Flume+Kafka+Storm+Redis������ʵ��wordcountʾ��
һ��ǰ��
���IJ���Flume��kafka��storm��redis��ʵ��һ���������wordcount��С������
��Ⱥ����Ϊserver01��server02��server03��
3̨������ͬʱִ���������ݵ�python�ű���Flume�IJɼ�����zookeeper��Ⱥ��kafka��Ⱥ
��server01������redis-server����
�����������ݵ�python�ű�
python�ű��ļ���produce_log2.py
����python3ʵ�֣����ǣ�ÿһ���list�����������ȡһ�����ݣ�д��/home/hadoop/log/access.log�ļ���
��server01��server02��server03�����ϴ���/home/hadoop/logĿ¼
mkdir -p /home/hadoop/log
������produce_log2.py�ű�����
import os
import time
import sched
import random
def create_log():
file = open("/home/hadoop/log/access.log", mode="a+", encoding='utf-8')
file.write(random.sample(list, 1)[0])
file.flush()
if __name__ == '__main__':
"""
python3.0 ��ʱִ������
"""
list = ['����� ������ �ν�\n', '����� ������ ¬����\n', '����� �Ƕ��� ����\n', '������ ������ ����ʤ\n', '������ �� ��ʤ\n', '������ ����ͷ �ֳ�\n',
'������ ������ ����\n', '������ ˫�� ������\n', '��Ӣ�� С��� ����\n', '����� С���� ���\n', '�츻�� ����� ��Ӧ\n', '�윺�� ���� ����\n',
'����� ������ ³����\n', '������ ���� ����\n', '������ ˫ǹ�� ��ƽ\n', '����� û��� ����\n', '�찵�� ������ ��־\n', '������ ��ǹ�� ����\n',
'����� ���ȷ� ����\n', '������ ����̫�� ����\n', '������ ��� ����\n', '��ɱ�� �\���� ����\n', '���� ������ ʷ��\n', '�쾿�� û���� �º�\n',
'������ ��Ợ ��\n', '������ �콭�� �\n', '�콣�� ����̫�� ��С��\n', '��ƽ�� ����� �ź�\n', '������ �������� ��С��\n', '������ ������� ��˳\n',
'����� ������ ��С��\n', '������ ������ ����\n', '����� ƴ������ ʯ��\n', '�챩�� ��ͷ�� ����\n', '����� ˫βЫ �ⱦ\n', '������ ���� ����\n',
'�ؿ��� �����ʦ ����\n', '��ɷ�� ����ɽ ����\n', '������ ��ξ�� ����\n', '�ؽ��� ���� ����\n', '������ ��ľ�� ��˼��\n', '������ ��ʤ�� ����\n',
'��Ӣ�� ��Ŀ�� ���^\n', '������ ʥˮ�� ��͢��\n', '������ ��� κ����\n', '������ ʥ������ ����\n', '������ �����Ŀ ����\n', '������ Ħ�ƽ�� ŷ��\n',
'������ ������ �˷�\n', '��ǿ�� ��ë�� ��˳\n', '�ذ��� ������ ����\n', '������ ������ ����\n', '�ػ��� ������ ����\n', '������ С�º� ����\n',
'������ ���ʹ� ��ʢ\n', '������ ��ҽ ����ȫ\n', '������ ���ײ� �ʸ���\n', '���� ���Ż� ��Ӣ\n', '�ػ��� һ���� ������\n', '�ر��� ɥ���� ����\n',
'��Ȼ�� ����ħ�� ����\n', '�ز��� ëͷ�� ����\n', '�ؿ��� ������ ����\n', '�ط��� �˱���߸ ���\n', '������ �����ʥ ����\n', '������ ��۽� ����\n',
'������ ������ ����\n', '�ؽ��� ������ ͯ��\n', '������ ������ ͯ��\n', '������ ��ᦸ� �Ͽ�\n', '������ ͨ��Գ �\n', '������ ������ �´�\n',
'������ ���� �\n', '������ �����ɾ� ֣����\n', '������ ��β�w ������\n', '�ؿ��� ������ ����\n', '������ ������ �ֺ�\n', '�ؽ��� ��� ����\n',
