Hadoop�ֲ�ʽ
��һ���Ӵ�����ݻ��ӵ�ҵ��ַ�����ͬ�ļ�����ڵ������������л�����
- Hadoop��˼��֮Դ��������Google 03�귢��3�����ģ� GFS��mapreduce�� Bigtable ��Dougcutting��Javaʵ��)
- ���壺hadoop1=hdfs1+mr1
hadoop2=hdfs2+mr2+yarn
- hadoop ��̬

�ֲ�ʽ�ļ��洢ϵͳHDFS
��ȱ��
- �ŵ㣺
�ֲ�ʽ���ԣ�
- �ʺϴ����ݴ�����GB ��TB ������PB �������ϵ�����
- �����ģ���ϵ��ļ�����:10K+ �ڵ㡣��1�����ڵ㣨����������
- �ʺ����������ƶ������������(MR),����λ�ñ�¶��������
�������ԣ�
- �ɹ��������ۻ����ϣ�
- �߿ɿ���:ͨ���ั�������
- ���ݴ��ԣ������Զ�������������������ʧ���Զ��ָ�,�ṩ�˻ָ�����
- ȱ�㣺
- ���ӳٸ��������·�������
���粻֧�ֺ��뼶
�������������������ӳ�
- С�ļ���ȡռ��NameNode�����ڴ棨Ѱ��ʱ�䳬����ȡʱ�䣨99%����
- ��֧���ļ��ģ�һ���ļ�ֻ����һ��д�ߣ����룩
��֧��append��֧���ģ���ʵ������֧�ֵģ���ҪΪ�˿ռ任ʱ�䣬��Լ�ɱ���
HDFS�ܹ�ͼ:
namenode��datanode֮���У��������ơ����ؾ��⡢�ั��

HDFS ���ݴ洢ģ�� block
- �ļ��������зֳɹ̶���С�����ݿ�block
ͨ��ƫ����offset����λ��byte�����
Ĭ�����ݿ��СΪ64MB (hadoop1.x)�����Զ�������
���ļ���С����64MB �������һ��block
- һ���ļ��洢��ʽ
����С���зֳ����ɸ�block ���洢����ͬ�ڵ���
Ĭ�������ÿ��block����2������ ��3������
�����������ڽڵ���
- Block��С������ͨ��Client���ϴ��ļ�ʱ���ã��ļ��ϴ��ɹ��������Ա����Block Size��С���ɱ��
nameNode(NN)
- NameNode��Ҫ���ܣ�
1�����ܿͻ��˵Ķ�/д����
2������DN�㱨��blockλ����Ϣ��
- NameNode����metadateԪ��Ϣ��
�����ڴ�洢 ������ʹ��̷�������;
metadateԪ������Ϣ�������£�
�ļ�owership(����)��permissions(Ȩ��)
�ļ���С ʱ��
Block�б�[ƫ����]����һ�������ļ�����Щblock��b0+b1+b2+��=file��
λ����Ϣ=Blockÿ�������������ĸ�DataNode�У���DataNode����ʱ�ϱ���NN ��Ϊ����ʱ�仯,�������ڴ��̣��C��̬��!
- NameNode��metadate��Ϣ�����������ص��ڴ�
metadata�洢�������ļ���Ϊ��fsimage���ľ����ļ�
Block��λ����Ϣ���ᱣ�浽fsimage
edits��¼��metadata�IJ�����־
secondaryNameNode(SNN)
- ������Ҫ�����ǰ���NN�ϲ�edits log�ļ����ڴ��е�Ԫ���ݣ���ص������γ�fsimage.����NN����ʱ��,������NN�ı��ݣ�������������)��
- SNNִ�кϲ�ʱ��ͻ���
A�����������ļ����õ�ʱ����fs.checkpoint.period Ĭ��3600��
B�����������ļ�����edits log��С fs.checkpoint.size �涨edits�ļ������ֵĬ����64MB
SecondaryNameNode SNN�ϲ�����

DataNode��DN��
- �洢���ݣ�Block��
- ����DN�̵߳�ʱ�����NameNode�㱨blockλ����Ϣ
- ͨ����NN������������������ϵ��3��һ�Σ������NN 10����û���յ�DN������������Ϊ���Ѿ�lost����copy���ϵ�block������DN
Block�ĸ������ò���
- ��һ����������Ⱥ�ڲ��ύ�������ϴ��ļ���DN������Ǽ�Ⱥ���ύ���������ѡһ̨���̲�̫����CPU��̫æ�Ľڵ㡣
- �ڶ����������������ڵ�һ��������ͬ�Ļ��ܵĽڵ��ϡ�
- ��������������ڶ���������ͬ���ܵIJ�ͬ�ڵ㡣
- ���ั��������ڵ�
HDFS���ļ�����

- ���ȵ���FileSystem�����open��������ʵ��һ��DistributedFileSystem��ʵ����
- DistributedFileSystemͨ��rpcЭ�����ļ��ĵ�һ��block��locations��ַ����ͬһ��block�����ظ����᷵�ض��locations����Ϊͬһ�ļ���block�ֲ�ʽ�洢�ڲ�ͬ�ڵ��ϣ�����Щlocations����hadoop���˽ṹ������ͻ��˽�������ǰ�棨�ͽ�ԭ��ѡ��
- ǰ�����᷵��һ��FSDataInputStream���ö���ᱻ��װDFSInputStream����DFSInputStream���Է���Ĺ���datanode��namenode���������ͻ��˵���read������DFSInputStream����ҳ���ͻ��������datanode�����ӡ�
- ���ݴ�datanodeԴԴ���ϵ�����ͻ��ˡ�
��Щ�����Կͻ�����˵�����ģ��ͻ��˵ĽǶȿ���ֻ�Ƕ�һ���������ϵ�����
- �����һ��block�������ˣ� DFSInputStream�ͻ�ȥnamenode����һ��block��locations��Ȼ���������������еĿ鶼���꣬��ʱ�ͻ�رյ����е�����
����ڶ����ݵ�ʱ�� DFSInputStream��datanode��ͨѶ�����쳣���ͻ᳢�����ڶ���block������ڶ�����datanode,���һ��¼�ĸ�datanode��������ʣ���blocks����ʱ��ͻ�ֱ��������datanode�� DFSInputStreamҲ����block����У��ͣ��������һ������block,�ͻ��ȱ��浽namenode�ڵ㣬Ȼ��DFSInputStream��������datanode�϶���block�ľ���
����ƾ��ǿͻ���ֱ������datanode���������ݲ���namenode������Ϊÿһ��block�ṩ���ŵ�datanode�� namenode��������block location��������Щ��Ϣ��������namenode���ڴ��У�hdfsͨ��datanode��Ⱥ���Գ��ܴ����ͻ��˵IJ������ʡ�
RPC��Remote Procedure Call Protocol������Զ�̹��̵���Э�飬����һ��ͨ�������Զ�̼���������������������Ҫ�˽�ײ����缼����Э�顣RPCЭ��ٶ�ijЩ����Э��Ĵ��ڣ���TCP��UDP��Ϊͨ�ų���֮��Я����Ϣ���ݡ���OSI����ͨ��ģ���У�RPC��Խ�˴�����Ӧ�ò㡣RPCʹ�ÿ�����������ֲ�ʽ��������ڵ�Ӧ�ó���������ס�
RPC���ÿͻ���/������ģʽ������������һ���ͻ������������ṩ�������һ�������������ȣ��ͻ������ý��̷���һ���н��̲����ĵ�����Ϣ��������̣�Ȼ��ȴ�Ӧ����Ϣ���ڷ������ˣ����̱���˯��״ֱ̬��������Ϣ����Ϊֹ����һ��������Ϣ�����������ý��̲����������������ʹ���Ϣ��Ȼ��ȴ���һ��������Ϣ����ͻ��˵��ý��̽��մ���Ϣ����ý��̽����Ȼ�����ִ�м������С�
HDFSд�ļ�����

- �ͻ���ͨ������DistributedFileSystem��create�����������ļ���
- DistributedFileSystemͨ��RPC����namenodeȥ����һ��û��blocks���������ļ�������ǰ�� namenode��������У�飬�����ļ��Ƿ���ڣ��ͻ�������Ȩ��ȥ�����ȡ����У��ͨ���� namenode�ͻ��¼�����ļ�������ͻ��׳�IO�쳣��
- ǰ���������᷵��FSDataOutputStream�Ķ�������ļ���ʱ�����ƣ�FSDataOutputStream����װ��DFSOutputStream��
DFSOutputStream����Э��namenode��datanode���ͻ��˿�ʼд���ݵ�DFSOutputStream��DFSOutputStream��������г�һ����С��packet��Ȼ���ųɶ���data quene��
- DataStreamer��ȥ��������data quene������ѯ��namenode����µ�block���ʺϴ洢�����ļ���datanode������ظ�����3����ô���ҵ�3�����ʺϵ�datanode�����������ų�һ���ܵ�pipeline�����DataStreamer��packet������������ܵ��ĵ�һ��datanode�У���һ��datanode�ְ�packet������ڶ���datanode�У��Դ����ơ�
- DFSOutputStream����һ�����н�ack quene��Ҳ����packet��ɵȴ�datanode���յ���Ӧ����pipeline�е�datanode����ʾ�Ѿ��յ����ݵ�ʱ����ʱack quene�Ż�Ѷ�Ӧ��packet���Ƴ����� �����д�Ĺ�����ij��datanode���������ȡ���¼�����
1) pipeline���رյ���
2)Ϊ�˷�ֹ��ֹ������ack quene���packet��ͬ����data quene��;�����µ�pipeline�ܵ�������������DN��
3)ʣ�µIJ��ֱ�д��ʣ�µ�����������datanode�У�
4)namenode�ҵ������datanodeȥ���������ĸ��ơ���Ȼ����Щ�����Կͻ�����˵����֪�ġ�
- �ͻ������д���ݺ����close�����ر�д������
PS:ע�⣺�ͻ���ִ��write������д���block���ǿɼ��ģ�����д��block�Կͻ����Dz��ɼ��ģ�ֻ�е���sync�������ͻ��˲�ȷ�����ļ���д�����Ѿ�ȫ����ɣ����ͻ��˵���close����ʱ����Ĭ�ϵ���sync�������Ƿ���Ҫ�ֶ�����ȡ������ݳ�����Ҫ�����ݽ�׳�Ժ�������֮���Ȩ�⡣
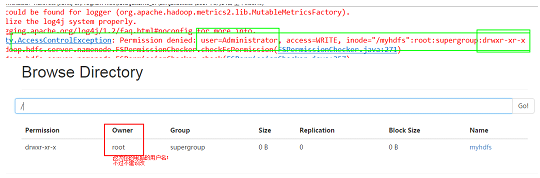
HDFS�ļ�Ȩ�Ͱ�ȫģʽ
- �ļ�Ȩ��
- ��Linux�ļ�Ȩ������ ��
r: read; w:write; x:execute��Ȩ��x�����ļ����ԣ������ļ��б�ʾ�Ƿ���������������
- ���Linuxϵͳ�û�zhangsanʹ��hadoop�����һ���ļ�����ô��� �ļ���HDFS��owner����zhangsan��
- HDFS��Ȩ��Ŀ�ģ���ֹ���������£���������ֹ���������¡�HDFS ���ţ������������˭���Ҿ���Ϊ����˭��
- ��ȫģʽ
- namenode������ʱ�����Ƚ�ӳ���ļ�(fsimage)�����ڴ棬��ִ�б༭��־(edits)�еĸ� �������
- һ�����ڴ��гɹ������ļ�ϵͳԪ���ݵ�ӳ�䣬��һ���µ�fsimage�ļ�(�����������ҪSecondaryNameNode)��һ���յı༭��־��
- �˿�namenode�����ڰ�ȫģʽ����namenode���ļ�ϵͳ���ڿͷ�����˵��ֻ���ġ�(��ʾ Ŀ¼����ʾ�ļ����ݵȡ�д��ɾ��������������ʧ��)��
- �ڴ˽�Namenode�ռ�����datanode�ı��棬�����ݿ�ﵽ��С����������ʱ���ᱻ��Ϊ�ǡ���ȫ���ģ� ��һ�������������ã������ݿ鱻ȷ��Ϊ����ȫ�����ٹ�����ʱ�䣬��ȫģʽ����
- ������������������ݿ�ʱ���ÿ�ᱻ����ֱ���ﵽ��С��������ϵͳ�����ݿ��λ �ò�������namenodeά���ģ������Կ��б���ʽ�洢��datanode�С�
PS:
��ȫ�ֲ�ʽ�
- ���ؽ�ѹ��Hadoop
- ����etc/hadoop/hadoop-env.sh
export JAVA_HOME=����JDK·����echo $JAVA_HOME���JDK·����
- core-site.xml:
fs.defaultFS Ĭ�ϵķ���˿�NameNode URI
hadoop.tmp.dir ��hadoop�ļ�ϵͳ�����Ļ������ã��ܶ�·���������������hdfs-site.xml�в��� ��namenode��datanode���ݵĴ��λ�ã�Ĭ�Ͼͷ������·����
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.5</value>
</property>
</configuration>
- hdfs-site.xml:
dfs.datanode.https.address https����Ķ˿�
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node02:50091</value>
</property>
</configuration>
- Masters: master ������������SNN
��/home/hadoop-2.6.5/etc/hadoop/�½�masters�ļ� д��SNN�ڵ����� node02
- Slaves: slave ū�� ��ɣ�ƴ������
��/home/hadoop-2.5.1/etc/hadoop/slaves�ļ�����дDN �ڵ�����node2 node3 node4 [ע�⣺ÿ��дһ�� д��3��]
- ������úõ�Hadoopͨ��SCP����Ͷ������ڵ�
����Hadoop�Ļ�������
- vi ~/.bash_profile (����������� ճ����ʱ������)
export HADOOP_HOME/home/hadoop-2.6.5
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
- �ǵ�һ��Ҫ source ~/.bash_profile
- �ص���Ŀ¼�¶�NN���и�ʽ�� hdfs namenode -format
- ����HDFS�� start-dfs.sh
- �رշ���ǽ��service iptables stop
����������� node1:50070
��datanode�ڵ���֤hadoop.tmp.dirĿ¼
ע�⣺HDFS��Ⱥ��clusterID��datanode����ʱ���namenode�Ա�clusterID�������ͬ�������ɹ��������ͬ����ɱ����
- hdfs dfs ���
hdfs dfs -du [-s][-h]URI[URI ��] ��ʾ�ļ�(��)��С.
hdfs dfs -mkdir[-p] ����
hdfs dfs -rm -r /myhadoop1.0 ɾ��
hdfs dfs -cp [-f][-p|-p[topax]]URI[URI��]�����ļ�(��)�����Ը��ǣ����Ա���ԭ��Ȩ����Ϣ
hdfs dfs -count [-q][-h]�г��ļ����������ļ����������ݴ�С.
hdfs dfs -chown [-R][OWNER][:[GROUP]]URI[URI] ��������.
hdfs dfs -chmod [-R]<MODE[,MODE]��|OCTALMODE>URI[URI ��] ��Ȩ��.
�ȵȡ�����������
- ���block�з� 1.*MB block��1MB�з֣�
for i in seq 100000;do echo ��hello sxt $i�� >> test.txt;done
hdfs dfs -D dfs.blocksize=1048576 -put test.txt /lm
eclipse�����װ����
��ѹeclipse���ѹ������eclipse-mars
������jar������eclipse��plugins�ļ�����
hadoop-eclipse-plugin-2.6.0.jar
����eclipse�����ֽ������£�

