突然有个想法,R只能处理百万级别的数据,如果R能运行在spark上多好!搜了下发现13年SparkR这个项目就启动了,感谢美帝!
1.你肯定得先装个spark吧。看这:Spark本地模式与Spark
Standalone伪分布模式
2.你肯定得会R吧。看这:R语言入门
3.启动SparkR就可以了
3.1启动于本地(单机)
Spark also provides an experimentalR APIsince 1.4 (only DataFrames APIs
included).To run Spark interactively in a R interpreter, usebin/sparkR:
./bin/sparkR --master local[2]
-
guo@drguo:/opt/spark-1.6.1-bin-hadoop2.6$./bin/sparkR#这样直接运行默认在本地运行,相当于sparkR--masterlocal[2]
-
Rversion3.2.3(2015-12-10)--"WoodenChristmas-Tree"
-
Copyright(C)2015TheRFoundationforStatisticalComputing
-
Platform:x86_64-pc-linux-gnu(64-bit)
-
-
R是自由软件,不带任何担保。
-
在某些条件下你可以将其自由散布。
-
用'license()'或'licence()'来看散布的详细条件。
-
-
R是个合作计划,有许多人为之做出了贡献.
-
用'contributors()'来看合作者的详细情况
-
用'citation()'会告诉你如何在出版物中正确地引用R或R程序包。
-
-
用'demo()'来看一些示范程序,用'help()'来阅读在线帮助文件,或
-
用'help.start()'通过HTML浏览器来看帮助文件。
-
用'q()'退出R.
-
-
Launchingjavawithspark-submitcommand/opt/spark-1.6.1-bin-hadoop2.6/bin/spark-submit"sparkr-shell"/tmp/RtmpmkEgRV/backend_port21583a90cfc4
-
16/05/1203:30:35WARNNativeCodeLoader:Unabletoloadnative-hadooplibraryforyourplatform...usingbuiltin-javaclasseswhereapplicable
-
-
Welcometo
-
______
-
/__/__________//__
-
_\\/_\/_`/__/'_/
-
/___/.__/\_,_/_//_/\_\version1.6.1
-
/_/
-
-
-
Sparkcontextisavailableassc,SQLcontextisavailableassqlContext
3.2启动于Spark Standalone集群,别忘了先启动集群。
-
guo@drguo:/opt/spark-1.6.1-bin-hadoop2.6$bin/sparkR--masterspark://drguo:7077
-
-
Launchingjavawithspark-submitcommand/opt/spark-1.6.1-bin-hadoop2.6/bin/spark-submit"--master""spark://drguo:7077""sparkr-shell"/tmp/RtmpXmU5lQ/backend_port23516636af0a
-
16/05/1211:08:26WARNNativeCodeLoader:Unabletoloadnative-hadooplibraryforyourplatform...usingbuiltin-javaclasseswhereapplicable
-
-
Welcometo
-
______
-
/__/__________//__
-
_\\/_\/_`/__/'_/
-
/___/.__/\_,_/_//_/\_\version1.6.1
-
/_/
-
-
-
Sparkcontextisavailableassc,SQLcontextisavailableassqlContext
3.3启动于yarn,别忘了先启动yarn和hdfs
-
guo@drguo:/opt/spark-1.6.1-bin-hadoop2.6$bin/sparkR--masteryarn-client
-
-
Launchingjavawithspark-submitcommand/opt/spark-1.6.1-bin-hadoop2.6/bin/spark-submit"--master""yarn-client""sparkr-shell"/tmp/RtmpxF2KAi/backend_port174572d34cd0
-
16/05/1210:54:46WARNNativeCodeLoader:Unabletoloadnative-hadooplibraryforyourplatform...usingbuiltin-javaclasseswhereapplicable
-
-
Welcometo
-
______
-
/__/__________//__
-
_\\/_\/_`/__/'_/
-
/___/.__/\_,_/_//_/\_\version1.6.1
-
/_/
-
-
-
Sparkcontextisavailableassc,SQLcontextisavailableassqlContext
4.随便用一下
-
#读入本地数据框
-
>localDF<-data.frame(name=c("John","Smith","Sarah"),age=c(19,23,18))
-
>localDF
-
nameage
-
1John19
-
2Smith23
-
3Sarah18
-
>df<-createDataFrame(sqlContext,localDF)
-
>printSchema(df)
-
root
-
|--name:string(nullable=true)
-
|--age:double(nullable=true)
-
#从本地文件读入
-
>peopleDF<-read.df(sqlContext,"people.json","json")
-
>peopleDF
-
DataFrame[age:bigint,name:string]
-
>head(peopleDF)
-
agename
-
1NAMichael
-
230Andy
-
319Justin
-
>peopleC<-collect(peopleDF)
-
>print(peopleC)
-
agename
-
1NAMichael
-
230Andy
-
319Justin
-
>printSchema(peopleDF)
-
root
-
|--age:long(nullable=true)
-
|--name:string(nullable=true)
-
>registerTempTable(peopleDF,"people")
-
#执行sql语句
-
>teenagers<-sql(sqlContext,"SELECTnameFROMpeopleWHEREage>=13ANDage<=19")
-
>teenagersLocalDF<-collect(teenagers)
-
>head(teenagersLocalDF)
-
name
-
1Justin
-
>teenagers
-
DataFrame[name:string]
-
>print(teenagersLocalDF)
-
name
-
1Justin
-
#还可以用hivesql呢!
-
>hiveContext<-sparkRHive.init(sc)
-
16/05/1213:16:18WARNConnection:BoneCPspecifiedbutnotpresentinCLASSPATH(oroneofdependencies)
-
16/05/1213:16:18WARNConnection:BoneCPspecifiedbutnotpresentinCLASSPATH(oroneofdependencies)
-
16/05/1213:16:25WARNObjectStore:Versioninformationnotfoundinmetastore.hive.metastore.schema.verificationisnotenabledsorecordingtheschemaversion1.2.0
-
16/05/1213:16:25WARNObjectStore:Failedtogetdatabasedefault,returningNoSuchObjectException
-
16/05/1213:16:28WARNConnection:BoneCPspecifiedbutnotpresentinCLASSPATH(oroneofdependencies)
-
16/05/1213:16:29WARNConnection:BoneCPspecifiedbutnotpresentinCLASSPATH(oroneofdependencies)
-
>sql(hiveContext,"CREATETABLEIFNOTEXISTSsrc(keyINT,valueSTRING)")
-
DataFrame[result:string]
-
>sql(hiveContext,"LOADDATALOCALINPATH'examples/src/main/resources/kv1.txt'INTOTABLEsrc")
-
DataFrame[result:string]
-
>results<-sql(hiveContext,"FROMsrcSELECTkey,value")
-
>head(results)
-
keyvalue
-
1238val_238
-
286val_86
-
3311val_311
-
427val_27
-
5165val_165
-
6409val_409
-
>print(results)
-
DataFrame[key:int,value:string]
-
>print(collect(results))
-
keyvalue
-
1238val_238
-
286val_86
-
3311val_311
更多操作请看官方文档:https://spark.apache.org/docs/latest/sparkr.html
看一下drguo:4040,有了八个已完成的job

再看一下最后一个job的详细信息

-
>getwd()
-
[1]"/opt/spark-1.6.1-bin-hadoop2.6"
-
>setwd("/home/guo/RWorkSpaces")
-
>getwd()
-
[1]"/home/guo/RWorkSpaces"
-
>x<-c(1,1,2,2,3,3,3)
-
>y<-c("女","男","女","男","女","男","女")
-
>z<-c(80,85,92,76,61,95,88)
-
>student<-data.frame(class=x,sex=y,score=z)
-
>student
-
classsexscore
-
11女80
-
21男85
-
32女92
-
42男76
-
53女61
-
63男95
-
73女88
-
>row.names(student)<-c("凤姐","波多","杰伦","毕老爷","波","杰","毕老")#改变行名
-
>student
-
classsexscore
-
凤姐1女80
-
波多1男85
-
杰伦2女92
-
毕老爷2男76
-
波3女61
-
杰3男95
-
毕老3女88
-
>student$score
-
[1]80859276619588
-
>student[,3]
-
[1]80859276619588
-
>student[,score]
-
Errorin`[.data.frame`(student,,score):找不到对象'score'
-
>student[,"score"]
-
[1]80859276619588
-
>student[["score"]]
-
[1]80859276619588
-
>student[[3]]
-
[1]80859276619588
-
>student[1:2,1:3]
-
classsexscore
-
凤姐1女80
-
波多1男85
-
>student[student$score>80,]
-
classsexscore
-
波多1男85
-
杰伦2女92
-
杰3男95
-
毕老3女88
-
>attach(student)
-
>student[score>80,]
-
classsexscore
-
波多1男85
-
杰伦2女92
-
杰3男95
-
毕老3女88
5.提交R程序
-
guo@drguo:/opt/spark-1.6.1-bin-hadoop2.6$./bin/spark-submitexamples/src/main/r/dataframe.R
dataframe.R
-
library(SparkR)
-
-
#InitializeSparkContextandSQLContext
-
sc<-sparkR.init(appName="SparkR-DataFrame-example")
-
sqlContext<-sparkRSQL.init(sc)
-
-
#Createasimplelocaldata.frame
-
localDF<-data.frame(name=c("John","Smith","Sarah"),age=c(19,23,18))
-
-
#ConvertlocaldataframetoaSparkRDataFrame
-
df<-createDataFrame(sqlContext,localDF)
-
-
#Printitsschema
-
printSchema(df)
-
#root
-
#|--name:string(nullable=true)
-
#|--age:double(nullable=true)
-
-
#CreateaDataFramefromaJSONfile
-
path<-file.path(Sys.getenv("SPARK_HOME"),"examples/src/main/resources/people.json")
-
peopleDF<-read.json(sqlContext,path)
-
printSchema(peopleDF)
-
-
#RegisterthisDataFrameasatable.
-
registerTempTable(peopleDF,"people")
-
-
#SQLstatementscanberunbyusingthesqlmethodsprovidedbysqlContext
-
teenagers<-sql(sqlContext,"SELECTnameFROMpeopleWHEREage>=13ANDage<=19")
-
-
#Callcollecttogetalocaldata.frame
-
teenagersLocalDF<-collect(teenagers)
