版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Lin_wj1995/article/details/52169019
一、不多说,按照惯例,先贴代码
还是建议粘贴到自己的eclipse中查看
package com.Lin_wj1995.bigdata.hdfs;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClient {
FileSystem fs = null;
/**
* 初始化FileSystem
*/
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
/**
* 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
*/
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop");
}
/**
* 从hdfs中复制文件到本地文件系统
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"), new Path("d:/"));
fs.close();
}
}
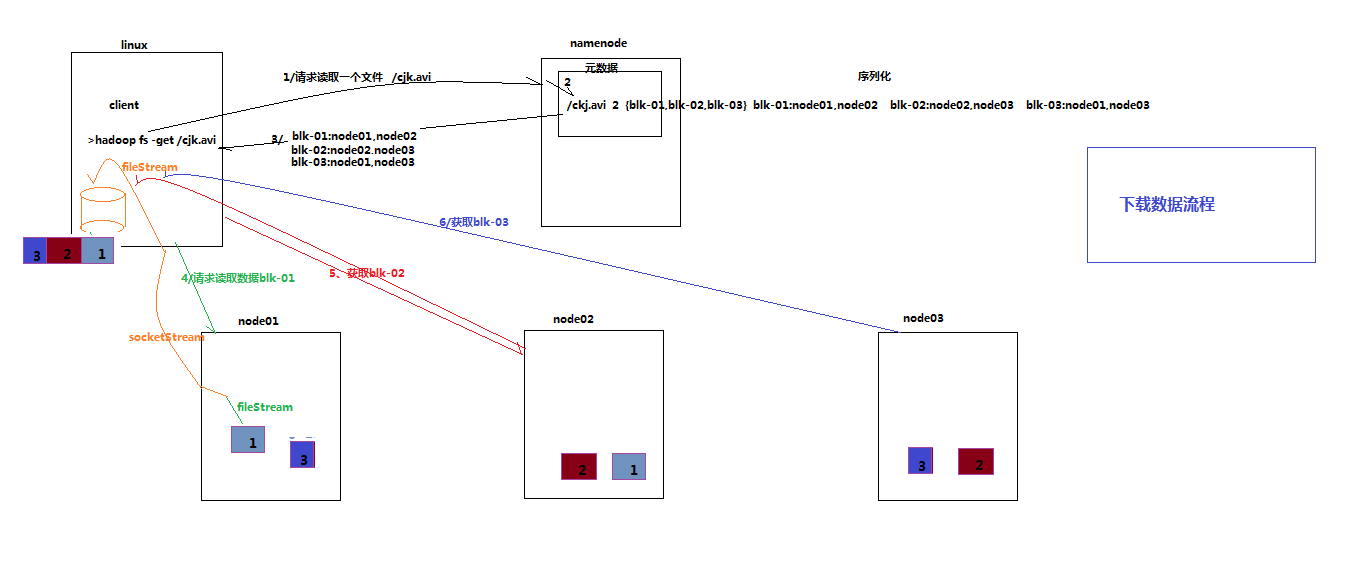
二、原理讲解
- 首先客户端会跟namenode说我要拿取哪个目录下的哪个文件,比如是/hadoop/hdfs/目录下的cjk.avi文件
- namenode就会去元数据池中查找这个文件对应的各个block块,以及各个block块的位置信息(哪个datanode),然后将这些信息发给客户端
- 客户端拿到信息后,就会去各个节点拿取每一块block,然后将数据拉取到本地
- 接下来在client客户端本地对这些block块进行合并,这样就得到一个完整的文件了
三、原理图解