| TOP | ||||||||||
|
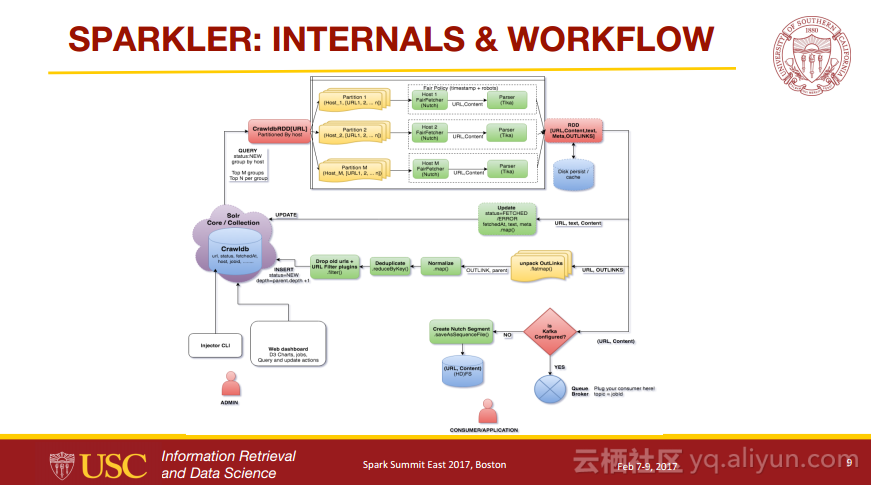
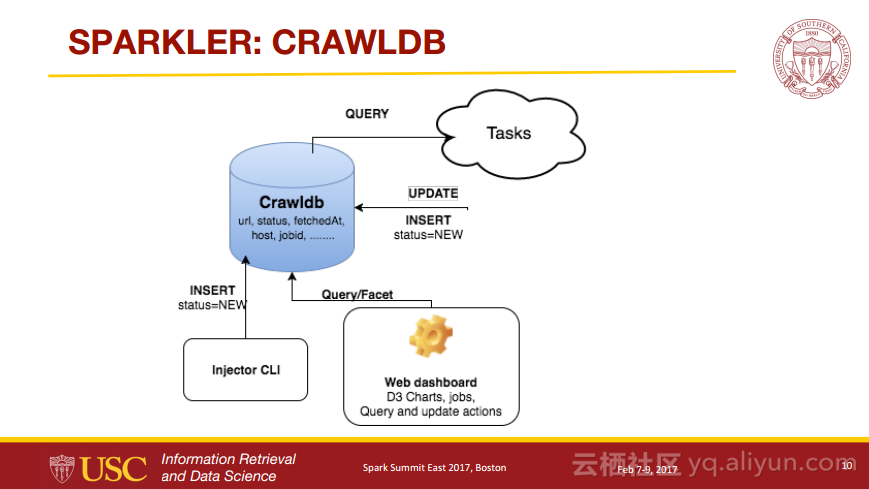
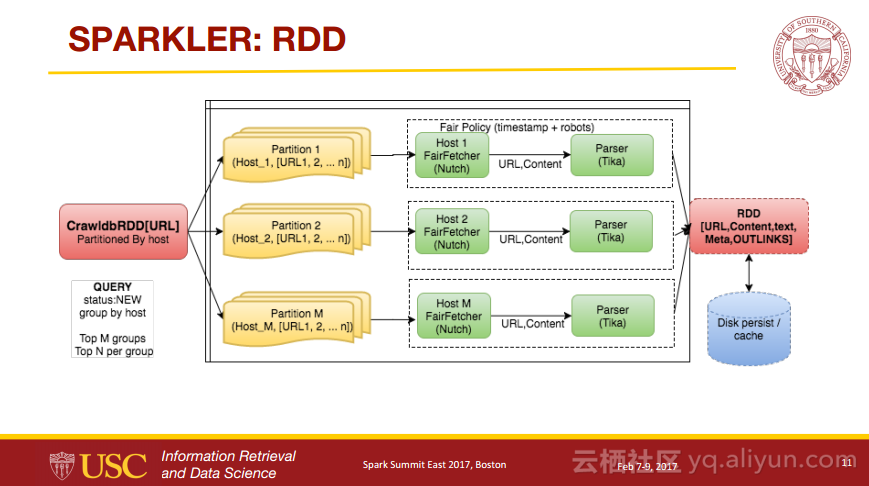
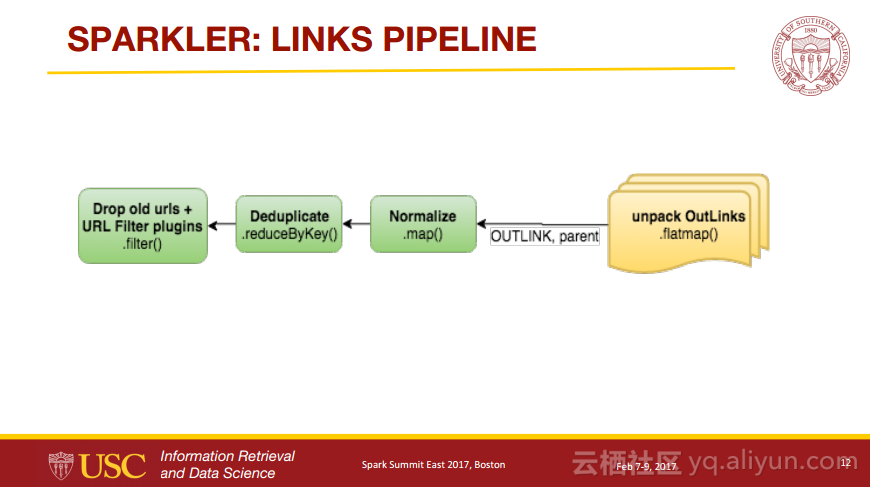
Sparkler:Spark上的爬虫
|
||||||||||





















| 最新文章 |
| 热门文章 |
| Hot 文章 |
| Python | ||||||||||
|
||||||||||
| C 语言 | ||||||||||
|
||||||||||
| C++基础 | ||||||||||
|
||||||||||
| 大数据基础 | ||||||||||
|
||||||||||
| linux编程基础 | ||||||||||
|
||||||||||
| C/C++面试题目 | ||||||||||
|
||||||||||
| 设为首页 加入收藏 |
|
当前位置: |
| TOP | ||||||||||
|
Sparkler:Spark上的爬虫
|
||||||||||
| 最新文章 |
| 热门文章 |
| Hot 文章 |
| Python | ||||||||||
|
||||||||||
| C 语言 | ||||||||||
|
||||||||||
| C++基础 | ||||||||||
|
||||||||||
| 大数据基础 | ||||||||||
|
||||||||||
| linux编程基础 | ||||||||||
|
||||||||||
| C/C++面试题目 | ||||||||||
|
||||||||||