-
-
#Printtheteenagersinourdataset
-
print(teenagersLocalDF)
-
-
#StoptheSparkContextnow
-
sparkR.stop()
官方文档:https://spark.apache.org/docs/latest/api/R/index.html
https://spark.apache.org/docs/latest/sparkr.html
下面转自:http://mt.sohu.com/20151023/n424011438.shtml作者:孙锐,英特尔大数据团队工程师,HIVE和Shark项目贡献者,SparkR主力贡献者之一。
R和Spark的强强结合应运而生。2013年9月SparkR作为一个独立项目启动于加州大学伯克利分校的大名鼎鼎的AMPLAB实验室,与Spark源出同门。2014年1月,SparkR项目在github上开源(https://github.com/amplab-extras/SparkR-pkg)。随后,来自工业界的Alteryx、Databricks、Intel等公司和来自学术界的普渡大学,以及其它开发者积极参与到开发中来,最终在2015年4月成功地合并进Spark代码库的主干分支,并在Spark 1.4版本中作为重要的新特性之一正式宣布。
当前特性SparkR往Spark中增加了R语言API和运行时支持。Spark的 API由Spark Core的API以及各个内置的高层组件(Spark Streaming,Spark SQL,ML Pipelines和MLlib,Graphx)的API组成,目前SparkR只提供了Spark的两组API的R语言封装,即Spark Core的RDD API和Spark SQL的DataFrame API。
需要指出的是,在Spark 1.4版本中,SparkR的RDD API被隐藏起来没有开放,主要是出于两点考虑:
RDD API虽然灵活,但比较底层,R用户可能更习惯于使用更高层的API;
RDD API的实现上目前不够健壮,可能会影响用户体验,比如每个分区的数据必须能全部装入到内存中的限制,对包含复杂数据类型的RDD的处理可能会存在问题等。
目前社区正在讨论是否开放RDD API的部分子集,以及如何在RDD API的基础上构建一个更符合R用户习惯的高层API。
RDD API用户使用SparkR RDD API在R中创建RDD,并在RDD上执行各种操作。
目前SparkR RDD实现了Scala RDD API中的大部分方法,可以满足大多数情况下的使用需求:
SparkR支持的创建RDD的方式有:
从R list或vector创建RDD(parallelize())
从文本文件创建RDD(textFile())
从object文件载入RDD(objectFile())
SparkR支持的RDD的操作有:
数据缓存,持久化控制:cache(),persist(),unpersist()
数据保存:saveAsTextFile(),saveAsObjectFile()
常用的数据转换操作,如map(),flatMap(),mapPartitions()等
数据分组、聚合操作,如partitionBy(),groupByKey(),reduceByKey()等
RDD间join操作,如join(), fullOuterJoin(), leftOuterJoin()等
排序操作,如sortBy(), sortByKey(), top()等
Zip操作,如zip(), zipWithIndex(), zipWithUniqueId()
重分区操作,如coalesce(), repartition()
其它杂项方法
和Scala RDD API相比,SparkR RDD API有一些适合R的特点:
SparkR RDD中存储的元素是R的数据类型。
SparkR RDD transformation操作应用的是R函数。
RDD是一组分布式存储的元素,而R是用list来表示一组元素的有序集合,因此SparkR将RDD整体上视为一个分布式的list。Scala API 中RDD的每个分区的数据由iterator来表示和访问,而在SparkR RDD中,每个分区的数据用一个list来表示,应用到分区的转换操作,如mapPartitions(),接收到的分区数据是一个list而不是iterator。
为了符合R用户经常使用lapply()对一个list中的每一个元素应用某个指定的函数的习惯,SparkR在RDD类上提供了SparkR专有的transformation方法:lapply()、lapplyPartition()、lapplyPartitionsWithIndex(),分别对应于Scala API的map()、mapPartitions()、mapPartitionsWithIndex()。
DataFrame APISpark 1.3版本引入了DataFrame API。相较于RDD API,DataFrame API更受社区的推崇,这是因为:
DataFrame的执行过程由Catalyst优化器在内部进行智能的优化,比如过滤器下推,表达式直接生成字节码。