�½�Java��Ŀ��



 Eclipse�����װ�����windows�µ��û�����Ȼ��������
Eclipse�����װ�����windows�µ��û�����Ȼ��������
��ע�⣺�ij�Windows���û����û���root��������Ч�����Linux�ļ����û���
��

My����
3-1�������д
�½�Java��Ŀ����������Ҫ��jar��
hadoop�е�share\hadoop\hdfs
hadoop�е�share\hadoop\hdfs\lib
hadoop�е�share\hadoop\common
hadoop�е�share\hadoop\common\lib
�µ�jar����
block�ײ㡪offsetƫ��������ȡ�ֽ�����
private static void blk() throws Exception {
Path ifile = new Path("");
FileStatus file = fs.getFileStatus(ifile );
// ��ȡblock��location��Ϣ HDFS�ֲ�ʽ�ļ��洢ϵͳ������ƫ������λ����Ϣ����ȡ������
BlockLocation[] blk = fs.getFileBlockLocations(file , 0, file.getLen());
for (BlockLocation bb : blk) {
System.out.println(bb);
}
FSDataInputStream input = fs.open(ifile);
System.out.println((char)input.readByte());
System.out.println((char)input.readByte());
// ָ�����ĸ�offset��λ��ƫ��������
input.seek(1048576);
System.out.println((char)input.readByte());
input.seek(1048576);
System.out.println((char)input.readByte());
}