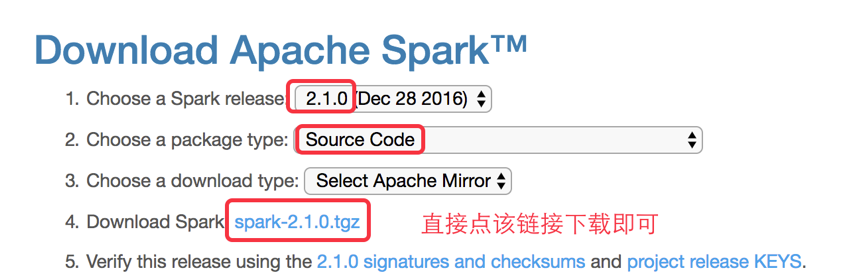
��ЩС�����ܻ��ʣ�Spark���������Ѿ��ṩ��Spark��Բ�ͬ�汾�İ�װ����������Ϊʲô����Ҫ��SparkԴ����б����أ��������������ǵ�Spark����: spark.apache.org�����£�����ͼ��ʾ:
������������Hadoop��ѡ�ͣ��ֶܴ���CDH����HDPϵ�еģ���ô�ٷ��ṩ���⼸��Hadoopϵ���Ƿ��ܹ�����������
�ڿ��������У����Ǿ�����������Ҫ��Spark��Դ������ģ���ô�ĺ�Ĵ�����μ��ɵ�Spark��װ����ȥ�أ�
��������г�������ĸ��˾��ñȽϺõ����ʵ����
�������������е�Hadoop�汾�����Spark�İ�װ��
��SparkԴ��֮�����±���Spark
���ԣ����˾����������õ�ѧϰ��ʹ��Spark����ô��һ������Ҫ�����SparkԴ��������װ����
����Spark�ٷ��ĵ�����ģ��Ľ��ܣ�http://spark.apache.org/docs/2.1.0/building-spark.html ���Ľ��ܣ�
The Maven-based build is the build of reference for Apache Spark. Building Spark using Maven requires Maven 3.3.9 or newer and Java 7+. Note that support for Java 7 is deprecated as of Spark 2.0.0 and may be removed in Spark 2.2.0.��
���ǵ�֪��
Java��Ҫ7+�汾��������Spark2.0.0֮��Java 7�Ѿ�����ʶ��deprecated�ˣ����Dz�Ӱ��ʹ�ã�������Spark2.2.0�汾֮��Java 7��֧�ֽ��ᱻ�Ƴ���
Maven��Ҫ3.3.9+�汾
Java SE��װ�����ص�ַ��https://www.oracle.com/technetwork/ java /java se/downloads/jdk8-downloads-2133151.html
�������е���������װ��hadoop�û��ĸ�Ŀ¼��app�ļ�����
tar - zxvf jdk- XXX. tar. gz - C ~ / app
export JAVA_HOME= / home/ hadoop/ app/ jdkjdk1. 8.0 _181
export PATH= $JAVA_HOME/ bin: $PATH
source ~ / . bash_profile
java - version
java version "jdk1.8.0_181"
Maven3.3.9��װ�����ص�ַ��https://mirrors.tuna.tsinghua.edu.cn/apache//maven/maven-3/3.3.9/binaries/
tar - zxvf apache- maven- 3.3 .9 - bin. tar. gz - C ~ / app/
export MAVEN_HOME= / home/ hadoop/ app/ apache- maven- 3.3 .9
export PATH= $MAVEN_HOME/ bin: $PATH
source ~ / . bash_profile
mvn - v
Apache Maven 3.3 .9 ( bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015 - 11 - 10 T08: 41 : 47 - 08 : 00 )
Maven home: / home/ hadoop/ app/ apache- maven- 3.3 .9
Java version: 1.7 .0 _51, vendor: Oracle Corporation
Java home: / home/ hadoop/ app/ jdk1. 7.0 _51/ jre
Default locale: zh_CN, platform encoding: UTF- 8
OS name: "linux" , version: "2.6.32-358.el6.x86_64" , arch: "amd64" , family: "unix"
���ص�ַ��http://spark.apache.org/downloads.html
�鿴�ٷ��ĵ�����Դ�벿�֣�http://spark.apache.org/docs/2.1.0/building-spark.html#building-a-runnable-distribution
���ǿ���ʹ��SparkԴ��Ŀ¼�е�dev�µ�make-distribution.sh�ű����ٷ��ṩ�ı����������£�
. /dev/ make- distribution. sh -- name custom- spark -- tgz - Psparkr - Phadoop- 2.4 - Phive - Phive- thriftserver - Pmesos - Pyarn
����˵����
�Cname��ָ��������ɺ�Spark��װ��������
�Ctgz����tgz�ķ�ʽ����ѹ��
-Psparkr�����������Spark֧��R����
-Phadoop-2.4����hadoop-2.4��profile���б��룬�����profile���Կ���Դ���Ŀ¼�е�pom.xml�в鿴
-Phive��-Phive-thriftserver�����������Spark֧�ֶ�Hive�IJ���
-Pmesos�����������Spark֧��������Mesos��
-Pyarn�����������Spark֧��������YARN��
��ô���ǿ��Ը��ݾ��������������Spark����������ʹ�õ�Hadoop�汾��2.6.0-cdh5.7.0������������Ҫ��Spark������YARN�ϡ�֧�ֶ�Hive�IJ�������ô���ǵ�SparkԴ�����ű����ǣ�
. /dev/ make- distribution. sh -- name 2.6 .0 - cdh5. 7.0 -- tgz - Pyarn - Phadoop- 2.6 - Phive - Phive- thriftserver - Dhadoop. version= 2.6 .0 - cdh5. 7.0