基于Spark SQL的外部数据源(external data sources) API访问(装载,保存)广泛的第三方数据源。
使用R或Python的DataFrame API能获得和Scala近乎相同的性能。而使用R或Python的RDD API的性能比起Scala RDD API来有较大的性能差距。
Spark的DataFrame API是从R的 Data Frame数据类型和Python的pandas库借鉴而来,因而对于R用户而言,SparkR的DataFrame API是很自然的。更重要的是,SparkR DataFrame API性能和Scala DataFrame API几乎相同,所以推荐尽量用SparkR DataFrame来编程。
目前SparkR的DataFrame API已经比较完善,支持的创建DataFrame的方式有:
从R原生data.frame和list创建
从SparkR RDD创建
从特定的数据源(JSON和Parquet格式的文件)创建
从通用的数据源创建
将指定位置的数据源保存为外部SQL表,并返回相应的DataFrame
从Spark SQL表创建
从一个SQL查询的结果创建
支持的主要的DataFrame操作有:
・数据缓存,持久化控制:cache(),persist(),unpersist()
数据保存:saveAsParquetFile(), saveDF() (将DataFrame的内容保存到一个数据源),saveAsTable() (将DataFrame的内容保存存为数据源的一张表)
集合运算:unionAll(),intersect(), except()
Join操作:join(),支持inner、full outer、left/right outer和semi join。
数据过滤:filter(), where()
排序:sortDF(), orderBy()
列操作:增加列- withColumn(),列名更改- withColumnRenamed(),选择若干列 -select()、selectExpr()。为了更符合R用户的习惯,SparkR还支持用$、[]、[[]]操作符选择列,可以用$<列名> <- 的语法来增加、修改和删除列
RDD map类操作:lapply()/map(),flatMap(),lapplyPartition()/mapPartitions(),foreach(),foreachPartition()
数据聚合:groupBy(),agg()
转换为RDD:toRDD(),toJSON()
转换为表:registerTempTable(),insertInto()
取部分数据:limit(),take(),first(),head()
编程示例总体上看,SparkR程序和Spark程序结构很相似。
基于RDD API的示例
要基于RDD API编写SparkR程序,首先调用sparkR.init()函数来创建SparkContext。然后用SparkContext作为参数,调用parallelize()或者textFile()来创建RDD。有了RDD对象之后,就可以对它们进行各种transformation和action操作。下面的代码是用SparkR编写的Word Count示例:
library(SparkR) #初始化SparkContext sc <- sparkR.init("local", "RWordCount") #从HDFS上的一个文本文件创建RDD lines <- textFile(sc, "hdfs://localhost:9000/my_text_file") #调用RDD的transformation和action方法来计算word count #transformation用的函数是R代码 words <- flatMap(lines, function(line)
{ strsplit(line, " ")[[1]] }) wordCount <- lapply(words, function(word) { list(word, 1L) }) counts <- reduceByKey(wordCount, "+", 2L) output <- collect(counts)
基于DataFrame API的示例
基于DataFrame API的SparkR程序首先创建SparkContext,然后创建SQLContext,用SQLContext来创建DataFrame,再操作DataFrame里的数据。下面是用SparkR DataFrame API计算平均年龄的示例:library(SparkR) #初始化SparkContext和SQLContext sc <- sparkR.init("local", "AverageAge") sqlCtx <- sparkRSQL.init(sc) #从当前目录的一个JSON文件创建DataFrame
df <- jsonFile(sqlCtx, "person.json") #调用DataFrame的操作来计算平均年龄 df2 <- agg(df, age="avg") averageAge <- collect(df2)[1, 1]
