��Ȩ����������Ϊ����ԭ�����£���ӭת�غͽ�����ת����ע����Դ^^ https://blog.csdn.net/u013468917/article/details/51249711
����������spark�Ĺٷ��ĵ���������������ӵ�ʱ��������һЩ���⣬���֮���¼�������spark streaming��wordcount���ӵ��������й��̡�����spark streaming��һ�γ�����ɡ�
Spark streaming��һ����ɢ���������ݴ������ߣ������ݰ���ʱ�䴰���зֳ�һ����RDDȻ���ٴ��������Ժ�����������¼��storm�������ӳ��Դ���һЩ����Ҫ�����ӳٵ����ݴ���ҵ���У�spark streaming�ı��ֻ��Dz����ġ�
����֮��������⣺
�����Ǵ���һ��ʵʱ��wordcount���������TCP���ֵ����ݷ�������ȡ�ı����ݣ�Ȼ������ı��а����ĵ���������������spark-shell��ʵ�ֵģ�������д������Ӧ�ó�������в�ͬ���ڱ�д����֮ǰ����Ҫ������Netcat��Ϊ���ݷ������������������master�ڵ������������
nc �Clk 9999
���н�����£�
��ʱ�������һ�������������Ȼ����spark-shell������ :paste �س���ð��ҲҪ���룬����ճ��ģʽ��

Ȼ������Ĵ��븴�ƹ�ȥ��
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("master", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
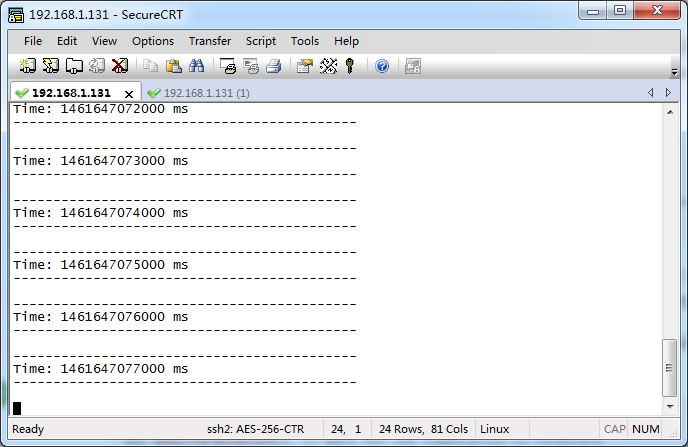
����ctrl+Dִ����δ��롣��ʱ��ϴ�ӡ�����������ÿ1s��ӡһ�Σ�
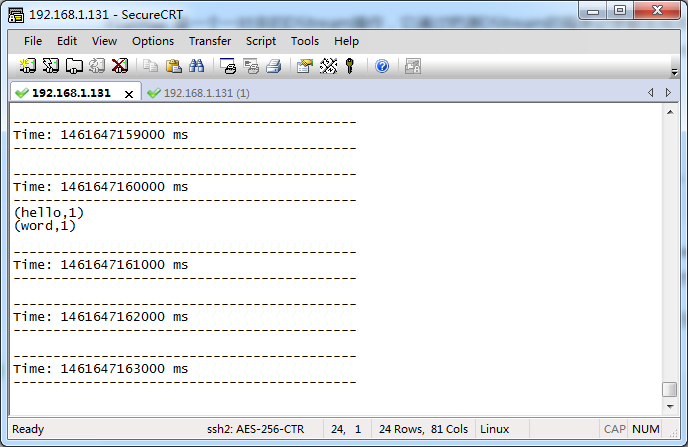
��ʱ�����ڵڶ����ն�����hello word���س���

�������½����˵�����Գɹ���
�������һ����δ��룺
������Ĵ����У��������ȵ�����ص��ࡣȻ��һ��StreamingContext�����������������sparkcontext����spark��������������Ҫ��ڡ�
����Ҫע��һ�㣬�ٷ��ĵ��е�ssc������ʽ�������ģ�
val conf = newSparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = newStreamingContext(conf, Seconds(1))
�����ڶ���Ӧ���еĴ�����ʽ�������spark-shell���������ᱨ�쳣����Ϊ��spark-shell��Ĭ�ϸ����Ǵ�������һ��sparkcontext����sc�����������ַ�ʽ���൱���ִ�����һ��������sparkcontext�����������˳�ͻ����Ϊ��һ��������ֻ����һ��sparkcontext��
����Second(1)��ʾ����������1s�����з֡����������ӵ�ַ���˿ڡ�����Խ��κ�һ����װ��netcat�Ļ�����Ϊ����IJ������ݷ�������ֻ��Ҫ��д��Ӧ�ĵ�ַ���˿ھͿ����ˡ�
���lines������һ��DStream����ʾ���������ݷ�������õ������ݡ����DStream��ÿ����¼������һ���ı�����һ����������Ҫ��DStream�е�ÿ���ı����з�Ϊ���ʡ�
flatMap��һ��һ�Զ��DStream��������ͨ����ԴDStream��ÿ����¼�����ɶ����¼�¼������һ���µ�DStream������������У�ÿ���ı������зֳ��˶�����ʣ����ǰ��зֵĵ�������words���DStream��ʾ��
words���DStream��mapper(һ��һת������)����һ���µ�DStream�����ɣ�word��1������ɡ�Ȼ�����ǾͿ���������µ�DStream����ÿ�����ݵĴ�Ƶ�����������wordCounts.print()��ӡÿ�����Ĵ�Ƶ��
��Ҫע����ǣ���������Щ���뱻ִ��ʱ��SparkStreaming������������Ҫִ�еļ��㣬ʵ���ϲ�û��������ʼִ�С�����Щת����������֮��Ҫ����ִ�м��㣬��Ҫ�������µķ�����
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate