenode会很快成为瓶颈。)