对于上面两个示例要注意的一点是SparkR RDD和DataFrame API的调用形式和Java/Scala API有些不同。假设rdd为一个RDD对象,在Java/Scala API中,调用rdd的map()方法的形式为:rdd.map(…),而在SparkR中,调用的形式为:map(rdd, …)。这是因为SparkR使用了R的S4对象系统来实现RDD和DataFrame类。
架构SparkR主要由两部分组成:SparkR包和JVM后端。SparkR包是一个R扩展包,安装到R中之后,在R的运行时环境里提供了RDD和DataFrame API。
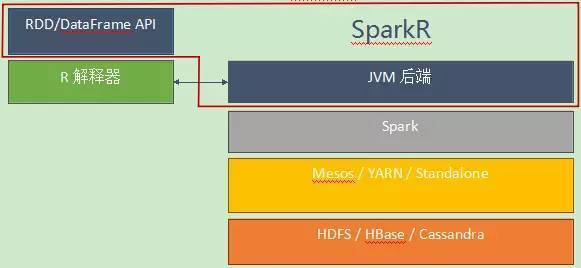
图1 SparkR软件栈
SparkR的整体架构如图2所示。
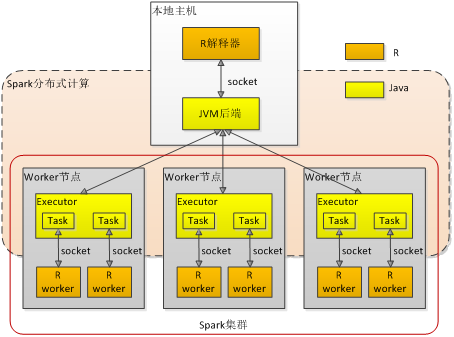
图2 SparkR架构
R JVM后端SparkR API运行在R解释器中,而Spark Core运行在JVM中,因此必须有一种机制能让SparkR API调用Spark Core的服务。R JVM后端是Spark Core中的一个组件,提供了R解释器和JVM虚拟机之间的桥接功能,能够让R代码创建Java类的实例、调用Java对象的实例方法或者Java类的静态方法。JVM后端基于Netty实现,和R解释器之间用TCP socket连接,用自定义的简单高效的二进制协议通信。
R Worker
SparkR RDD API和Scala RDD API相比有两大不同:SparkR RDD是R对象的分布式数据集,SparkR RDD transformation操作应用的是R函数。SparkR RDD API的执行依赖于Spark Core但运行在JVM上的Spark Core既无法识别R对象的类型和格式,又不能执行R的函数,因此如何在Spark的分布式计算核心的基础上实现SparkR RDD API是SparkR架构设计的关键。
SparkR设计了Scala RRDD类,除了从数据源创建的SparkR RDD外,每个SparkR RDD对象概念上在JVM端有一个对应的RRDD对象。RRDD派生自RDD类,改写了RDD的compute()方法,在执行时会启动一个R worker进程,通过socket连接将父RDD的分区数据、序列化后的R函数以及其它信息传给R worker进程。R worker进程反序列化接收到的分区数据和R函数,将R函数应到到分区数据上,再把结果数据序列化成字节数组传回JVM端。
从这里可以看出,与Scala RDD API相比,SparkR RDD API的实现多了几项开销:启动R worker进程,将分区数据传给R worker和R worker将结果返回,分区数据的序列化和反序列化。这也是SparkR RDD API相比Scala RDD API有较大性能差距的原因。
DataFrame API的实现
由于SparkR DataFrame API不需要传入R语言的函数(UDF()方法和RDD相关方法除外),而且DataFrame中的数据全部是以JVM的数据类型存储,所以和SparkR RDD API的实现相比,SparkR DataFrame API的实现简单很多。R端的DataFrame对象就是对应的JVM端DataFrame对象的wrapper,一个DataFrame方法的实现基本上就是简单地调用JVM端DataFrame的相应方法。这种情况下,R Worker就不需要了。这是使用SparkR DataFrame
API能获得和ScalaAPI近乎相同的性能的原因。
当然,DataFrame API还包含了一些RDD API,这些RDD API方法的实现是先将DataFrame转换成RDD,然后调用RDD 的相关方法。
展望SparkR目前来说还不是非常成熟,一方面RDD API在对复杂的R数据类型的支持、稳定性和性能方面还有较大的提升空间,另一方面DataFrame API在功能完备性上还有一些缺失,比如对用R代码编写UDF的支持、序列化/反序列化对嵌套类型的支持,这些问题相信会在后续的开发中得到改善和解决。如何让DataFrame API对熟悉R原生Data Frame和流行的R package如dplyr的用户更友好是一个有意思的方向。此外,下一步的开发计划包含几个大的特性,比如普渡大学正在做的在SparkR中支持Spark
Streaming,还有Databricks正在做的在SparkR中支持ML pipeline等。SparkR已经成为Spark的一部分,相信社区中会有越来越多的人关注并使用SparkR,也会有更多的开发者参与对SparkR的贡献,其功能和使用性将会越来越强。
总结Spark将正式支持R API对熟悉R语言的数据科学家是一个福音,他们可以在R中无缝地使用RDD和Data Frame API,借助Spark内存计算、统一软件栈上支持多种计算模型的优势,高效地进行分布式数据计算和分析,解决大规模数据集带来的挑战。工欲善其事,必先利其器,SparkR必将成为数据科学家在大数据时代的又一门新利器。