版权声明: https://blog.csdn.net/u013063153/article/details/53117041
Spark是基于内存计算的大数据分布式计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
1.提供分布式计算功能,将分布式存储的数据读入,同时将任务分发到各个节点进行计算;
2.基于内存计算,将磁盘数据读入内存,将计算的中间结果保存在内存,这样可以很好的进行迭代运算;
3.支持高容错;
4.提供多计算范式;
2009年:诞生于AMPLab
2010年:开源
2013年6月:Apache孵化器项目
2014年2月:Apache顶级项目
now:contributor >450人
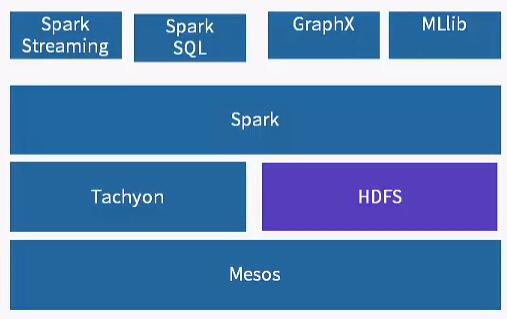
BDAS生态系统
-Mesos(相当于Hadoop生态系统中的YARN),资源管理、任务调度;
-HDFS
-Tachyon:分布式内存文件系统,缓存数据并进行快速的读写;
-Spark:核心计算引擎,能够将任务并行化,在集群中进行大规模并行运算;
-Spark Streaming:流式计算引擎;
-Sprak SQL:SQL on Hadoop,能够提供交互式查询和报表查询,通过JDBC等接口调用;
-GraphX:图计算引擎;
-MLlib:机器学习库。
Spark优势:
1.多计算范式支持
打造全栈多计算范式的高效数据流水线
2.处理速度
轻量级快速处理
3.易用性
易于使用,分布式RDD抽象,Spark支持多种语言
4.兼容性
与HDFS等存储层兼容
5.社区活跃度
#### Spark