ǰ��
��������Windows ��Linux ����ϵͳ������Spark ����������˼·һ�£�����Eclipse ��Idea��ͨ��Java��Scala ��Python ���Խ��п�������װ֮ǰ��Ҫ��ǰ����JDK��Scala ��Python ������Ȼ����Eclipse �����ذ�װScala ��Python ���(Spark֧��Java��Python������)�������������£�
������һ������װJDK
�����ڶ�������װScala
����������������Spark��������
�������IJ�����װHadoop���߰�
�������岽����װEclipse
��������������װEclipse Scala IDE���
��һ������װJDK��
������1������JDK(1.7���ϰ汾)
�������� ���ص�ַ��http://www.oracle.com/technetwork/java/javase/downloads/index.html
������2�����û�������(��WindowsΪ��)
����JAVA_HOME ������ֵ��C:\Program Files\Java\jdk1.7.0_71
����CLASSPATH ������ֵ��.;%JAVA_HOME%\lib
����PATH ���������䣺;%JAVA_HOME%\bin
����cmd �������JDK �Ƿ�װ�ɹ���
C:\Users\admin>java -version
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b14)
�ڶ�������װScala
������1������Scala(���� Scala ��)
�������� ���ص�ַ(Scala ��ҳ)��http://www.scala-lang.org/download/(Scala 2.9.3�汾����ֱ�ӵ���õ�ַ���أ�Scala 2.9.3���غ�ֱ�ӵ����װ����)
������2��������ɺ��ѹ������PATH ����
�������� �����ѹĿ¼��C:\Program Files (x86)\scala��Ȼ��C:\Program Files (x86)\scala\bin;���ӵ���������path��
����cmd �������Scala �Ƿ�װ�ɹ�:
C:\Users\admin>scala
Welcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_7
Type :help for more information.
������������Spark��������
������1������Spark
�������� ���ص�ַ��http://spark.apache.org/downloads.html
�������� ������ӦHadoop��Ӧ�İ汾������spark-1.6.2-bin-hadoop2.6.tgz��spark�汾��1.6.2����Ӧ��hadoop�汾��2.6
������2��������ɺ��ѹ������Spark�Ļ�������(��WindowsΪ��)
����SPARK_HOME ������ֵ��C:\Apache Spark\spark-1.6.2-bin-hadoop2.6
����SPARK_CLASSPATH ������ֵ��;C:\Apache Spark\spark-1.6.2-bin-hadoop2.6\lib\spark-assembly-1.6.2-hadoop2.6.0.jar;
����PATH���������䣺;C:\Apache Spark\spark-1.6.2-bin-hadoop2.6\bin
���IJ�����װHadoop���߰�
����Spark�ǻ���Hadoop֮�ϵģ����й����л�������Hadoop�⣬���û�������Hadoop���л���������ʾ��س�����Ϣ����ȻҲ��Ӱ�����С�Windows�¿���Spark����Ҫ�ڱ��ذ�װHadoop��������Ҫwinutils.exe��hadoop.dll���ļ���
������1������Windows��Hadoop���߰�����Ϊ32λ��64λ�ģ�������hadoop-2.6.0.tar.gz
�������� ���ص�ַ��https://github.com/sdravida/hadoop2.6_Win_x64/tree/master/bin
����������https://www.barik.net/archive/2015/01/19/172716/
������2��������ɺ��ѹ������Hadoop�Ļ�������(��WindowsΪ��)
�������� �ڱ����½�һ��hadoopĿ¼�����б��������binĿ¼�����硰D:\spark\hadoop-2.6.0\bin����Ȼ��winutil���ļ�����binĿ¼��
�������� ����ؿ����ӵ�ϵͳPath�����У�D:\hadoop-2.6.0\bin��ͬʱ�½�HADOOP_HOME����������ֵΪ��D:\hadoop-2.6.0
���岽����װEclipse
�����ڹ�������Eclipse����ѹ�������غ�ֱ��ʹ�ü��ɡ�
����������װEclipse Scala IDE���
������1������Eclipse Scala IDE���
�������� ���ص�ַ��Scala IDE(for Scala 2.9.x and Eclipse Juno)
�������� ����������http://www.scala-lang.org/download/2.7.6.final.html
������2����װScala ���
�������� 1.��Eclipse Scala IDE�����features��plugins����Ŀ¼�µ������ļ�������Eclipse��ѹ������Ӧ��Ŀ¼�С�
�������� 2.��������Eclipse�����Eclipse���ϽǷ���ť������ͼ��ʾ��չ��������Other��.�����鿴�Ƿ��С�Scala��һ��������ֱ�ӵ�������������һ��������
�������� 3.��Eclipse�У�����ѡ��Help�� �C> ��Install New Software�������ڵ����ĶԻ���������http://download.scala-ide.org/sdk/e38/scala29/stable/site�������س������ɿ����������ݣ�ѡ��Scala IDE
for Eclipse ��Scala IDE for Eclipse development support �������Scala �����Eclipse�ϵİ�װ(������һ���Ѿ���jar��������Eclipse�У���װ�ܿ죬ֻ����ͨһ��)��
�������� ��װ����ٲ���һ�鲽��2��ɡ�
ʹ��Java���Խ���Spark��������
1.�½�java����
2.��Spark�����������spark-assembly-1.6.2-hadoop2.6.0.jar�����ӵ������У���Ϊ����������
ʹ��Java���Խ���Spark StandaloneģʽӦ�ó���
1. ����Maven Project������ѡ��File->New->Other->Maven Project

