版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32426313/article/details/77871878
Spark 配置
1、master机器
Spark 配置
进入 Spark 安装目录下的 conf 目录, 拷贝spark-env.sh.template 到spark-env.sh。
cp spark-env.sh.template spark-env.sh
编辑spark-env.sh,在其中添加以下配置信息:
export SCALA_HOME=/opt/scala-2.11.8
export JAVA_HOME=/opt/java/jdk1.7.0_80
export SPARK_MASTER_IP=192.168.109.137
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop-2.6.4/etc/hadoop
JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
将slaves.template 拷贝到 slaves, 编辑其内容为:
即 master 既是 Master 节点又是 Worker 节点。
2、slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
启动 Spark 集群
1、启动 Hadoop 集群
此处不再详细介绍,可以参考hadoop集群搭建
2、启动 Spark 集群
(1) 启动 Master 节点
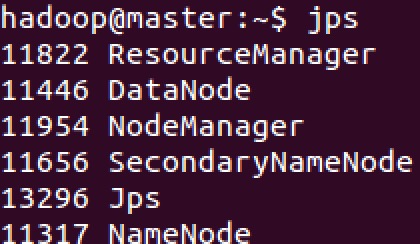
运行 start-master.sh,结果如下:
可以看到 master 上多了一个新进程 Master。

(2) 启动所有 Worker 节点
运行 start-slaves.sh, 运行结果如下:

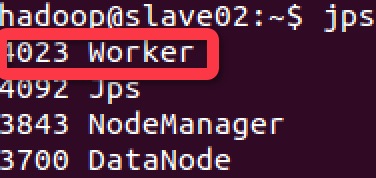
在 master、slave01 和 slave02 上使用 jps 命令,可以发现都启动了一个 Worker 进程


(3) 浏览器查看 Spark 集群信息。
地址 master:8080
3、停止 Spark 集群
1、停止 Master 节点
运行 stop-master.sh 来停止 Master 节点。

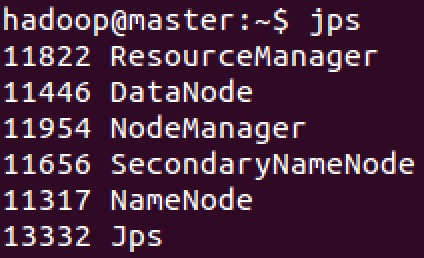
使用 jps 命令查看当前 java 进程
可以发现 Master 进程已经停止。

2、停止 Worker 节点
运行 stop-slaves.sh 可以停止所有的 Worker 节点

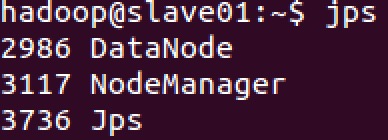
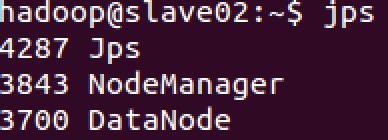
使用 jps 命令查看 master、slave01、slave02 上的进程信息:
可以看到, Worker 进程均已停止,最后再停止 Hadoop 集群。


import logging
import time
from operator import add
from pyspark import SparkContext,SparkConf
conf=SparkConf()
conf.setMaster("spark://ckx:7077")
conf.setAppName("test application7")
test_file_name = "hdfs://ckx:9000/user/hadoop/test/kk.txt"
out_file_name = "hdfs://ckx:9000/user/hadoop/spark-out9"
starttime=time.time()
# Word Count
sc=SparkContext(conf=conf)
# text_file rdd object
text_file = sc.textFile(test_file_name)
# counts
counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile(out_file_name)
endtime=time.time()
print(endtime-starttime)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}