'������ �м��� ������\n', '������ С���� �´�\n', '����� �ٵ��� ����\n', '��ħ�� ������ ����\n', '������ ������ ��Ǩ\n', '������ ����� Ѧ��\n',
'��Ƨ�� �� ����\n', '�ؿ��� С���� ��ͨ\n', '�ع��� ��Ǯ���� ��¡\n', '��ȫ�� ������ ����\n', '�ض��� ������ ��Ԩ\n', '�ؽ��� ������ ����\n',
'������ ���غ��� ���\n', '���i�� Ц�滢 �츻\n', '�ط��� ���۱� ʩ��\n', '��ƽ�� ⟱۲� �̸�\n', '������ һ֦�� ����\n', '��ū�� �����й� ����\n',
'�ز��� ���ۻ� ����\n', '�ؐ��� û��Ŀ ��ͦ\n', '�س��� ʯ���� ʯ��\n', '������ Сξ�W ����\n', '������ ĸ��� �˴�ɩ\n', '������ ���� ����\n',
'��׳�� ĸҹ�� �����\n', '������ ������ ������\n', '�ؽ��� ꓵ��� ������\n', '�غ��� ������ ��ʤ\n', '������ ������ ʱǨ\n', '�ع��� ��ëȮ �ξ�ס\n']
schedule = sched.scheduler(time.time, time.sleep)
while True:
schedule.enter(1, 0, create_log)
schedule.run()
����ɵ�������
����Flume����
����/hadoop/flume/confĿ¼
cd /hadoop/flume/conf
����һ��flume-sink-kafka.conf�ļ������༭���������£�
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type=exec
a1.sources.s1.command=tail -F /home/hadoop/log/access.log
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
#����Kafka������
a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#����Kafka��broker��ַ�Ͷ˿ں�
a1.sinks.k1.brokerList=server01:9092,server02:9092,server03:9092
#����Kafka��Topic
a1.sinks.k1.topic=fksrtest
#�������л���ʽ
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder
a1.sinks.k1.requiredAcks = 1
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1
�ġ�kafka��ؼ�Ⱥ���������ⴴ��
4.1 ����zookeeper��Ⱥ
��ÿserver01��server02��server03����������zookeeper
zkServer.sh start
����zookeeper��Ⱥ����ο���Zookeeper��Ⱥ�����
4.2 ����kafka��Ⱥ
����kafka��Ⱥ����ɲο���Kafka��Ⱥ��������������߰���
��ÿһ̨����������kafka��Ⱥ
���뵽/hadoop/kafka
cd /hadoop/kafka
ָ����������
./bin/kafka-server-start.sh -daemon ./config/server.properties
4.3 ����֮��ͨ��jps�鿴����
ÿ̨�����϶��������½��̣����������ɹ�
Kafka
QuorumPeerMain
��ͼ��
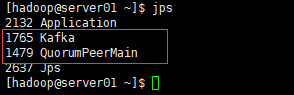
4.4 ����kafka������topic
-. -- -- ,, --- -- --

�塢�����˲���
���������ݶ˽��в��ԣ��Ա�֤ǰ��IJ�����û����ġ�
5.1 ִ��produce_log2.py���������ݽű�
��ÿһ̨������ִ�и�python�ű�
python produce_log2.py
ִ�нű����鿴access.log���ݱ仯
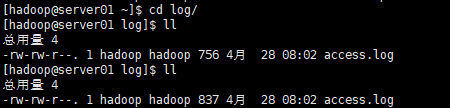
ͨ����ѯ�ȶ����ݴ�С��access.log�ļ��Dz����������ݵ�
5.2 ����flume�����ݲɼ�����
��ÿһ̨������ִ��flume�IJɼ�����
# ����/hadoop/flumeĿ¼
cd /hadoop/flume
# ִ��flume�IJɼ�����
bin/flume-ng agent -c conf -f conf/flume-sink-kafka.conf -name a1 -Dflume.root.logger=INFO,console
5.3 ��server01�����ϣ�ִ��kafka-console-consumer.sh����Թ۲�kafka���ݵ�һ�����
.--. -- ,, --- --
�����ͼ��
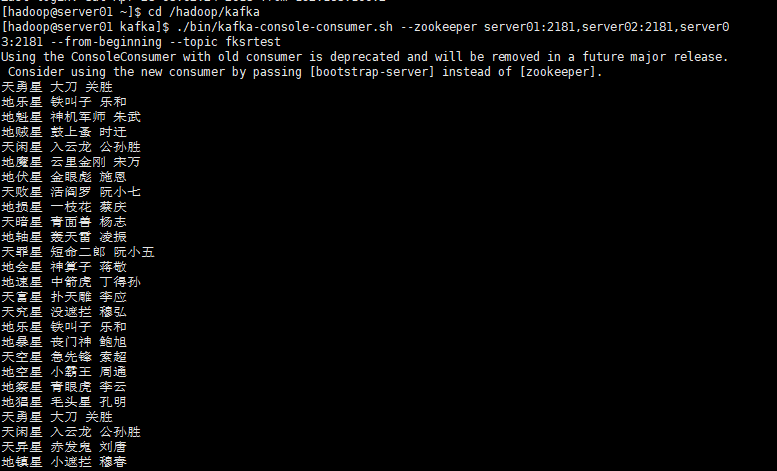
����ĩβ���ڲ�ͣ��д�����ݵ������
���ϲ��Ա�ʾ�����������˵�ִ�в�����OK�ģ�������������Ҫ������Ѷ˵�ִ�����̡�
������дstorm������
6.1 pom.xml��������
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
6.2 ִ����MyTopology
public class MyTopology {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
BrokerHosts hosts = new ZkHosts("server01:2181,server02:2181,server03:2181");
String topic = "fksrtest";
String zkRoot = "/fksr";
String id = "fksrtest_id";
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
builder.setSpout("spout", new KafkaSpout(spoutConf), 2);
builder.setBolt("bolt1", new Bolt1(), 4).shuffleGrouping("spout");
builder.setBolt("bolt2", new Bolt2(), 2).shuffleGrouping("bolt1");
StormTopology topology = builder.createTopology();
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("fksrwordcount", new Config(), topology);
}
}
6.3 Bolt1��
Bolt1����Ҫ�����з�line���ݳ�word��Ȼ��word,num���ݷ���Bolt2����
public class Bolt1 extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
byte[] bytes = (byte[]) input.getValueByField("bytes");
String line = new String(bytes);
String[] splits = line.split(" ");
for (String word : splits) {
collector.emit(new Values(word, 1));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}
6.4 Bolt2��
Bolt2�࣬��word,num���ݴ�ŵ�һ��map�����У��ٽ�map���ϴ�ŵ�redis������
public class Bolt2 extends BaseBasicBolt {
private Jedis jedis;
private HashMap<String, String> map = new HashMap<String, String>();
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
jedis = new Jedis("server01", 6379);
}
public void execute(Tuple input, BasicOutputCollector collector) {
String word = (String) input.getValueByField("word");
Integer num = (Integer) input.getValueByField("num");
String result = map.get(word);
if (StringUtils.isNotEmpty(result)) {
int res = Integer.parseInt(result);
map.put(word, (num + res) + "");
} else {
map.put(word, num + "");
}
jedis.hmset("fksrtest", map);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
Ϊ�˷�����ԣ�����ֱ��ʹ����storm�ı���ģʽ��
�ߡ�����redis����
��server01����������redis-server
redis-server /usr/local/redis/redis-conf
�ˡ����Ѷ���������
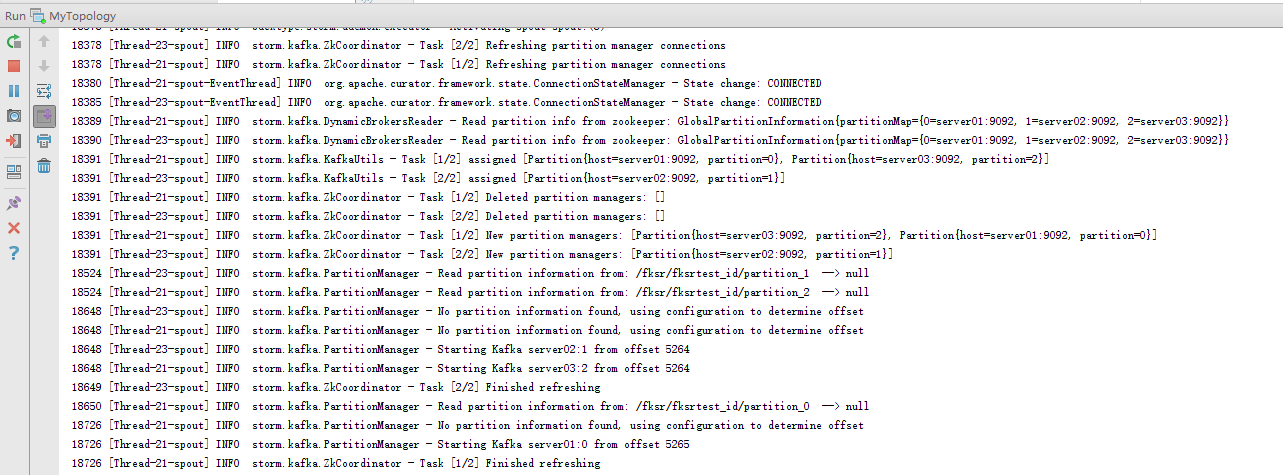
8.1 ����storm�ij���
ֱ������MyTopology��
8.2 ִ��Redis��java���Դ���
public class RedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("server01", 6379);
for (String key : jedis.hkeys("fksrtest")) {
System.out.println(key + ":" + jedis.hmget("fksrtest", key));
}
}
}
���ǿ��Կ���redis�е����ݣ�
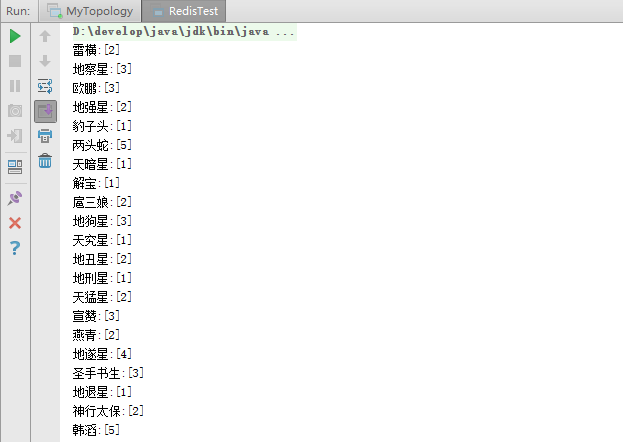
�������ǵ����С�����������