选择三台主机,一台启动namenode作为master,另外两台启动datanode作为node1、node2
安装java环境:http://blog.csdn.net/u011677067/article/details/79524466
下载hadoop(下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/)
1、修改主机名称及本地DNS解析
1)修改主机名
分别修改三台主机的/etc/hostname文件,修改为对应的名称(master、node1、node2),并重新启动;
或使用命令hostname master(node1、node2)。
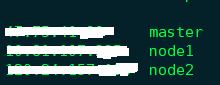
2)修改本地DNS解析
修改三台主机的/etc/hosts文件,并修改如下
2、增加用户
1)添加组
groupadd hadoop
2)增加组用户
useradd -s /bin/bash -d /home/hduser -m hduser -g hadoop
3)修改用户密码
passwd hduser
4)设置用户权限为admin
sudo adduser hduser sudo
5)切换用户
su hduser
3、设置ssh证书
设置无密码证书以便多台主机间连接
1)下载安装ssh
apt-get install ssh
apt-get install pdsh
/etc/init.d/ssh restart
2)生成无密码证书
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
3)连接测试
本地连接:ssh localhost
远程连接:将id_rsa.pub拷贝到远程主机上并追加到authorized_keys
如下,将master的公钥证书拷贝并添加到到node1的ssh证书中
scp /home/hduser/.ssh/id_rsa.pub hduser@node1:/home/hduser/.ssh/master_rsa.pub
cat ~/.ssh/master_rsa.pub >> ~/.ssh/authorized_keys
4、安装并设置环境
1)安装hadoop
将hadoop解压到/home/hduser/hadoop目录下
tar -zxvf hadoop-2.9.0.tar.gz
mvhadoop-2.9.0.tar.gz/home/hduser/hadoop
2)设置环境
修改~/.bashrc文件,添加如下内容:
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/home/hduser/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADDOP_HOME/lib/native
export PATH=$PATH:${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:${JAVA_HOME}/bin
5、配置hadoop
1)修改etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java
2)修改etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/hadoopdata/hdfs/tmp</value>
<description>A base for other temporary directories</description>
</property>
</configuration>
3)修改etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hduser/hadoopdata/hdfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hduser/hadoopdata/hdfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4)修改etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
5)修改etc/hadoop/slaves
node1
node2
6、运行hdfs集群
1)格式化Hadoop文件系统
hdfs namenode -format
2)启动文件系统:
start-dfs.sh
3)启动YARN:
start-yarn.sh
7、查看状态
1)查看HDFS状态,浏览器访问:http://master:50070
2)查看second namenode状态,浏览器访问:http://master:50090
1)查看datanode状态,浏览器访问:http://master:50075
1)查看HDFS状态,浏览器访问:http://master:50070
8、hdfs简单操作
创建目录:
hdfs dfs -mkdir /hdfsdata
上传文件到分布式系统
hdfs dfs -put /home/work/main.cpp /hdfsdata/main.cpp
查询hadoop的java库:
find /data/hadoop/share/ -name *.jar | awk '{printf("export CLASSPATH=%s:$CLASSPATH\n", $0);}'
参考:
Hadoop单机安装详细步骤
Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
初步掌握HDFS的架构及原理