����ɹ�����SparkԴ��ĸ�Ŀ¼�о�spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz������ô���ǾͿ���ʹ�ñ�������������װ��������Spark�İ�װ�ˡ�
��С�����ܻ��ʣ�Ϊʲô��������İ�װ����������spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz�أ����ǿ��Դ�������ɻ鿴make-distribution.sh��Դ�룬�ڸýű�����֣������´��룺
if [ "$MAKE_TGZ " == "true" ] ; then
TARDIR_NAME= spark-$VERSION -bin-$NAME
TARDIR= "$SPARK_HOME /$TARDIR_NAME "
rm -rf "$TARDIR "
cp -r "$DISTDIR " "$TARDIR "
tar czf "spark-$VERSION -bin-$NAME .tgz" -C "$SPARK_HOME " "$TARDIR_NAME "
rm -rf "$TARDIR "
fi
��VERSION��������Spark�İ汾��2.1.0��NAME���������ڱ���ʱָ����2.6.0-cdh5.7.0�����Ը��ݸýű����������Spark��װ����ȫ��Ϊ: spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz��ͨ���ô���IJ鿴ϣ�����������һ�����⣺Դ����ǰ���������ܡ�
ע�⣺�ڱ�������л��������ij����������ʱ��̫�ã����������������⣬����ִ��ctrl+cֹͣ�������Ȼ���������б�������ڱ�������ж��Լ��μ��ɡ���������С��飬���鿪��VPNȻ���ٽ��б��룬����������̻�˳���ܶࡣ
����õ�spark-2.1.0-bin-2.6.0-cdh5.7.0�汾����Ϊ��https://download.csdn.net/download/bingdianone/10824595
�����������ԣ�https://www.imooc.com/article/18419
��������
./dev/make-distribution.sh \
--name 2.6.0-cdh5.7.0 \
--tgz \
-Pyarn -Phadoop-2.6 \
-Phive -Phive-thriftserver \
-Dhadoop.version= 2.6.0-cdh5.7.0
����ڱ�������У��㿴�����쳣��Ϣ����̫����/����̫��
����һ
Failed to execute goal on project spark- launcher_2. 11 :
Could not resolve dependencies for project org. apache. spark: spark- launcher_2. 11 : jar: 2.1 .0 :
Could not find artifact org. apache. hadoop: hadoop- client: jar: 2.6 .0 - cdh5. 7.0
in central ( https: / / repo1. maven. org/ maven2) - > [ Help 1 ]
����һ�����pom.xml���ӣ�
< repository> < id> </ id> < url> </ url> </ repository> �����
export MAVEN_OPTS= "-Xmx2g -XX:ReservedCodeCacheSize=512m -XX:MaxPermSize=512M"
ע��㣺
[ info] Java HotSpot ( TM) 64 - Bit Server VM warning: INFO: os: : commit_memory ( 0x00000000e8f84000 , 18800640 , 0 ) failed; error= '�������ڴ�' ( errno= 12 )
[ info] #
[ info] # There is insufficient memory for the Java Runtime Environment to continue .
[ info] # Native memory allocation ( malloc) failed to allocate 18800640 bytes for committing reserved memory.
[ info] # An error report file with more information is saved as:
[ info] # / home/ hadoop/ source/ spark- 2.1 .0 / hs_err_pid4764. log
������
����������scala�汾��2.10
./dev/change-scala-version.sh 2.11
������
was cached in the local repository,
resolution will not be reattempted until the update interval of nexus has elapsed or updates are forced
1�� ȥ�ֿ�� xxx.lastUpdated�ļ�ȫ��ɾ��������ִ��maven����
ֱ�ӽ�ѹspark-2.1.0-bin-2.6.0-cdh5.7.0.tgz
Spark Standaloneģʽ�ļܹ���Hadoop HDFS/YARN�����Ƶ�
�� /spark-env.sh
hadoop1 : master
slaves:
==> start-all.sh ���� hadoop1����������master���̣���slaves�ļ����õ�����hostname�Ļ���������worker����
Spark WordCountͳ��
val file = spark. sparkContext. textFile ( "file:///home/hadoop/data/wc.txt" )
val wordCounts = file. flatMap ( line = > line. split ( "," ) ) . map ( ( word = > ( word, 1 ) ) ) . reduceByKey ( _ + _)
wordCounts. collect