2. ��дJavaԴ����
/* SimpleApp.java */
import org.apache.spark.api.java.*;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///spark-bin-0.9.1/README.md";
SparkConf conf =new SparkConf().setAppName("Spark Application in Java");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs +",lines with b: " + numBs);
}
}
3.��pom.xml����������
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.cas.siat.dolphin</groupId>
<artifactId>spark.SimpleApp</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spark.SimpleApp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
</project>
4. ������
�ֱ�ִ��Maven clean��Maven install�������ڹ�����Ŀ�µ�targetĿ¼�л�������Ŀ��jar��������ͼ��

5.����SparkӦ��
�ϴ�����õ�jar����spark��Ⱥclient��ִ�������������г���
./spark-submit --class "foo.App" --master spark://172.21.5.235:7077 /home/hadoop121/Dolphin/Spark1.0.2/spark.SimpleApp-0.0.1-SNAPSHOT.jar
6.ִ�н��

��Web UI������£�



�spark maven��Ŀ����
��һ���������Լ���spark maven��Ŀ����ѡcreate a simple project

�ڶ�������ͼ������Packaging��maven���ɵİ�������Ҫѡ��jar����Ϊspark����һ���Ǵ��Ϊjar����

������������spark��jar�����ղ��½���maven��Ŀ��build path�У��ҵ���Ⱥ��װ��spark��װĿ¼����libĿ¼�»ῴ��jar��
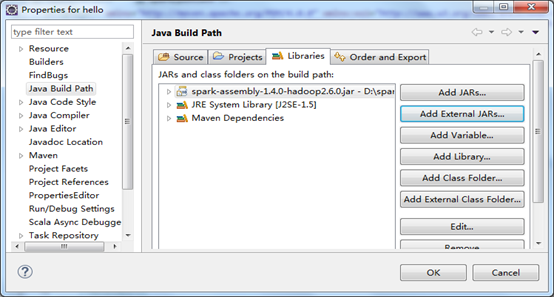
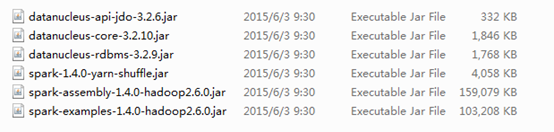
���IJ���pom�������Լ���spark��hadoop maven���������磺
 View Code
View Code���岿��spark����������main���������˿��Ա�д������벢���к͵���
View Code
��

{kind=link}
{kind=link}